Any questions related to AWS EC2 can be posted here.
NB: This platform seems to be broken since Nov 11 or so (updated Nov. 17).
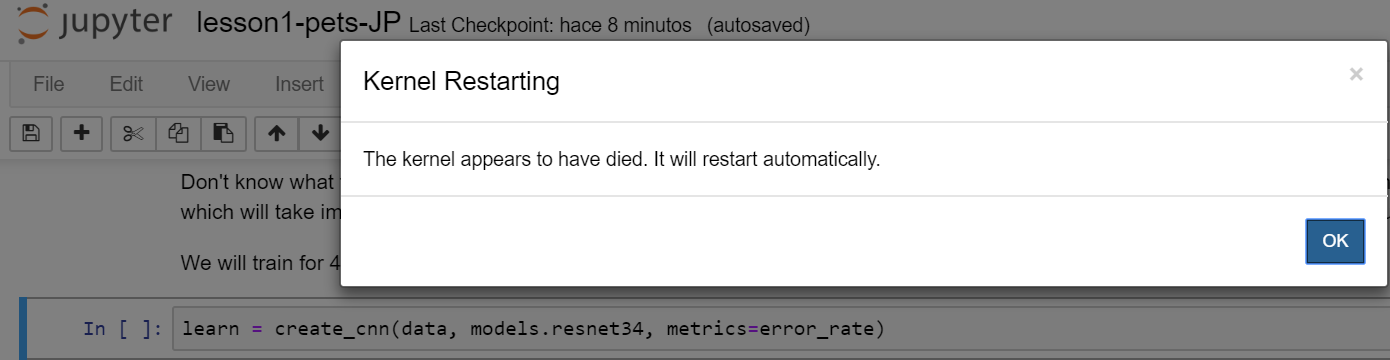
Problem seems to be some broken dependency in fastai’s create_cnn(). Reverting pytorch to v1.0.0 may fix the problem. Alternatively, William Horton made / posted an alternative AMI as a workaround.
Note that this is a forum wiki thread, so you all can edit this post to add/change/organize info to help make it better! To edit, click on the little pencil icon at the bottom of this post. Here’s a pic of what to look for:
My EC2, set up according according to the instructions, worked fine for the first three weeks, and now every time I try to run a create_cnn cell it crashes, with the error “Kernal restarting. The kernel appears to have died. It will restart automatically.” This occurs irrespective of which notebook I’m running–even lesson 1 dog breed classification fails. I tried creating a new instance from scratch, and the same thing happened. I conda updatedd everything, and git pulled the course content. I even tried running a fresh Ubuntu AMI (instead of the deep learning AMI), and I got that to work, but it didn’t have the CUDA drivers installed, so training the CNN was too slow to be useful. I’m currently thinking it may have to do with not having enough disk space free. Anyone else running into similar problems?
I just created a brand new instance, exactly according to the course instructions, and tried the very first cat/dog breed classification. It too kills the kernel every time it gets to create_cnn. I’m going to switch to Sagemaker so I can at least do some work in the meantime, but still very curious to hear anyone’s thoughts on how to debug this.
Have been facing the exact same issue this evening.
Like you, followed the instructions to a T. Tried Ubuntu Deep Learning AMI ver 16 and ver 17. Tried Python 3.6 and Python 3.7. Didn’t matter. Hadn’t thought about disk space being a possible cause.
I thought it could be a cause because I actually ran completely out of disk space, but I freed up 30 gigs and that didn’t fix it. Would love to get one of the fastai devs to try this out and see if it’s a PyTorch issue. Any idea how to ping them?
I’m not sure but there may be a fastai v1.0.x issues topic; probably not inside the Part 1 v3 category for our current course. If you had been using create_cnn on AWS for the past couple of weeks with no issues, then it would seem like it may be more likely a torch nightly/vision nightly/fastai library issue since conceivably those would have been the only things that woulda changed.
Like you, I’m gonna try out Sagemaker or something. Since it seems like virtually no one is using AWS, I’m not sure how optimistic I am that there’ll be a critical mass of other folks who also hit this wall.
@dhananjay014, @astronomy88, have you had similar problems, or is AWS working for you? If it is working, have you updated the fastai, torch, torchvision libraries recently?
Issue still persists. I tried on my local computer with CPU version. Its running fine as of now (but as expected very very slow)… did not try updating pytorch in case it breaks things here too
Hi @jeremy, the EC2 platform seems to be broken for FastAI, since about Nov. 11. I tried it with DLAMI versions 16 and 17, with nightly builds of all the packages. Any time create_cnn is invoked, the kernel immediately dies. It looks like other folks have been having the same issue. Any thoughts on how we can get help to fix this?
Just wanted to chime in and say that I’m also having this issue. I followed the AWS setup instructions to a tee (only difference being that I used a previous .pem file but I can’t imagine that matters) on two separate boxes and I’m still having the issue. I have the suggested p2.xlarge box, and I run into the error when calling create_cnn, both on my own notebook and the lesson1-pets notebook. Because the kernel kept restarting I decided to put all the code into a .py file and run it that way. I was still met with an error, this time the error was Illegal instruction (core dumped). I found online that this error happened to some people when they import the Tensorflow package. I know that we are not doing that, but I wonder if both PyTorch and Tensorflow have some dependency that we are not satisfying.