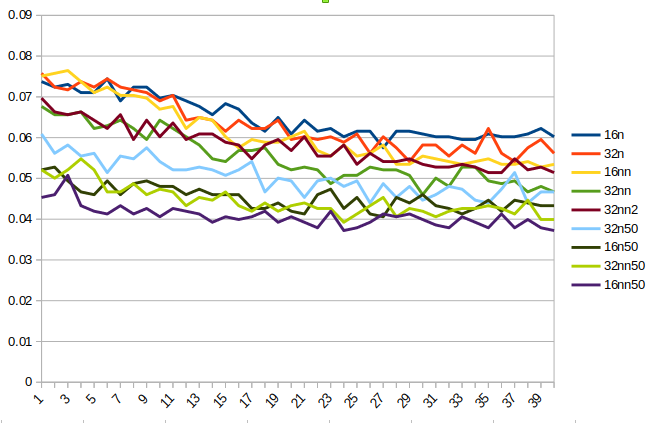
I’ve been using the pets model as my sandbox, and trying various options to compare fp16 and fp32 on my 2080. My latest test is to compare with and without “.normalize(imagenet_stats)”
I do three frozen epochs (fit_one_cycle(3, max_lr=slice(1e-3))) then unfreeze and run forty epochs with a teeny learning rate (fit_one_cycle(40, max_lr=slice(1e-7,1e-5))). Resnet34, BS 64, SZ 256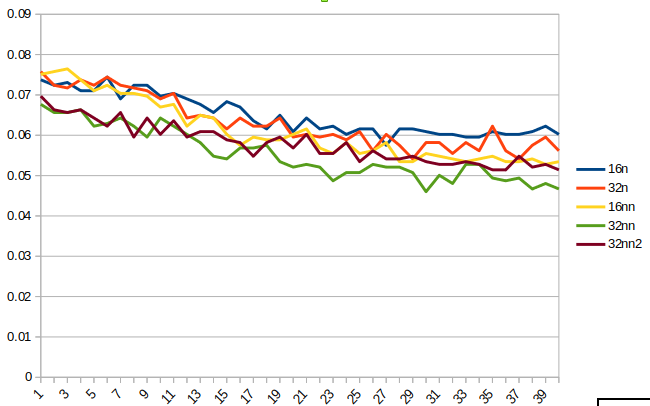
Perhaps because I am starting with a well-trained model, the tests without normalization have not blown up, and appear to consistently beat the normalized tests.
From the chart, you can see that fp16 models tend to flatten out around 30 epochs, while the fp32 models are still jumping around. The best is fp32 with no normalization (nn). This is well ahead of the others even after the frozen epochs. I ran that model a second time (32nn2), and while the results were not as good, they were still better than the other options. I ran more epochs and 32nn2 reached .045 after another 25. At that point, train loss was .197 and valid loss was .167.
I have tried various SZ and BS, as well as RN50 variations, but the results have consistently favored fp32 and no normalization. I’m currently rerunning RN50 variations from scratch and will post another chart in a few hours.