Actually have not yet put that on github. Will do it now!
Thanks for that - the xdriveclient worked well.
Now my next issue:
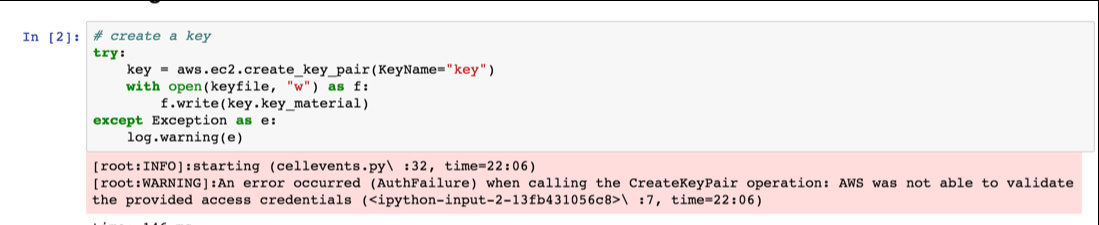
I added a new user and credentials, then verified that I could create a key using the fast_ai script - and it worked well.
Not sure why I’m getting the above? Any ideas?
Thanks for feeding that back. Forgot to convert the windows path backslashes into forward slashes in xdriveclient.py. Have uploaded corrected version of xclientdrive.py on github.
There is a requirement of python 3.6 because of the string interpolation which I didn’t know was a new feature. Very cool. https://www.python.org/dev/peps/pep-0498/
Just want to add a huge thank you to @simoneva for helping me 1-to-1.
It’s great to use Docker and save a fortune with spot instances.
Thanks James for your feedback and helping to get the persistent spot instances working in an environment other than mine.
Key learning for anyone else starting to use docker containers:
- Originally I had a container but also multiple volume links outside the container to config files, data files and notebooks. This was sometimes convenient but makes everything less portable and harder to debug. Whilst it worked on my laptop it might not elsewhere.
- A better approach is to put everything possible inside the container. Of course there may be exceptions such as GPU drivers but basically I now have almost everything in the one container which should work on any target computer
It is amazing that using docker you can run stuff on Windows and then run it on Apple with no changes at all!
Hi @simoneva,
I’m trying to use your xdrive environment, and something appears not quite right. It worked fine the first time around - I was able to connect to the iPython notebook running in the model, and properly train models using the GPU.
Now, I am trying to use it again, and I see some errors. I requested a new spot instance:
server.create("centos-gpu", itype="gpu", spot=True, drive="fastai")
```
which succeeded, and I am able to ssh into the machine. However, when I attempt to use `apps.run_fastai()`, I receive the following error:
```
[34.251.50.240] run: nvidia-docker run -v /v1:/v1 -w /fastai/deeplearning1/nbs -p 8888:8888 -d --name fastai simonm3/fastai
[34.251.50.240] out: docker: Error response from daemon: Conflict. The name "/fastai" is already in use by container 81f43b33dcf9ad7d89284e6c1dc5df0380ba25b6f9194c2c39a6d93a7c8b4730. You have to remove (or rename) that container to be able to reuse that name..
```
Which sounded reasonable, so I attempted to use `apps.start_fastai()`, but then I received a different error:
```
[34.251.50.240] run: docker start fastai
[34.251.50.240] out: Error response from daemon: get nvidia_driver_352.99: no such volume: nvidia_driver_352.99
[34.251.50.240] out: Error: failed to start containers: fastai
```
Any idea what I'm doing wrong? Did I mangle the setup somehow?
Thank you!First error is as you correctly deduce that you are trying to “run” existing container. This is how docker responds when you try and run an existing container…though actually I don’t think it is very friendly and I am am constantly doing this so maybe I could take different approach.
Second error I also used to get but not recently. What is happening is that it is looking for the driver and can’t find it. This should not happen.
- Did you run fastai on a CPU then a GPU. This won’t work. It can only be ported between GPUs
- check on server ps -aux | grep nvidia. Does this show nvidia-docker-plugin running?
- is nvidia-docker-plugin running with -d /v1/var/lib/nvidia-docker/volumes?
- does the path /v1/var/lib/nvidia-docker/volumes exist?
I am guessing you originally created the container with previous version in which case if you do this and try start_fastai() again then it will work:
recreates the drivers
nvidia-docker run nvidia/cuda:7.5 nvidia-smi
copies drivers to /v1
cp -r --parents /var/lib/nvidia-docker/volumes /v1
///////////////////////////////////
p.s. you may need to start a new instance then do the above.
You’re right, this fixed it. Although I’ve been using the same version all long. Here are the steps I took (all in the same local iPython notebook, without any version changes):
- Create a server, call it
server.create("centos-gpu", itype="gpu", spot=True, drive="fastai"). - Connect to it using
apps.run_fastai(). - Work on it for about half an hour.
- Terminate it using
server.terminate("centos-gpu") - Wait for it to terminate successfully, seeing the snapshot in my EC2 console.
- Create a new server, with a new name,
server.create("centos-gpu2", itype="gpu", spot=True, drive="fastai") - Attempt to connect using
apps.start_fastai()- fail with the error above. - Connect and run the two commands you suggested -
nvidia-docker run nvidia/cuda:7.5 nvidia-smiandcp -r --parents /var/lib/nvidia-docker/volumes /v1 - Everything runs fine again, and I can access my previous work in the docker image.
The question is - what am I doing wrong, that prevents this form properly occurring during setup? Is it the server name change? Maybe an old version of xdrive? Am I doing something wrong?
Thanks @simoneva !
I think you may have an old version as this was a bug I resolved previously. However now you have the files in the right place it should work fine on future runs. Though suggest you upgrade to latest. I can say for the last couple of weeks I have used many GPU spot instances via xdrive and not had any issues at all. I do recognise that one from a while back and I know where it came from.
Docker containers are supposed to be hardware independent so there is an issue with how to enable them to use specific GPU hardware. The solution is “nvidia-docker run” which is a wrapper around “docker run” which sets up a volume link to the GPU when you run the container; and also tells all the subsequent docker commands to query the nvidia-docker-plugin to find the location of the volume files. The plugin takes a -d parameter to specify where the volume link is stored.
When you initially run your first container using xdrive the plugin points at the boot drive; and the volume files are coped to /v1. When you later start the container or run another container the plugin points at /v1.
I recall the issue was about timing of when these files were created; and that they had to be created on the boot drive and then moved.
Authentication issues: - fix
I found a solution to an issue I encountered, which others may come across using a Docker.
My computer went on standby whilst running the above script.
When returning, I found I was getting authentication issues. I tried changing my credentials, creating new keys, everything.
After a serious amount of googling, it turned out the clock on the local container was stuck at the time the computer went on standby.
To fix this, running the following on my computer worked:
docker run -it --rm --privileged --pid=host debian nsenter -t 1 -m -u -n -i date -u $(date -u +%m%d%H%M%Y)
@simoneva indeed, it was a versioning bug. I think that for some reason, attempting to install xdrive through anaconda (using pip) with Python 3.x didn’t get me the most recent version. To verify that was it, I cloned it form git, and put it in the same folder as the example notebook. Worked smoothly then.
To make sure you get the latest then pip install xdrive --upgrade --no-cache
git source is more up to date but the pypi version is more stable and likely to work!
@simoneva yup, that worked, and is smooth for me now.
@simoneva I used the command above but is getting the error below:
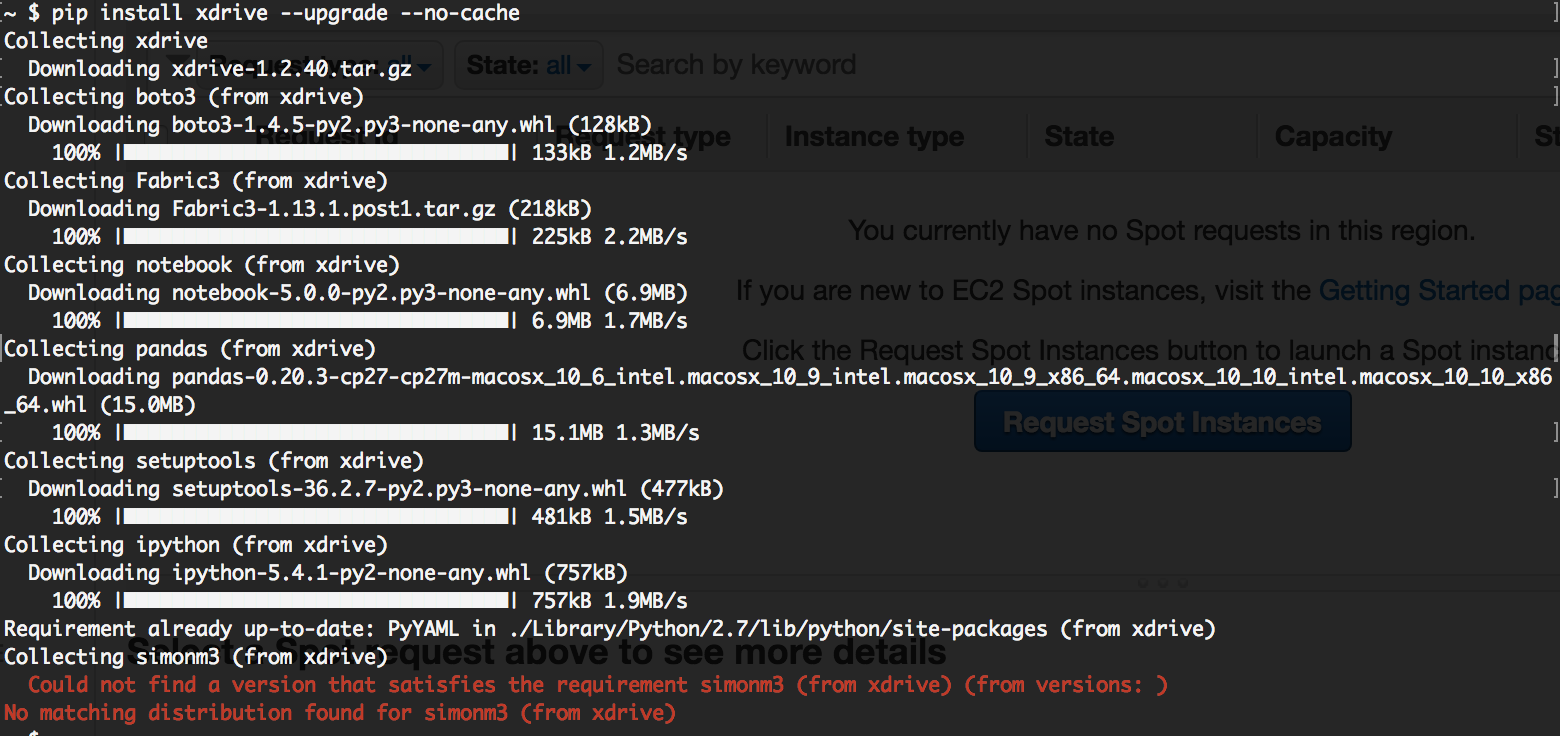
What os and python version? It requires python 3. [probably 3.6]
Got it working after I update to Python 3. Thanks for the reply.
Note also that the docker container uses python3 but the notebooks are the original fastai ones using python2. At the time I just changed what I needed to change as I went along. However someone has helpfully rewritten the notebooks and utility files for python3 and keras2
1 Like