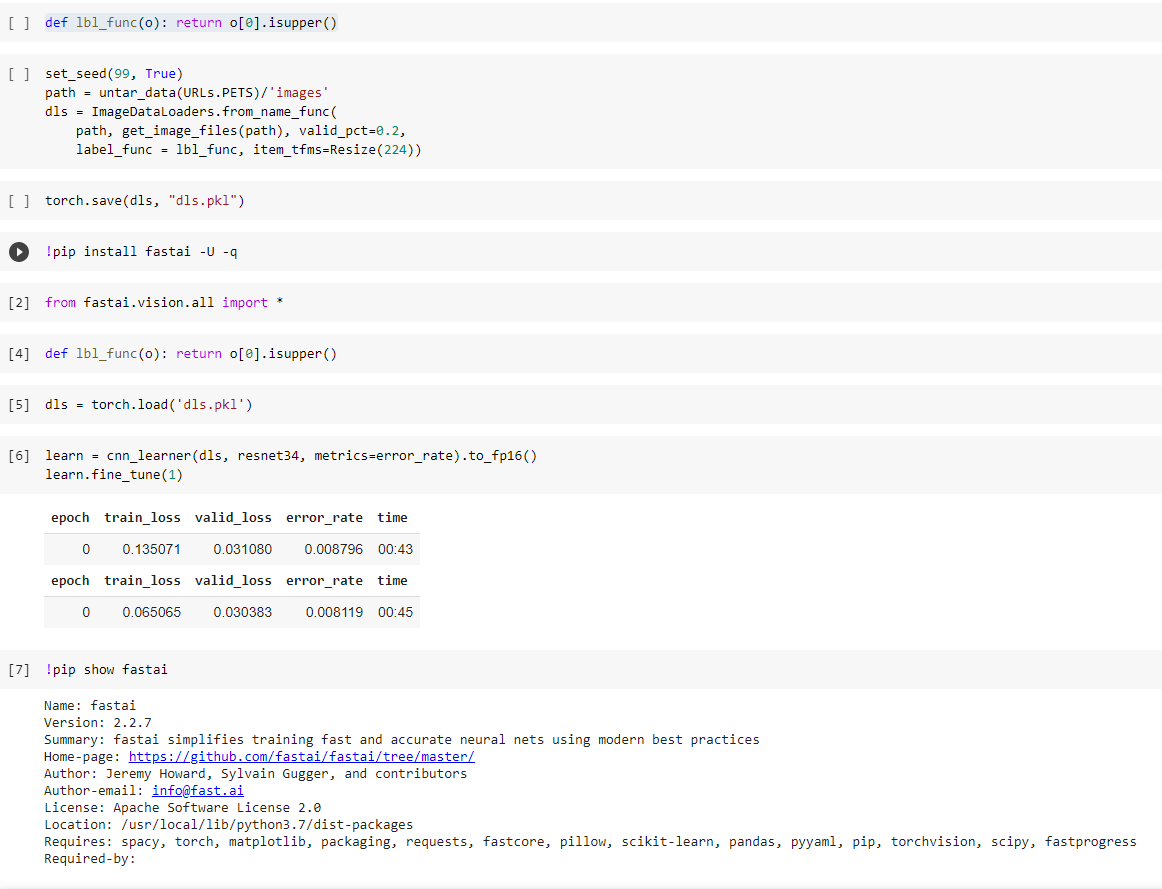
I think I am getting a related error with DataLoaders. I found it when attempting to run fastai/dev_nbs/course/lesson7-resnet-mnist.ipynb.
When I run the notebook to line
dls = dsets.dataloaders(bs=bs, after_item=tfms, after_batch=[IntToFloatTensor, Normalize])
I think this was introduce with fix https://github.com/fastai/fastai/pull/3178
I an getting the following error
AttributeError Traceback (most recent call last)
in
----> 1 dls = dsets.dataloaders(bs=bs, after_item=tfms, after_batch=[IntToFloatTensor, Normalize])
/opt/conda/lib/python3.7/site-packages/fastai/data/core.py in dataloaders(self, bs, shuffle_train, shuffle, val_shuffle, n, path, dl_type, dl_kwargs, device, drop_last, val_bs, **kwargs)
222 dls = [dl] + [dl.new(self.subset(i), **merge(kwargs,def_kwargs,val_kwargs,dl_kwargs[i]))
223 for i in range(1, self.n_subsets)]
–> 224 return self._dbunch_type(*dls, path=path, device=device)
225
226 FilteredBase.train,FilteredBase.valid = add_props(lambda i,x: x.subset(i))
/opt/conda/lib/python3.7/site-packages/fastai/data/core.py in init(self, path, device, *loaders)
142 def init(self, *loaders, path=’.’, device=None):
143 self.loaders,self.path = list(loaders),Path(path)
–> 144 if device is not None or hasattr(loaders[0],‘to’): self.device = device
145
146 def getitem(self, i): return self.loaders[i]
/opt/conda/lib/python3.7/site-packages/fastai/data/core.py in device(self, d)
158 @device.setter
159 def device(self, d):
–> 160 for dl in self.loaders: dl.to(d)
161 self._device = d
162
/opt/conda/lib/python3.7/site-packages/fastai/data/core.py in to(self, device)
122 self.device = device
123 for tfm in self.after_batch.fs:
–> 124 for a in L(getattr(tfm, ‘parameters’, None)): setattr(tfm, a, getattr(tfm, a).to(device))
125 return self
126
AttributeError: ‘NoneType’ object has no attribute ‘to’
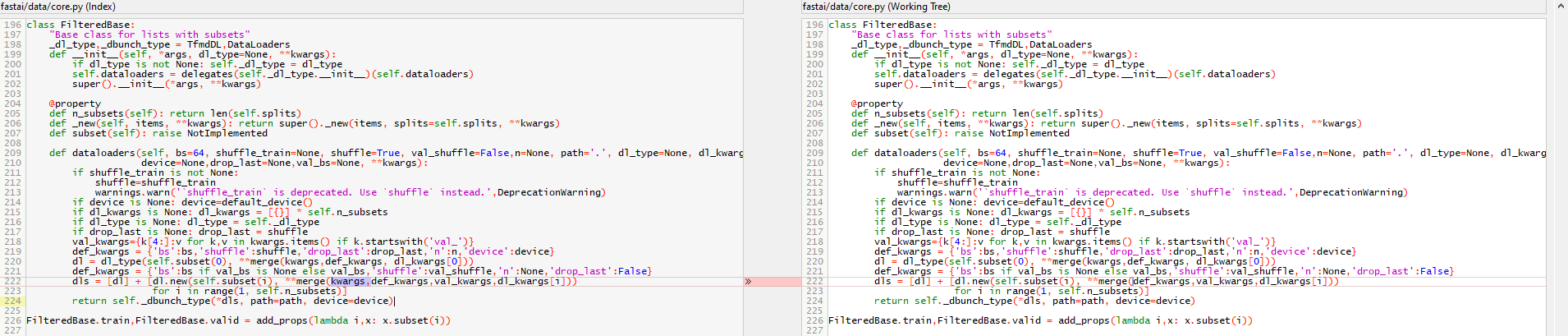
I have been looking at the code and I think it might be the same issue for you too. It seem the addition of kwargs is the problem.
dls = [dl] + [dl.new(self.subset(i), **merge(kwargs,def_kwargs,val_kwargs,dl_kwargs[i]))
If removed from def dataloaders like below
dls = [dl] + [dl.new(self.subset(i), **merge(def_kwargs,val_kwargs,dl_kwargs[i]))
If I am understanding change correctly it will run the
after_batch=[IntToFloatTensor, Normalize] on both, and before it did the first not second.
I am not sure if this is correct to change code like I did.