I found a peculiar issue while loading test data set from ImageClassifierData.from_csv() function. I found that it was loading 1 less test file than available and also, it was random as to which file it was missing. Then I started debugging and found that read_dir function was generating one less file name. I guess it is happening because we are using iglob function to create a generator and then use any() function on it to see if there is any test file or not. The any() function while checking up is also consuming one file from generator and hence, always 1 less test file is loaded in the dataloader. Could you please confirm if my assessment is correct?
@jeremy I have faced the same issue with 2 different datasets/problems that I am working on. One less image loaded from the test folder. Example from the iceberg challenge:
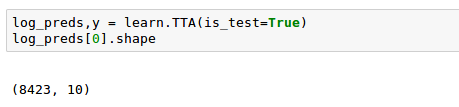
test set for iceberg challenge has 8424 images.
@jeremy I am experiencing the same issue, i.e., missing a test file.
Created a small test2 directory with 4 files , only 3
%time data = ImageClassifierData.from_csv(PATH, ‘train’, f’{PATH}labels.csv’, test_name=‘test2’, val_idxs=val_idxs, suffix=’.jpg’, tfms=tfms, bs=bs)
print(len(data.test_ds)) #how many images were given in the test set and how many loaded?
for f in range(len(data.test_ds)): print(data.test_ds.fnames[f])
!ls “data/dogsbreeds/test2/” | head
CPU times: user 140 ms, sys: 4 ms, total: 144 ms
Wall time: 142 ms
3
test2/fffbff22c1f51e3dc80c4bf04089545b.jpg
test2/fff7d50d848e8014ac1e9172dc6762a3.jpg
test2/fff74b59b758bbbf13a5793182a9bbe4.jpg
fff1ec9e6e413275984966f745a313b0.jpg
fff74b59b758bbbf13a5793182a9bbe4.jpg
fff7d50d848e8014ac1e9172dc6762a3.jpg
fffbff22c1f51e3dc80c4bf04089545b.jpg
I got exactly the same problem while trying to do the dogbreed challenge from lesson2.
If you run the code of read_dir within the notebook (not the function but the code of the function) there is no problem.
The documentation of iglob says this:
Return an iterator which yields the same values as glob() without actually storing them all simultaneously
I tried to change iglob with glob (in the read_dir function of the fastai/dataset.py) and it seems to solve the problem. I didn’t get any memory problem with this dataset this could mayber happen with larger ones.