UPDATE 3/30: Updated thread title to better reflect the general discussion of how we can redefine our anchor boxes with appropriate SSD head architecture changes and vice versa
Hi,
I encountered this runtime error when changing the number of anchor boxes in the pascal-multi notebook - both in the first section where we test out 16 (4*4) anchor boxes and also in the More Anchors! section where we used 189 anchor boxes ((16+4+1)*9).
For example, in the 1st part, if I change to anc_grid=2, when running ssd_loss(batch, y, True) later on, I get this error:
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-50-0b3e91fc3fa0> in <module>()
----> 1 ssd_loss(batch, y, True)
<ipython-input-45-49cfc27062ce> in ssd_loss(pred, targ, print_it)
36 lcs,lls = 0.,0.
37 for b_c,b_bb,bbox,clas in zip(*pred,*targ):
---> 38 loc_loss,clas_loss = ssd_1_loss(b_c,b_bb,bbox,clas,print_it)
39 lls += loc_loss
40 lcs += clas_loss
<ipython-input-45-49cfc27062ce> in ssd_1_loss(b_c, b_bb, bbox, clas, print_it, use_ab)
21 def ssd_1_loss(b_c,b_bb,bbox,clas,print_it=False, use_ab=True):
22 bbox,clas = get_y(bbox,clas)
---> 23 a_ic = actn_to_bb(b_bb, anchors)
24 overlaps = jaccard(bbox.data, (anchor_cnr if use_ab else a_ic).data)
25 gt_overlap,gt_idx = map_to_ground_truth(overlaps,print_it)
<ipython-input-45-49cfc27062ce> in actn_to_bb(actn, anchors)
6 def actn_to_bb(actn, anchors):
7 actn_bbs = torch.tanh(actn)
----> 8 actn_centers = (actn_bbs[:,:2]/2 * grid_sizes) + anchors[:,:2]
9 actn_hw = (actn_bbs[:,2:]/2+1) * anchors[:,2:]
10 return hw2corners(actn_centers, actn_hw)
RuntimeError: The size of tensor a (16) must match the size of tensor b (4) at non-singleton dimension 0
The error message describes a mismatch between the size of tensor a (actn_bbs which comes from b_bb) and tensor b (anchors) which is confirmed with a pdb printout:
RuntimeError: The size of tensor a (16) must match the size of tensor b (4) at non-singleton dimension 0
> <ipython-input-57-dae61e33d5ae>(9)actn_to_bb()
-> actn_centers = (actn_bbs[:,:2]/2 * grid_sizes) + anchors[:,:2]
(Pdb) p actn_bbs.shape
torch.Size([16, 4])
(Pdb) p anchors.shape
torch.Size([4, 4])
Looking within a batch, we can see the size 16 comes from the middle dimension of b_c and b_bb:
batch = learn.model(x)
b_c, b_bb = batch
b_c.shape, b_bb.shape, anchors.shape
(torch.Size([64, 16, 21]), torch.Size([64, 16, 4]), torch.Size([4, 4]))
After a healthy amount of pdb.set_trace-ing, I found that the OutConv layer of the SSD custom head architecture is responsible for the middle axis in b_bb where the size 16 vs 4 tensor mismatch occurs:
# latest flatten_conv after Jeremy's bugfix on March 27
def flatten_conv(x,k):
bs,nf,gx,gy = x.size()
x = x.permute(0,2,3,1).contiguous()
return x.view(bs,-1,nf//k)
class OutConv(nn.Module):
def __init__(self, k, nin, bias):
super().__init__()
self.k = k
self.oconv1 = nn.Conv2d(nin, (len(id2cat)+1)*k, 3, padding=1)
self.oconv2 = nn.Conv2d(nin, 4*k, 3, padding=1)
self.oconv1.bias.data.zero_().add_(bias)
def forward(self, x):
return [flatten_conv(self.oconv1(x), self.k),
flatten_conv(self.oconv2(x), self.k)]
class SSD_Head(nn.Module):
def __init__(self, k, bias):
super().__init__()
self.drop = nn.Dropout(0.25)
self.sconv0 = StdConv(512,256, stride=1)
self.sconv1 = StdConv(256,256)
self.sconv2 = StdConv(256,256)
self.out = OutConv(k, 256, bias)
def forward(self, x):
x = self.drop(F.relu(x))
x = self.sconv0(x)
# x = self.sconv1(x)
x = self.sconv2(x)
return self.out(x)
x in this case is what’s going through the forward pass of SSD_Head. Running pdb trace here, we see that x after the self.sconv2(x) step has the shape of 64 x 256 x 4 x 4 :
-> x = self.drop(F.relu(x))
-> x = self.sconv0(x)
-> x = self.sconv2(x)
-> return self.out(x)
(Pdb) p x.size()
torch.Size([64, 256, 4, 4])
OutConv takes this 64 x 256 x 4 x 4 input x and creates a list of two outputs after running them through flatten_conv() which flattens the last 2 dimensions into 1 (4 x 4 -> 16) and moves it into middle position:
- oconv1 output flattened: 64 x 16 x 21 (21 being
(len(id2cat)+1)*k) - oconv2 output flattened: 64 x 16 x 4 (4 predicted bounding box coordinates)
The bug stems from how many stride-2 convolutions x goes through to get to its 64 x 256 x 4 x 4 shape before entering OutConv.
When the number of anchors was set to 16, no error was displayed because it matched the number of outputs (16) before flattening. But when we change the anchor count to 4, the outconv output remains size 16 because it still goes through the same number of stride-2 convs while the anchor tensor is now of size 4.
I fixed this bug in the first SSD_Head model by introducing an adaptive_maxpool layer (remember these handy things from lesson 7?) to correctly set the final shape size for x before it goes into OutConv:
class SSD_Head(nn.Module):
def __init__(self, k, bias):
super().__init__()
self.drop = nn.Dropout(0.25)
self.sconv0 = StdConv(512,256, stride=1)
self.sconv1 = StdConv(256,256)
self.sconv2 = StdConv(256,256)
self.out = OutConv(k, 256, bias)
def forward(self, x):
x = self.drop(F.relu(x))
x = self.sconv0(x)
#x = self.sconv1(x)
x = self.sconv2(x)
x = F.adaptive_max_pool2d(x, anc_grid) # new adaptive maxpool to set (x.size(2) * x.size(3)) equal to number of anchor boxes
return self.out(x)
I applied a similar fix to the later SSD_MultiHead model where we generate many more anchor boxes:
class SSD_MultiHead(nn.Module):
def __init__(self, k, bias):
super().__init__()
self.drop = nn.Dropout(drop)
self.sconv1 = StdConv(512,256, drop=drop)
self.sconv2 = StdConv(256,256, drop=drop)
self.sconv3 = StdConv(256,256, drop=drop)
self.out0 = OutConv(k, 256, bias)
self.out1 = OutConv(k, 256, bias)
self.out2 = OutConv(k, 256, bias)
self.out3 = OutConv(k, 256, bias)
def forward(self, x):
x = self.drop(F.relu(x))
x = self.sconv1(x)
x = F.adaptive_max_pool2d(x, anc_grids[0]) # adaptive maxpool for 1st size of anchors
o1c,o1l = self.out1(x)
x = self.sconv2(x)
x = F.adaptive_max_pool2d(x, anc_grids[1]) # adaptive maxpool for 2nd size of anchors
o2c,o2l = self.out2(x)
x = self.sconv3(x)
x = F.adaptive_max_pool2d(x, anc_grids[2]) # adaptive maxpool for 3rd size of anchors
o3c,o3l = self.out3(x)
# return [o1c, o1l]
return [torch.cat([o1c,o2c,o3c], dim=1),
torch.cat([o1l,o2l,o3l], dim=1)]
With this in place, for each image, the model predicts categories and bounding boxes the same number of times as the number of anchor boxes set by anc_grid= in the first section.
In the later ‘SSD_MultiHead’ section, this handles changes within anc_grids. I.e. anc_grids=[3,2,1] with k=9 generates 126 anchor boxes ((3x3 + 2x2 + 1x1) x 9) and 126 bb predictions to match. However, this is more of a brittle solution here because it assumes you keep len(anc_grids) == 3 or it’ll throw an out of index error. So this part still needs work/thought.
I’ve compared the training performance before vs after adding the adaptive_max_pool bugfix and found them to be nearly equivalent:
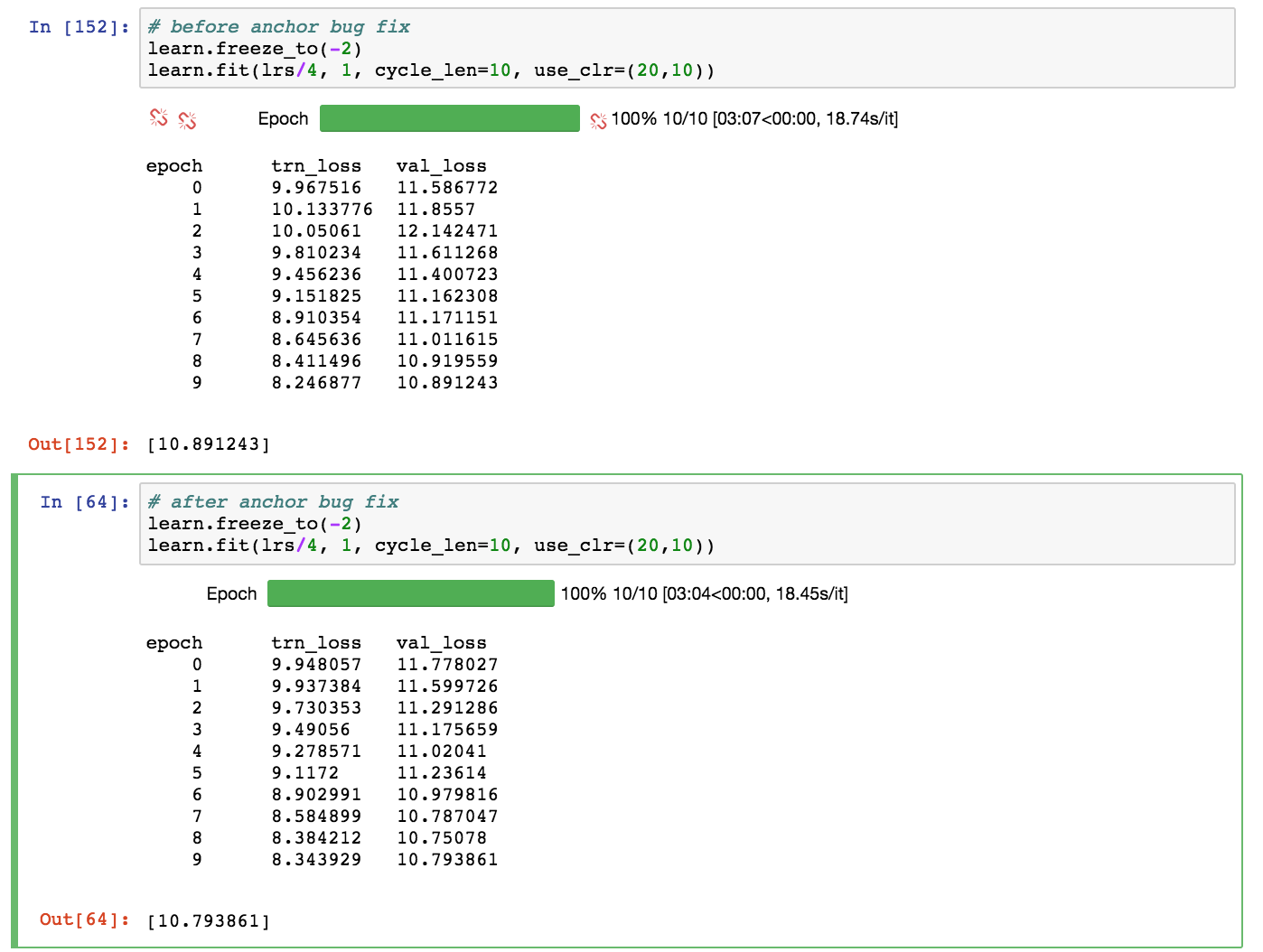
I’m quite new to coding in general so I’m sure there are more elegant ways to fix this bug, and in particular, accommodate for all changes to len(anc_grids) in the More Anchors! section.
Please share any suggestions or comments and thanks for following along with my debugging journey!
 We believe this gives suboptimal performance because we throw away positional information by max-pooling the activations within each receptive field as opposed to convolving through them.
We believe this gives suboptimal performance because we throw away positional information by max-pooling the activations within each receptive field as opposed to convolving through them.