I wanted the starting values for the output sigmoids to have a probability that’s pretty low. Since we know most bounding box activations won’t match most classes. I haven’t tested carefully whether it makes any significant different however - would be interested to hear what you find.
2 Likes
It worked! Time for me to start reviewing 
1 Like
I tuned in a few minutes too late and missed the first highlight that jeremy shared. The one before the awesome VAE blog post. Does anyone remember what he shared? I often find those snippets to be very valuable and I was planning to go back and rewatch that part but the rerecording didn’t include that part.
Makes sense! I’ll try to play around this tomorrow, it’ll be good practice. ![]()
In Bbox per cell section one of the transforms is:
RandomLighting(0.05, 0.05, tfm_y=TfmType.COORD
Why we are making a light transform coordinated with the bounding boxes?
You can check the video! ![]()
As mentioned in class, it’s redundant - doesn’t actually do anything here. But doesn’t hurt either.
1 Like
Finally got around catching up with the second half of the lecture. That was pretty intense  ! The conceptual explanation was super
! The conceptual explanation was super  , will now have to think more about it
, will now have to think more about it  and mess around with the notebooks.
and mess around with the notebooks.
I somehow had this random idea into the first half of the lecture, that if we made the anchor boxes small enough(1px), we could then start classifying at the pixel level. But clearly, I hadn’t thought it through, and my dreams are shattered now. 
Sure you can ![]() As long as you have pixel-level labels. And if you do, it’s called segmentation, and we’ll be learning that later in this course…
As long as you have pixel-level labels. And if you do, it’s called segmentation, and we’ll be learning that later in this course…
5 Likes
Omg yes !
I found a bug in flatten_conv in the pascal-multi notebook. Fixed now. Makes finding the smaller objects look much better when k>1.
2 Likes
Ah, yes. But what if we want to do it in a single pass for images which contain multiple objects of interest? Say you want to detect all the faces in an image and straighten them all in a single pass. Although I’m still skeptical about the use cases, for faces we’d probably be better off using face alignment models.
I need a little bit of a help here with BatchNorm 
Here I think Jeremy says “BatchNorm is meant to move towards a [0, 1] random variable”. Wouldn’t BN try to make the mean of the activation closer to 0 and standard deviation closer to 1, so activations should be (hopefully) somewhere between -1 and 1?
Nearly - a standard deviation of 1 means ~68% should fall between -1 and 1, if normally distributed. 68–95–99.7 rule - Wikipedia
Although also there are the beta and gamma coeffs (the affine transform) in the batchnorm layer, which can then pull the mean and std away from 0,1 again…
2 Likes
Ohhhh, I got it. 0, 1 is not a range but they correspond to mean and std. I was scratching my head because there must be negative values that we don’t want to chop off with ReLU right after.
Thank you so much for the quick response!!
I’m rewatching the video (thanks for getting it up so quick) and am having some questions when you put the conv2d onto your model and have 2x2x(4+c). So this would take the image and split it into 4 parts. Then each of those parts would be compared against 4+c filters to see which one activated it the most, is that correct? So going back to part1 if the dog eye filter was one of the 4+c filters, this would activate once one of the 4 parts looked like a dog eye, am I saying that correctly?
No. The ‘matching problem’ is solved by figuring out which ground truth object has the highest jaccard overlap with that grid cell.
After doing that, we take each matched object and the activations corresponding to the matched anchor box, and calculate L1 loss of the 4 coord activations, and binary cross entropy loss of the c+1 class activations (but removing the background class).
I think I might be misunderstanding what is happening here:
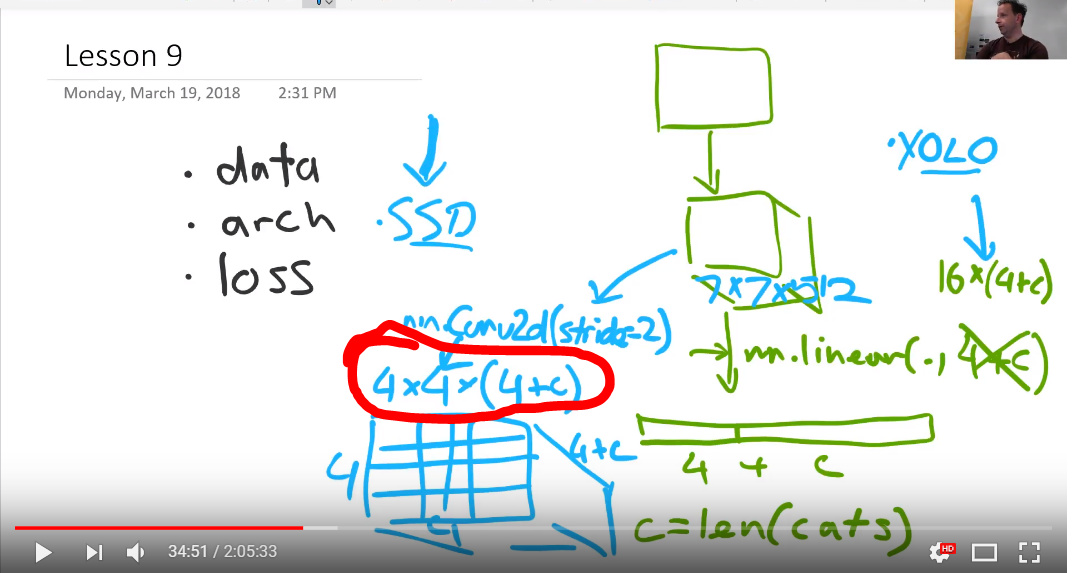
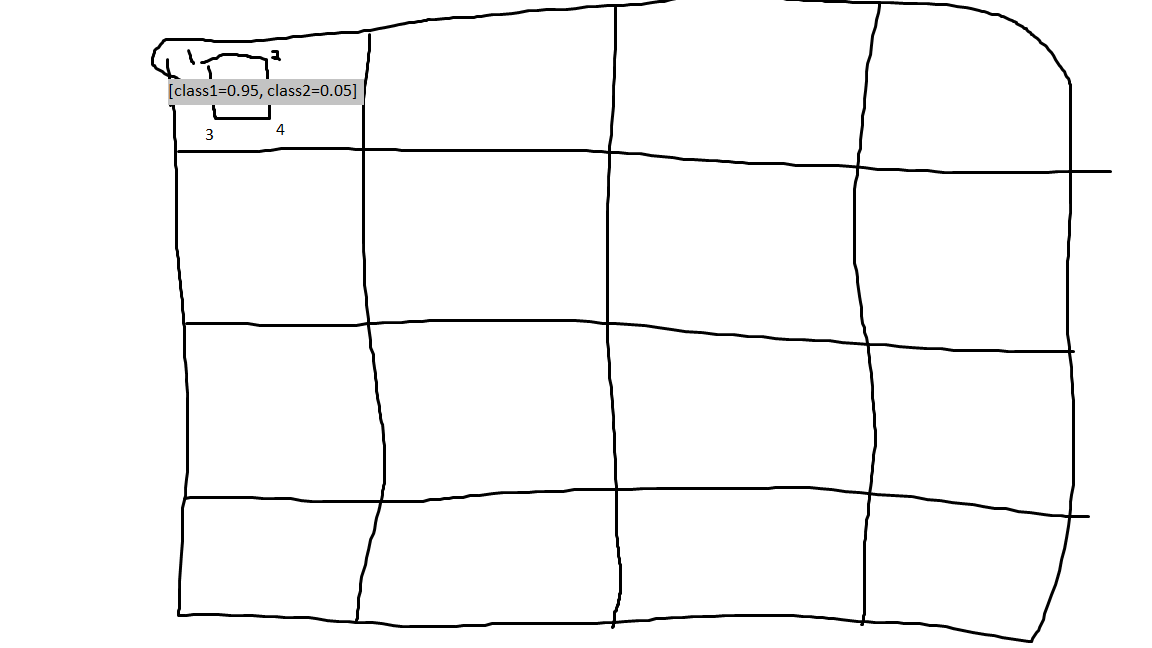
So how I am understanding that is that the 4x4 means that there are 16 different sections and then the 4+c piece is the bounding box coordinates and how much of each class that bounding box looks like, but I’m thinking I have something wrong with my thoughts there.
Crude drawing of my thoughts so in this case, the bounding box would be [1,2,3,4] and the class part would be [0.95,0.05] so altogether it would be [1,2,3,4,0.95,0.05] and you would do that for all 16 of the boxes:
there is this idea form Stanford class 231n, where a hyperparameter decides how much of each loss value(bounding box loss and classification loss) should contribute in calculating gradients. He says we should try different combinations and decide. we should have some other performance metric to make this decision.
1 Like