Experimenting with wgan notebook: I tried running the wgan notebook on another lsun category church_outdoor, for kicks. This is a smaller dataset (2.3GB), you can download any of the other 10 scene categories by replacing ‘category=bedroom’ with appropriate tag (church_outdoor for eg) in the notebook download instructions. To see improvements in GAN I’ve tried obvious things like a) showing more data to GAN and b) more iterations of the train loop. Other suggestions to improve the performance (visual appearance, rather) of the generated GAN’s are welcome!
PS: Found this guide on tips and tricks to make GANs work by Soumith, though its a year old and we’re doing most of it already (normalize data, use DCGAN, separate real and fake batches, leaky relu)
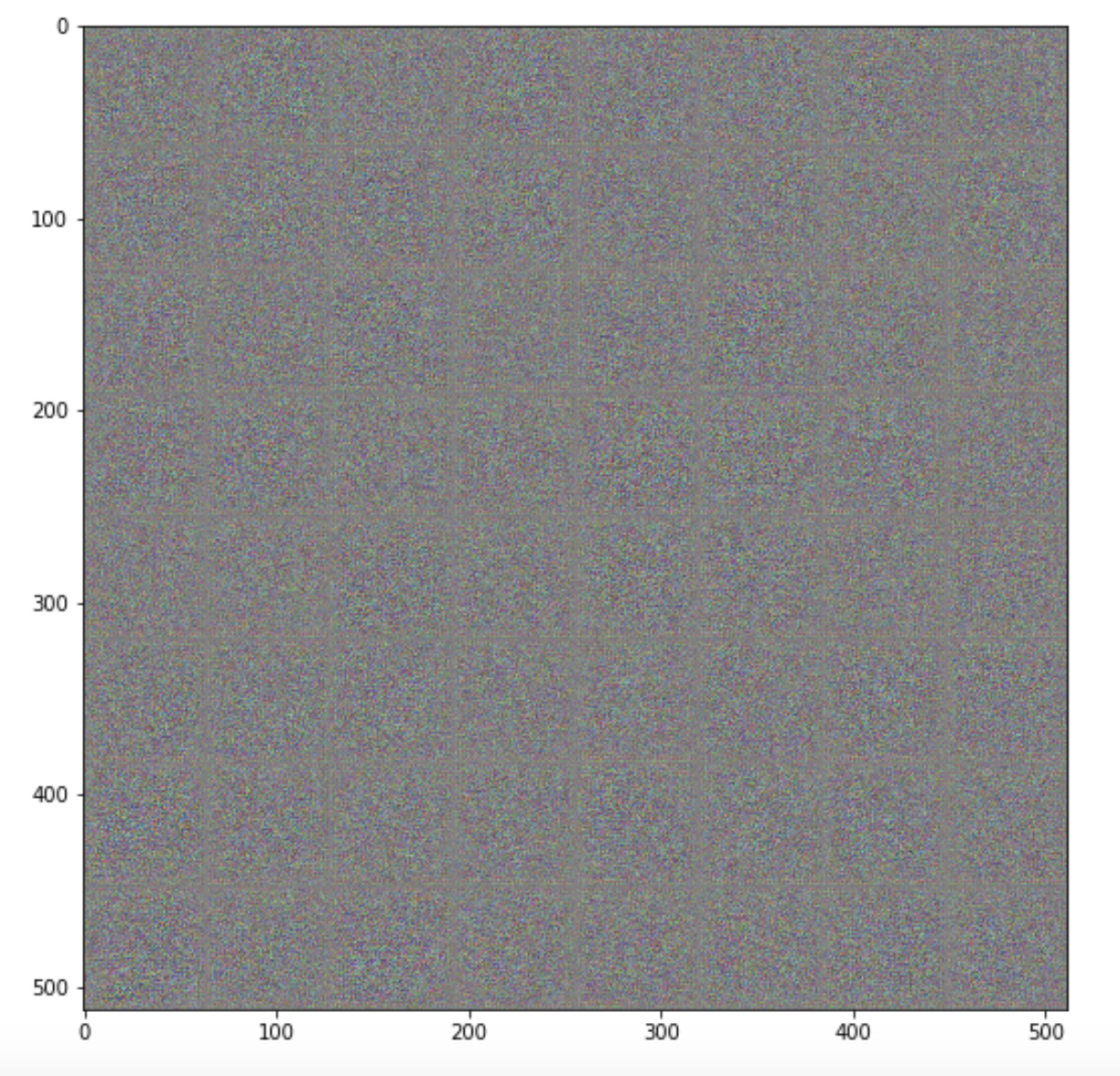
Increasing data sample size.
The images are for 10%, 50%, 100% respectively, of the church_outdoor dataset used (1 epoch).
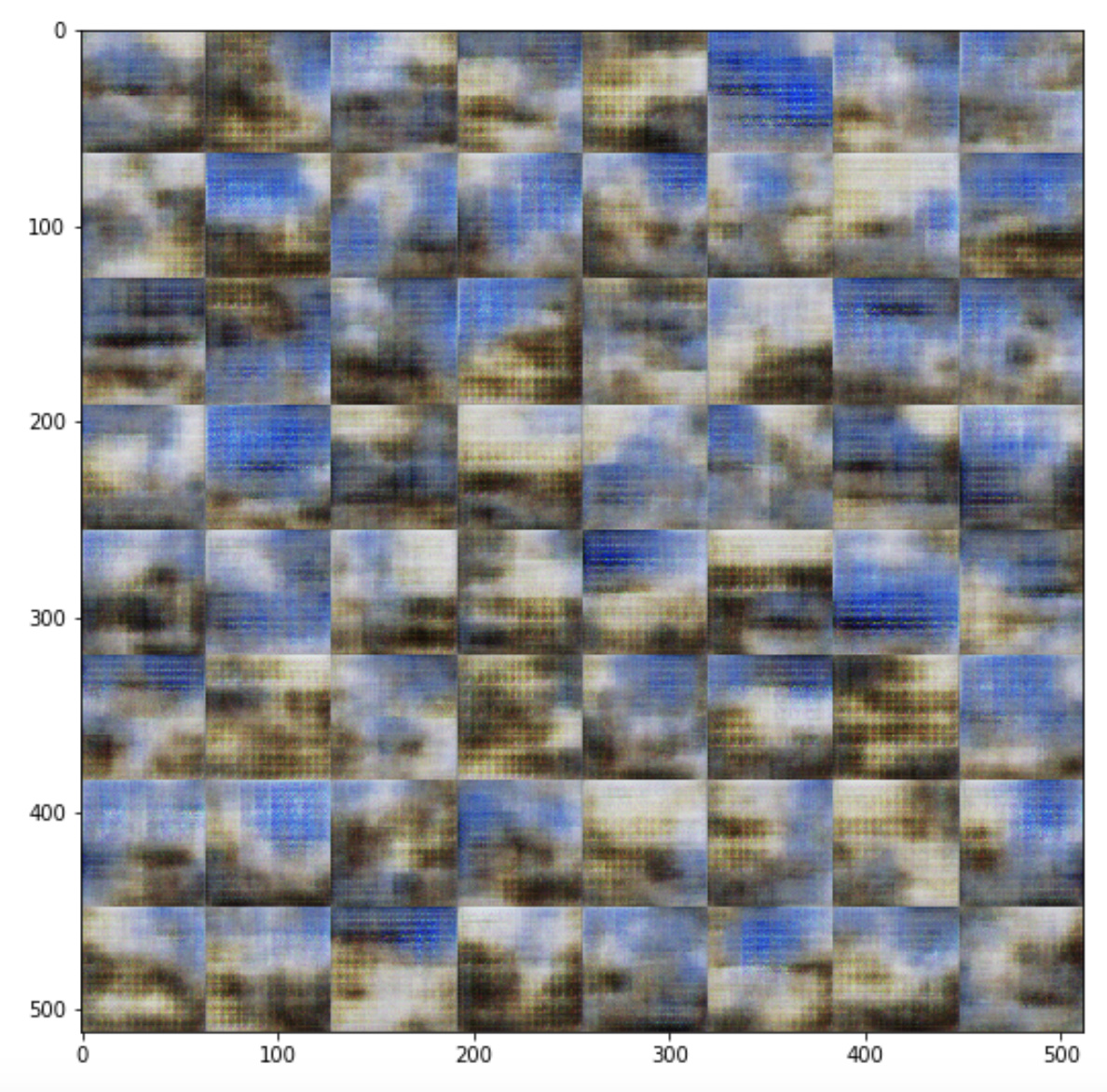
Increasing training loops Running the notebook for 10, 50 and 250 iterations respectively with 100% data used. The images start looking more and more realistic.
Loss numbers for 10 iterations (6 min to run):
Loss_D [-1.37384]; Loss_G [0.72288]; D_real [-0.71672]; Loss_D_fake [0.65712]
For 250 iterations it took nearly 3 hours:
Loss_D [-0.50636]; Loss_G [0.45063]; D_real [-0.41054]; Loss_D_fake [0.09582]
The values jump around quite a bit but I think there is still slight improvement over every 10 iterations or so. Would be worthwhile trying more than 500 iterations, perhaps to exercise d_iters =100 case also ?
d_iters = 100 if (first and (gen_iterations < 25) or (gen_iterations % 500 == 0)) else 5
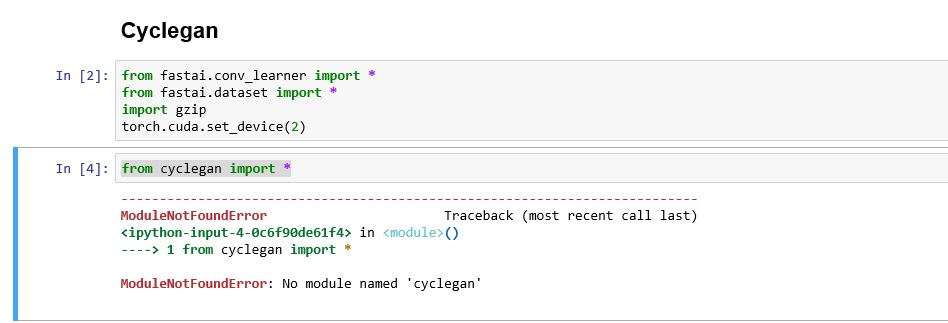
When running the cifar10-darknet notebook, I was getting this error:
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation
I had previously worked off the video and did not have the issue. It appears to be a result of the line that is commented out. In the video, there was a discussion about trying to save memory and work on things in place and x.add_ was added at the time. Using the original line (that is above the commented out line) will work.
Updated: As Nikhil suggests below, simply taking off the underscore after add will make it not be an in-place operation and directly addresses the error message.
No worries, it didn’t take long to figure out how to resolve it, but I thought it might be helpful to others that may get stuck. I’ll try again once I’ve upgraded Pytorch to 0.4 to see if it is resolved.
Yes, we noticed this error in the South Bay study group yesterday. x.add without underscore should work too.
Also the in-place operation was not a problem while defining the Leaky ReLU in conv_layer…
My view is that Part 2 is where one starts to get a more in-depth view of AI experiments that very few people (globally) are doing right now. Sticking to the 10-hour-a-week schedule while implementing all these models from scratch, finding interesting datasets, and reading/skimming/bookmarking important papers means I’m behind as well, but that’s OK as long as I’m consistent about asking questions, research, thinking about problems, and writing about what I learn.
I was worried in the first week, but I’ve realized that the fastest way to get the most out of this class is to keep trying things until I understand. I suppose the only pressure is to write clearly about it at the end of any interesting checkpoint. The beautiful thing here is that once you’ve done this, there’s literally no stopping you. You’re nearly at the edge of what people know to be possible, and the difference between you 5 weeks ago and when you finally write clearly about GANs, SSD or RetinaNet, is the thousands of people who could learn from you.