that worked. thanks!
Does anybody know why I am getting wrong number for trn_dl length? I am getting 293 as the length, but when I check the dataset length it is 37469, which is the correct value. The resize operation is also resizing correct number of files.
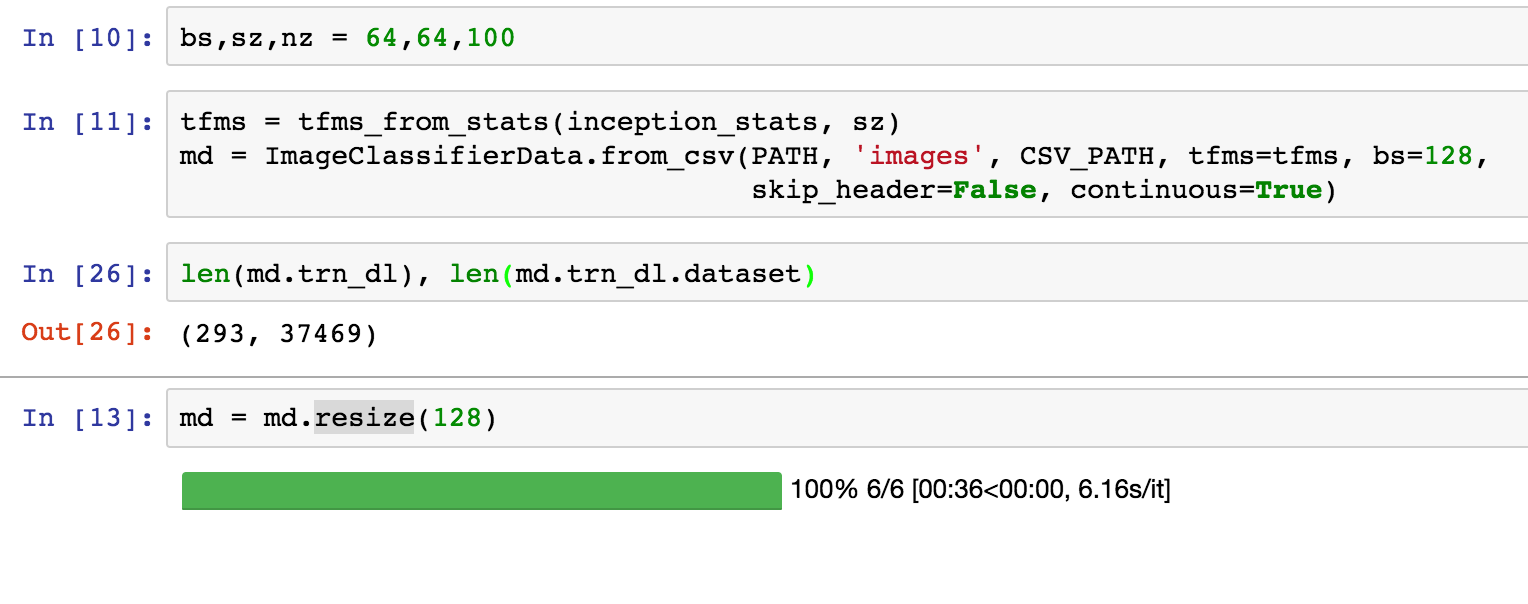
The length of trn_dl is equal to the number of batches in one epoch. You can verify this is correct by dividing 37469 by your batch size (128) and rounding up.
Thanks, I thought when I call train(1, False) it is going to use whole dataset. Right now it is using only 293 images. So, how do I train using full dataset?
That is very comforting to know. I was struggling with the previous lessons and was thinking how on earth I will cope up with this. I only have a P2 in AWS the processing time for the previous lessons are also large.
So the progress I make is limited by the speed as well as my ability to understand and implement. I am still to start reading papers though.
But since now you have made it clear I will reset my expectation and take it up one by one so that I can master them as I go along.
2 Likes
Thanks! it is very comforting to know that I am not alone. I have the same approach as you do but only that I can spend only 15 hours a week on this. So you can understand my learning curve based on the same. But as you and Jeremy rightly pointed out, I will take this step and step and go along with first understanding and then implementing. Whenever I feel stuck with my speed or progress, I remember what Jeremy told previously - It is the perseverant who he has seen succeed in this space more than anybody else 
1 Like
Thanks, now I got it.
I got results that were closer to Jeremy’s when I used the full dataset instead of the 10% sample.
Hi Rohit, Were you able to download the dataset. When I try it on my P2 instance in AWS, it gets cut after about 34G of data is downloaded.
Yes, I was able to download it with no problems. I used a Google cloud instance.
@Ducky Don’t worry it comes with time and practice. This is my second time around taking part 2 and I’m just now starting to understand some key concepts. I’ll share three things that have really helped me this time around.
First, I’ve been pulling the lectures off youtube onto my phone so I can listen to them as I bike to work. I’ve got an hour long commute (East Van to Richmond) and Jeremy’s voice is pretty much all I listen to all week long. Hearing the lectures for the second or third time makes a huge difference in terms of catching some of the key points or understanding them.
Second, I got much more comfortable with the python debugger, and I started throwing breakpoints all over the code so I could look at the vectors and what’s being passed at each point.
And finally and probably most importantly I built a neural net end to end that wasn’t based off of any of the models that Jeremy taught. This meant I had to build a custom dataset, data model, data loader class, a custom model class, and a custom loss function. The debugging of that was painful and that’s where pdb really shone. Now I feel much more comfortable with what’s going on underneath the hood.
I know it feels overwhelming at first, and I struggled my first time through as well, but I’d suggest focusing on understanding one project really well rather than trying to understand it all. The lectures are there to come back to once you’re ready, and the forums stay active after class is through for questions, especially when it’s opened up to the public.
Keep at it! Jeremy’s mentioned a few times that the most important component to success in this field is persistence.
21 Likes
Google Brain team has just announced their DAWNBench result for ImageNet classification. when we change from CIFAR10 to ImageNet, what kind of changes are needed in the architecture? I am curious to know the time and $ fast.ai algorithm is going to take
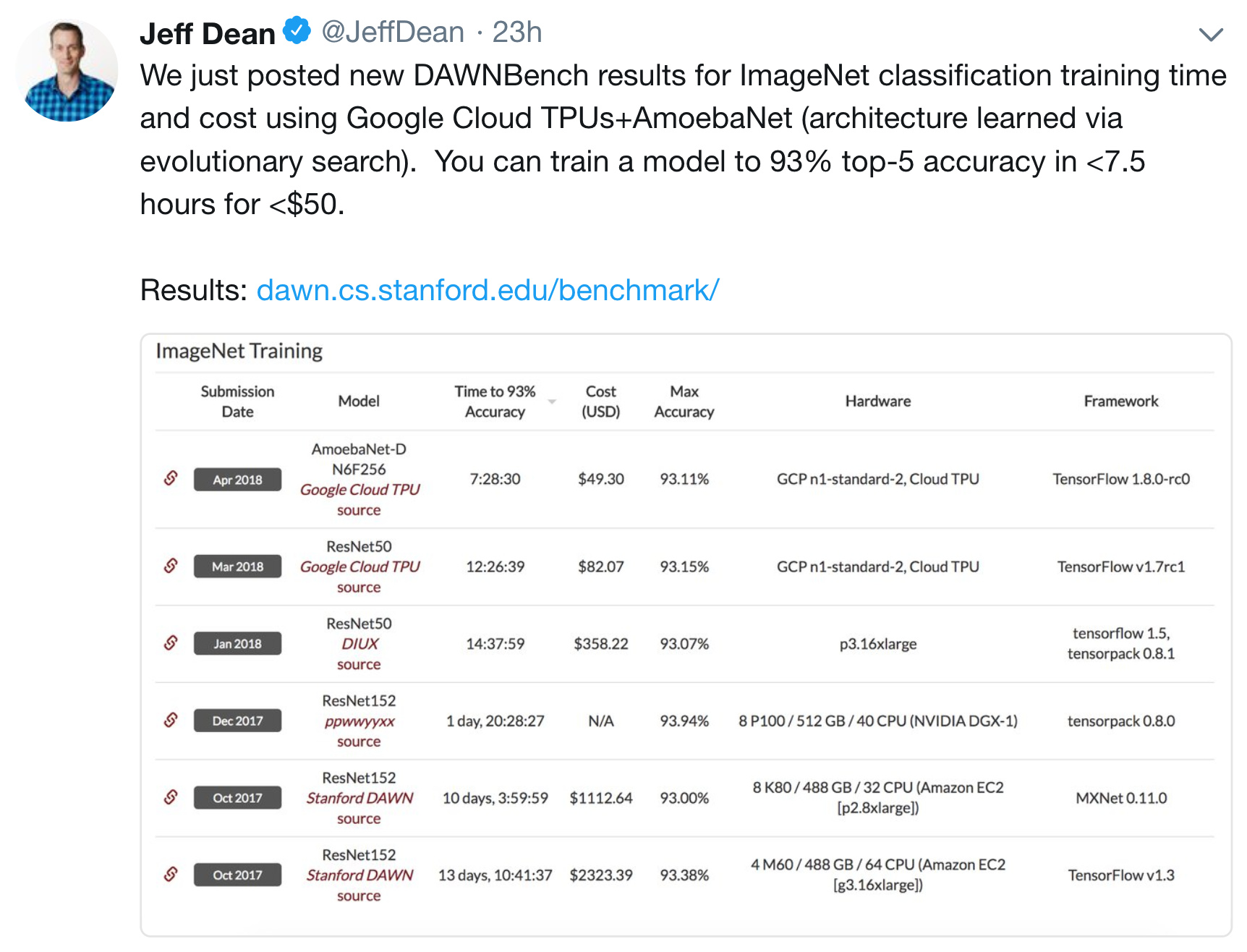
1 Like
Yes, the full dataset gives a much better result.
Fun with datasets (or NOT)
Tried to run CYCLEGAN on both of my GPUs and it seemed to only run on the second one:
--gpu-ids='0,1' so I said OK, lets just try one GPU --gpu-ids='1': the first training block is currently running on that GPU and takes 778 seconds per epoch, running 200 epochs should take 43 HOURS (if my math is correct). BTW if you’re wonding why I didn’t start with WGAN, it’s because the 47.2GB dataset is still downloading. Yes, I know I should start with smaller datasets, but what’s the fun in that.
We haven’t figured out how to get good results with imagenet yet, unfortunately. Not sure why yet.
I have a single 1080Ti and it took about 30 hours for 200 epochs.
I only have a 1080  , well actually I have two
, well actually I have two 
I’m running the wgan.ipynb notebook and keep hitting this error
In [22]: train(1, False)
0%| | 0/1 [00:00<?, ?it/s]
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-23-0493450504b2> in <module>()
----> 1 train(1, True)
<ipython-input-21-344f55de6ecd> in train(niter, first)
5 data_iter = iter(md.trn_dl)
6 i,n = 0,len(md.trn_dl)
----> 7 with tqdm(total=n) as pbar:
8 while i < n:
9 set_trainable(netD, True)
~/fastai/courses/dl2/fastai/imports.py in tqdm(*args, **kwargs)
45 if in_notebook():
46 def tqdm(*args, **kwargs):
---> 47 clear_tqdm()
48 return tq.tqdm(*args, file=sys.stdout, **kwargs)
49 def trange(*args, **kwargs):
~/fastai/courses/dl2/fastai/imports.py in clear_tqdm()
41 inst = getattr(tq.tqdm, '_instances', None)
42 if not inst: return
---> 43 for i in range(len(inst)): inst.pop().close()
44
45 if in_notebook():
~/src/anaconda3/envs/fastai/lib/python3.6/site-packages/tqdm/_tqdm.py in close(self)
1096 # decrement instance pos and remove from internal set
1097 pos = abs(self.pos)
-> 1098 self._decr_instances(self)
1099
1100 # GUI mode
~/src/anaconda3/envs/fastai/lib/python3.6/site-packages/tqdm/_tqdm.py in _decr_instances(cls, instance)
436 with cls._lock:
437 try:
--> 438 cls._instances.remove(instance)
439 except KeyError:
440 if not instance.gui: # pragma: no cover
~/src/anaconda3/envs/fastai/lib/python3.6/_weakrefset.py in remove(self, item)
107 if self._pending_removals:
108 self._commit_removals()
--> 109 self.data.remove(ref(item))
110
111 def discard(self, item):
KeyError: <weakref at 0x7f3eb51d28b8; to 'tqdm' at 0x7f3eb80dd048>
It’s another problem with tqdm. I’ve just ran git pull, conda env update, and conda update --all. I still get this error. My current fix is to replace the line with tqdm(total=n) as pbar: with if True: and comment out pbar.update(). This seems to work, but there’s no progress bar.
I asked someone else in the course and they’re not hitting this issue. Any ideas?
Looks like you’ve got a newer version of tqdm - I noticed this somewhere else with the new version. I fixed it by replacing these lines in _tqdm.py (see 2nd bottom bit of your stack trace):
except KeyError:
if not instance.gui: # pragma: no cover
with
except KeyError: pass
5 Likes
