That’s the word2vec paper ![]() We’re just using more modern word vectors.
We’re just using more modern word vectors.
@jeremy @rudraksh There actually is an alternative. See this paper (Inan, 2016). It’s cited in the “Regularizing and Optimizing LSTM models” paper. Intuitively, Inan is like, “if the model guesses ‘car’ but the word was ‘automobile’, it should be less wrong than guessing ‘whale’.” They’re approach is to take the target (true) word embedding and do an inner product with the vocabulary as a whole. This gives them a target probability distribution for the whole vocabulary. They then compare this target distribution with the probability distribution output from the model. They call this “Augmented Cross Entropy Loss”. From the paper itself…
In words, we first find the target word vector which corresponds to the target word token (resulting
in ut), and then take the inner product of the target word vector with all the other word vectors to
get an unnormalized probability distribution. We adjust this with the same temperature parameter
τ used for obtaining yˆt
and apply softmax. The target distribution estimate, y˜, therefore measures
the similarity between the word vectors and assigns similar probability masses to words that the
language model deems close. Note that the estimation of y˜ with this procedure is iterative, and
the estimates of y˜ in the initial phase of the training are not necessarily informative. However, as
training procedes, we expect y˜ to capture the word statistics better and yield a consistently more
accurate estimate of the true data distribution.
The author’s note that the augmented loss (AL) is more helpful with smaller datasets. But it doesn’t help much with larger datasets. From the paper: “for the larger Wikitext-2 dataset, improvement by AL
is more limited”.
To me this is approach is similar conceptually to the Devise paper. Generically, they’re both finding a way of making the target variable continuous, rather than discrete, which allows the loss function to be nuanced.
Also, to jeremy’s point below, this doesn’t directly address the instances when re-ordering the words would be equally correct. However, it does make the cross entropy “less harsh” to incorrect words. And intuitively, I’m not sure if the loss function is the correct place to address the fact that language can support multiple word orderings. I mean you could have a loss function that doesn’t care at all about ordering, but that’s probably not what you want. Understanding what all the possible orderings are would be hard, and you might want to learn it first through a neural net! And then incorporate that somehow…
4 Likes
That’s an interesting paper, but I don’t think it’s dealing with the issue raised. Specifically, LMs are not seq2seq models really - i.e. the output length is always equal to the input length, in the same order. So there isn’t a problem that there’s lots of ways of ordering the words.
1 Like
Great resources for papers and benchmarks
1 Like
I’ve tried numerous times to download the lighter word vector (https://fasttext.cc/docs/en/english-vectors.html) on my PC but the download always fails. The site loads up very slowly and when I try to download a vector the download usually starts at a speed of around 500 - 2000 kb/s but then quite quickly trickles down to almost nothing and then eventually dies.
Is this because there’s always a bunch of people (all of us  ) at the same time trying to grab a vector?
) at the same time trying to grab a vector?
You can use glove or word2vec vectors instead - shouldn’t make much difference.
OK, I just don’t understand how beam search helps here. what graph are we searching?
2 Likes
Tried this one (http://mccormickml.com/2016/04/12/googles-pretrained-word2vec-model-in-python/) and it seems to work OK!
1 Like
I used BPEmb from here - https://github.com/bheinzerling/bpemb
You can download the SentencePiece model and vectors for 275 languages from here. I got this result on Lesson 11 dataset (200000 merge ops, 300 dims)

I used the Lesson 11 code and build a Malayalam headline predictor (using Malayalam News as X, and Titles as Y), and used BPEmb, got better result than fasttext (count of missing words are very less while using BPEmb)
For Malayalam
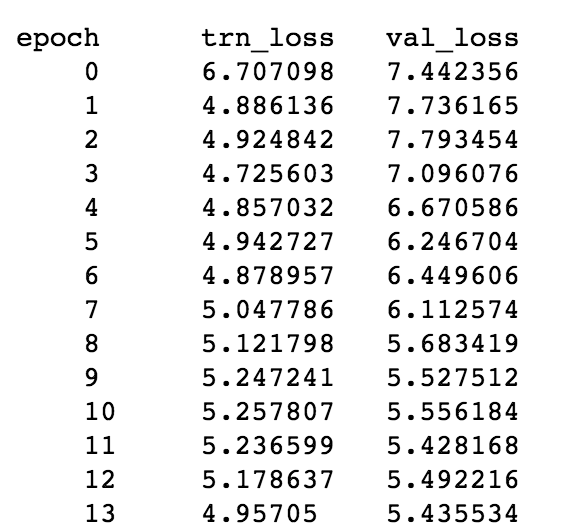
5 Likes
I should probably read the link that Jeremy posted, but this is how I understand it:
Currently, we have a greedy approach at every timestep - we take the word with the maximum probability at that timestep. Instead we could keep track of the top k words at every time step, and use those words to generate predictions for the next word. The second timestep would then have k predictions for each of the top k words from the previous timestep. We can continue the process and get the words that jointly maximize the probability of the translation.
1 Like
I’ve spent the last few hours trying to wrap my thick skull around how to do just that. The Beam Search Strategies for Neural Machine Translation paper discusses the process. They discuss various optimization strategies for searching and pruning the tree. I’m still trying to figure out how to modify the code.
1 Like
No need to read the link - you’ve got it perfectly! ![]()
rnn = Seq2SeqRNN(fr_vecd, fr_itos, dim_fr_vec, en_vecd, en_itos, dim_en_vec, nh, enlen_90)
learn = RNN_Learner(md, SingleModel(to_gpu(rnn)), opt_fn=opt_fn)
I found this two line of code is useful when I re-visit the lecture. It allows us to wrap a Learner class on any custom Pytorch class. i.e. You can wrap a learner on a Pytorch nn.module class, then you can use function like learner.lr_find()
2 Likes
In lesson 6 we use identity initialization for CharSeqRNN, why wouldn’t we use it for Seq2SeqRNN in this case?
1 Like
When not using LSTM/GRU/etc, then it does make sense to use identity init.
2 Likes
I thought there were GRU unit connected with the encoder embedding and decode embedding? Sorry if this question is stupid. I think in this case weight are randomly initialize except the embedding layer get it weights from FastText?
yes, you are right.
Unlike Language Model in lesson 10, there is no pre training of the model involved in seq2seq model.
Like you said only FastText embeddings are used for English and French words in the sentence.
Curious why there was no pretraining tried here?
So why wouldn’t identity initialization for GRU helps in this model
As discussed in the lesson, this is just something I haven’ t gotten around to yet.
1 Like