Hmmmmmm. But it can still go up to one, which it does at LR<~1e-2 and above ~1e12. How is it able to stay down at the .3 level over such a huge range of learning rates? My intuition is totally failing me.
I don’t think it’s randomly finding values which happen to give low error rates, because this graph seems pretty consistent over several different runs.
Is it that there is a huuuuuuuge “flat spot” on the manifold and it takes a while for a step to randomly step out of it? (If so, why would the manifold have such a huge flat spot?)
Yes there is. But don’t use intuition to see this - you’ll probably need to look carefully at the weights and activations at this point to see why this is.
Devise, building the validation set from the Imagenet download
OK, so you’ve bought a great big hard drive and downloaded and unpacked the 170GB imagenet. Now how do you make the validation set from the ILSVRC/Data/CLS-LOC/val directory?
Download this handy script from julian simon into the aforementioned directory.
Change the script file to executable with "chmod +x build_validation_tree.sh"
Then run it by going into the directory and doing ./build_validation_tree.sh
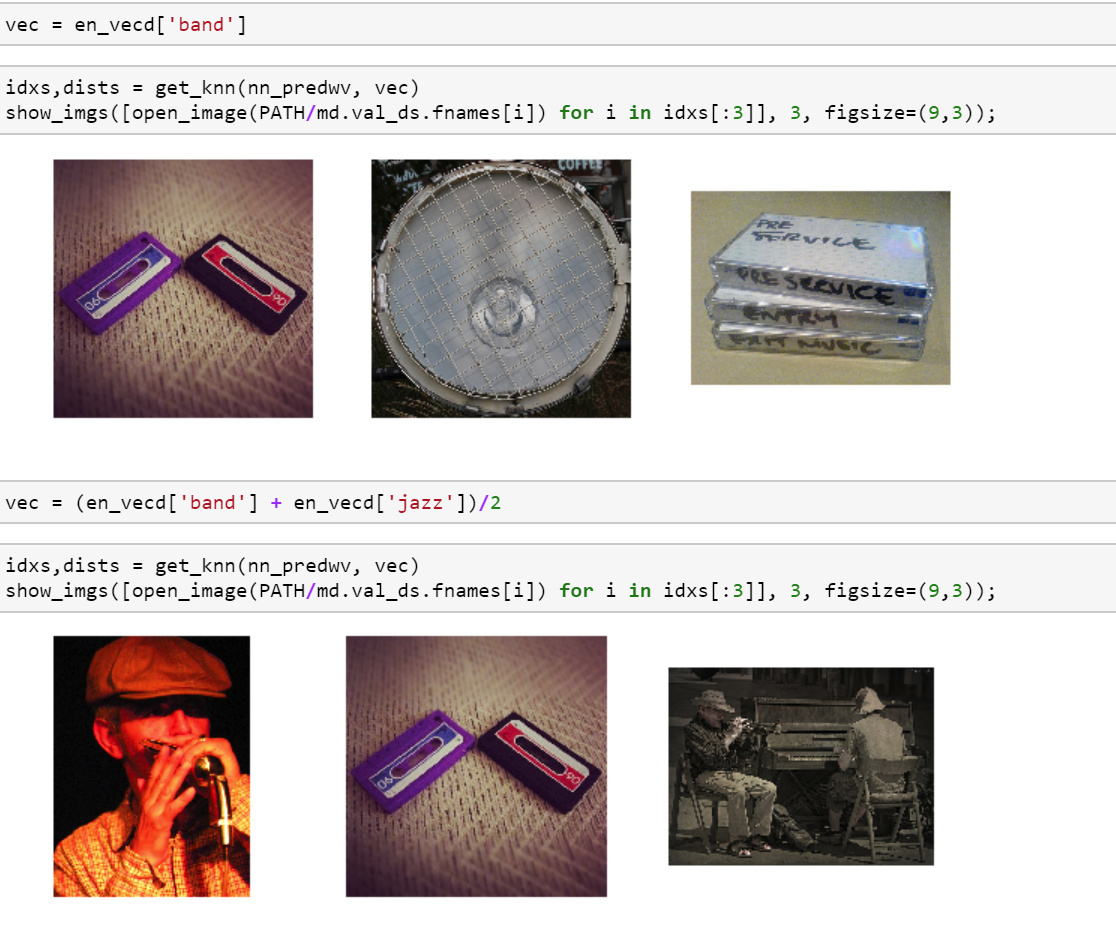
I’ve run the devise notebook on this dataset. Results are reasonable considering this is a more difficult challenge for the machine as images are 64 pixels vs ImageNet.
There is a fair bit of wrangling to get the tiny-imagenet dataset into the correct format, but between this and the pascal_tiny_imagenet.ipynb in the same folder there should be enough code to make this pretty painless.
Using cross-entropy loss for seq2seq models seems kinda harsh since there are multiple ways in which a sentence can be re-arranged to convey the same semantic meaning. Are there any alternatives?
When you first did this and decided to use a cosine_loss function based on cosine_similarity, did you expect the LR finder to have that type of a troth? Or did you expect it to run in a similar way to L1 Loss? I guess what I’m really asking is in the continuum of possible loss functions to use for classification and regression, should there be different LR finders?
Alternately, there are some forms of screwup that might make the learning rate fairly insensitive to what you are doing. For example, if you hit shuffle at the wrong stage and shuffle all of the words instead of all the sentences, then you will only learn the probability distribution of words. This results in a quick zoom to flatness like the first half of your graph. I can also imagine that from there, perhaps gradients are almost non-existant, and you could get this graph.
I guess what I’m saying is that if you see something that makes no sense, look for bugs!
The DeViSE paper is fascinating. The embeddings they used don’t seem to be the ones we used. The paper states:
We trained a skip-gram text model on a corpus of 5.7 million documents (5.4 billion words) extracted from wikipedia.org. The text of the web pages was tokenized into a lexicon of roughly 155,000 single and multi-word terms consisting of common English words and phrases as well as terms from commonly used visual object recogntion datasets. ... For more details and a pointer to open-source code see [13]
[13] is:
Tomas Mikolov, Kai Chen, Greg S Corrado and Jeffrey Dean. Efficient estimation of word representations in vector space. In ICLR Scottsdale, AZ, USA 2013
I searched and searched and couldn’t find anything open-source or close to it other than some references to Word2Vec.
The paper goes on to say that they tested with “500- and 1000-dimensional skip-gram models.”
We’re using a 300 dimensional word model (no phrases and other mods) for almost 50,000 words. They’re using 500 and 1000 dimensional models that map to 155,000 words,phrases,etc. I’m curious to test imagenet with their 500 and 1000 dimensional embeddings to see how much better the results would be. I wonder if anyone knows how to get those embeddings.
Just finished implementing Seq2Seq from scratch. Getting comparable performance to Jeremy’s implementation. One thing I noticed is that Jeremy sets the bias to zero on the encoder Linear layer. Wondering why that is. It kind of makes sense in that we want all the hidden state activations to be centered around 0. But would love to hear other people’s opinions.
class Seq2SeqRNN(nn.Module):
def __init__(self, vecs_enc, itos_enc, em_sz_enc, vecs_dec, itos_dec, em_sz_dec, nh, out_sl, nl=2):
super().__init__()
self.nl,self.nh,self.out_sl = nl,nh,out_sl
self.emb_enc = create_emb(vecs_enc, itos_enc, em_sz_enc)
self.emb_enc_drop = nn.Dropout(0.15)
self.gru_enc = nn.GRU(em_sz_enc, nh, num_layers=nl, dropout=0.25)
######## Why is the bias set to False below? ########
self.out_enc = nn.Linear(nh, em_sz_dec, bias=False)
In general, the other thing I noticed is that the performance of the architecture is pretty underwhelming. In particular, it tends to repeat the same word again and again. Wonder what people’s thoughts are on explicitly penalizing repeats in the loss function?
Edit: Just realized that the performance is much better on short sentences. Points to the fact that the single hidden state is not able to capture all the context. Attention should definitely do better.
Edit 2: Attention doesn’t seem that much better. Looks like language models should be incorporated in to make it better.