A place to share your blogs or the blogs that you have read and found interesting or related to part 2 lessons.
Here is a non-technical, autobiographical blog of a noob coder who has become a noob DL Practitioner.
Dear Experts, please excuse the blog. For anyone else who is getting started, I hope you find motivation in my story.
If I can get started on the DL Path, so can you.
Sanyam.
7 Likes
@jeremy I wanted to request you to pin this so that we could follow the tradition of Part1V2 where everyone would share their blog posts in a thread.
We haven’t pinned them in the past - it just stays close to the top when people keep posting their cool work ![]()
1 Like
Apologies, I misremembered 
Well part 2 has a great focus on generative models, don’t know if VAEs specifically will be covered in class or not, but I wrote a blog trying to intuitively explain why they work, hope it’s useful to someone here:
24 Likes
That’s some absolutely exceptional writing. Really well done.
I’m not planning to cover VAEs - and now I don’t have to feel guilty about it, since you’ve covered it so well! ![]()
Have you got any thoughts on VAEs vs GANs and their pros and cons? I’m familiar with the theory of VAEs but don’t have the intuition of a practitioner in this area.
3 Likes
Hey all.
I’m looking for some feedback on a post I banged out over this weekend.
I love using IPython notebooks for exploring data and visualizing results, but I’m really not a fan of using them for larger coding projects. On the other hand, remotely editing code being run on a different server ends up being a much bigger pain than just working in the browser. I tried a number of different remote editor approaches and compared them (with setup instructions):
http://matttrent.com/remote-development/
I’d love to hear some folks thoughts. Is this interesting? Let me know what makes sense and what doesn’t. What’s missing and what’s extraneous? Don’t worry about spelling and grammar mistakes (there’s a lot!). I haven’t had a chance to edit those yet.
Thanks!
4 Likes
Thanks for the post! I’ve moved it into this blogs topic - hope that’s OK.
A minor issue but significant: I don’t normally care about fonts at all, but for some reason the font on your sight was a strain on my eyes. Kinda funky kerning or something - not sure. It could just be when viewing on Windows, or firefox, or something… I like the layout though!
Personally, I much prefer using vim and jupyter notebook to the local editor approach. Clearly the approach you’re using is valuable to you, so it’s great that you’re talking about it - but I think it might be more helpful to mention that plenty of people really do think that the alternatives you gloss over at the start are actually a great idea? As it stands, I’d be nervous about recommending this post myself, because I feel like it could give the wrong impression that using a local editor is a strictly better option.
I’d be more comfortable with something that said clearly that you’re describing an approach which the reader may or may not find better, but it’s certainly worth trying to see how they like it.
Having said that - I found the body of the article clear and helpful. 
2 Likes
Even though both are generative models, they’re still dramatically different I’d say:
VAEs:
Pros:
- Much easier to train, unless the loss function has an error in it or something it will usually work well
- Can directly generate sequential data, decoder style, one at a time. Really useful for generating things like MIDI samples, on GANs doing this is non-trivial.
- Usually easier to perform finer transformations on data you already have, just plug into encoder, get latent vector and perform transforms, decode it out
Cons:
- VAE outputs tend to be “blurrier” than GANs, and in general, lower quality
GANs:
Pros:
- Trained properly, they have extremely high quality samples, that are nearly indistinguishable from reality
- Much better suited to certain tasks like super-resolution, CycleGANs, “large scale” transforms where little fine control is required
Cons:
- Very unstable in standard form, recent papers help fix that problem, but training can still be non-trivial, even the loss function does not directly mean anything
- Prone to behaviors like mode-collapse
- Sequential data usually requires work-arounds like 1-D transposed convs, which isn’t a great substitute for temporal nature of longer samples
GANs are making tremendous progress though, and it wouldn’t be surprising if they became the dominant generative model for most domains in the future
8 Likes
Makes total sense, re: which approaches I’m recommending. There’s lots of material documenting vim and notebook approaches, so I focused my energies on the alternatives which I found minimal documentation on. I assumed a reader that was not happy with the usual way, but that’s not a good approach for a use as general recommendation.
To make it a more balanced read, would it be sufficient to change the intro and “what I won’t cover” sections to something that more accurately describe the other approaches and includes some good links to try those?
Sorry about the font.
It’s an amazing introduction (if people prefer video like tutorial)
12 Likes
Can a VAE’s encoder be used as a prior for a GAN’s discriminator or generator?
If using the encoder network parameters as a prior means using it as a pretrained model, then it won’t work as a generator, and might actually overpower the generator if used as a discriminator.
However, there is a paper that explores an idea on similar lines you may want to check out, converting the decoder into a shared decoder/generator, using the same latent vector outputs from the encoder, which then competes against a discriminator: https://arxiv.org/abs/1512.09300
1 Like
This is an extremely well written post ![]() Very informational and a joy to read
Very informational and a joy to read ![]()
I am not sure I imagine this correctly. During training the RNN would output the means and standard deviations, we sample from them and the decoder decodes the output from the values? How might a generation look? We sample the encoded state, feed it to the decoder and then for the next step feed the output to the encoder as input? The encoder gives us the means and standard deviations, we sample, decode, feed it as input for the next step, and so on?
I also have another question I am not sure how to phrase it. The KL divergence is calculated over what set of values? Does it strive to bring each mu and sigma for each value in an encoding to be as close to 0 and 1 for examples across all classes? Or is it happy for say the first value in an encoding to for digit 1 to have this mu and sigma different different from 0 and 1 as long as this is offset to some extent by the mu and sigma for examples from another class? As in, is the KL divergence trying to make it seem as if all the encoding values for all classes are sampled from the standard normal (say within a batch) but there can be variation in mu and sigma across classes? I am not sure even if this question makes sense - maybe both approaches that I describe are actually equivalent.
Anyhow - sorry for bombarding you with not very clear questions!
Would like to thank you again for the blog post and say that it is superbly written.
1 Like
Yes I think so - the opening paragraph of the quoted post might even make a good intro! ![]()
1 Like
The RNN part at the end really should have been better clarified, just made an edit, apologies. We don’t use the many to many architecture here, we use a modified sequence to sequence architecture instead, where the entire input is processed by the encoder into a final hidden state before any kind of decoding. This final hidden state gets passed through a linear layer to get the mu and sigma vectors . You sample, get a new vector, and this is what you actually pass in to the decoder (after passing through another linear layer to get right dimensions) to initialize its hidden state, passing decoder outputs through a linear layer+softmax, sampling, and feeding in new output to decoder (never running through the encoder), something akin to this (linear layers omitted)
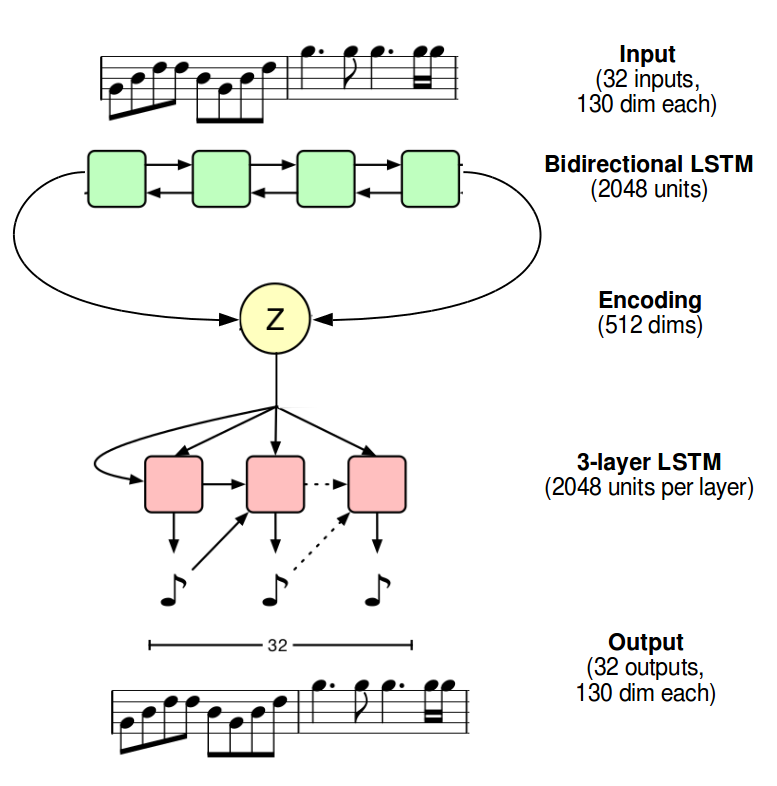
It’s basically the standard seq2seq architecture, except we modify the final hidden state in the middle before handing over to decoder.
The MusicVAE paper has a good explanation of this process for discrete data, see the 2-bar melody architecture in the appendix: https://nips2017creativity.github.io/doc/Hierarchical_Variational_Autoencoders_for_Music.pdf
The KL loss won’t tolerate any variation across classes, quite the opposite, it wants the vectors of samples from each and every class to have mu and sigma 0 and 1 (which is why we get the scattered encoding when we use pure KL loss, the samples of each and every class are scattered all over the place from the origin). The KL loss works individually for each latent vector, if for three 1-D latent vectors (read: just a number), you have mean vectors [[2], [0], [2]], the first and last vector will still be penalized, regardless of what class they’re from, regardless of the fact that in this three-sample batch the “overall” mean is 0.
We do end up with variation in mu and sigma in the final vectors on a class basis, but that’s due to the reconstruction loss wanting to keep them distinguishable, it’s the KL loss’s job to force them to be similar and close to each other.
I hope this helped!
6 Likes
This was extremely helpful, thank you ![]() So it is as if two opposing forces were fighting with each other - the KL divergence wants everything to seem as if it was sampled from standard normal but the reconstruction loss pulls the other way, trying to pack as much information in the encoding to help with reconstruction?
So it is as if two opposing forces were fighting with each other - the KL divergence wants everything to seem as if it was sampled from standard normal but the reconstruction loss pulls the other way, trying to pack as much information in the encoding to help with reconstruction?
Maybe I am reading too much into this but if we have a 3-D latent vector, KL divergence will still push the mu and sigma for each element towards 0 and 1? Or will it be satisfied with the mu and sigmas offsetting each other as long as the whole vector seems to be sampled from a standard normal? I am thinking it is a regularizing force that acts on each element independently, even within a vector, but maybe I am wrong ![]()
Thank you so much again for your wonderful article and for the answers.
It is indeed how I interpret it, two opposing forces, one wanting them as far apart for easy reconstruction but poor interpolation, the other as close as possible for easy interpolation but with little actual structure. Balancing them, we get vectors with good realistic structure, that’s also interpolatable.
You have it right, it acts on each element independently as well, if that weren’t the case, it could do something weird like mean [10, -5, -5], which does have “overall” mean 0 but is clearly not even close to the origin. For the sake of intuition, don’t think of it so much as making the mu and sigma 0 and 1 as much as “these vectors need to be as close to the origin within a certain radius sigma”.
Happy to help!
1 Like
Thank you very much for your answer. This has been extremely helpful
1 Like