Thanks. I will check that out.
1 Like
For the older version, we can put Counter(data.train_ds.y) to get count of labels per train or valid. Does anybody know what’s equivalent to that with the datablock API for fastai2?
Thanks,
Yup … len(dls.train.vocab[1])
1 Like
Regarding the difference between untar_data and download_data, this is what I gathered by looking at the documentation:
-
download_data: For downloading fastai files from a fastai url to the appropriate local path. -
untar_data: For downloading files from a Fastai url or custom url and extracting to folder indest(argument of the function)
1 Like

Assuming you are doing a classification problem, if you want the number of classes it is: dls.c
If you want the number of samples in your training dataset: len(dls.train_ds)
If you are looking to get a count for each of the unique classes in your training dataset, then there are probably multiple ways. For example, I’m using a DataFrame and can do this:
dls.items['label'].value_counts()
… or even something like this would work:
Counter([y.item() for x,y in dls.train_ds ])
Not sure if there is a easier one-liner or if it depends on your datasource.
Hi @wgpubs are we doing today’s session ? If yes, I would like to propose couple of topics:
- Understanding intuition behind Embeddings in vision, collab filter and nlp domains (word embeddings).
- One Hot Encoding and its application in different domains.
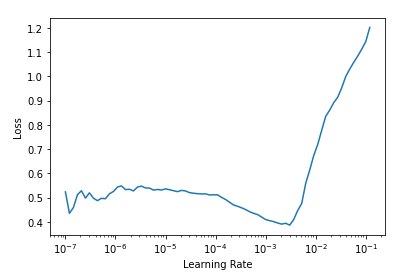
- A better understanding of lr_finder, freeze and unfreeze of models and how to choose in different applications. The example that jeremy showed in class. had a nice steep descent that ended in a min value. However, there could be other scenarios – see attached image where steepest and min loss could be very different. In the attached example, the steepest lr_steep was 2.51e-07 while lr_min was 3.02e-04. How to choose the correct lr is such scenarios or others.
- Cross Entropy and other popular losses used in different domains.
1 Like
Yup. 25 mins 
1 Like
Ok folks … we’ll be starting in 15 mins.
Zoom link is at top and also here: https://ucsd.zoom.us/j/98630190281
1 Like
Anyone else having issues with this zoom link? I’m redirected to UC San Diego site. Sorry if this is a noob question…
–
Edit: it’s working for me on my private laptop. My corp laptop was blocking Zoom desktop client.
@steef, did you click on this?
I’ve just joined the meeting too, I didn’t have any problems.
Edit: ok 
1 Like
Thanks Butch- I was clicking on that. Somehow the Zoom client isn’t working on my corp laptop but it’s working now on my personal machine.
1 Like
I think google banned zoom for its employees due to privacy concerns…
1 Like
Glad you got it working steef! Sorry I didn’t see this earlier but its hard jumping back-and-forth between the zoom client and the forums :). Posting the discussion to youtube now …
1 Like
I promised some links/resources from last night’s discussion:
Pandas merge, join, concatentate:
- https://pandas.pydata.org/pandas-docs/stable/user_guide/merging.html
- https://chrisalbon.com/ (lots of Pandas recipes and a bung of other good stuff)
Embeddings:
The two big things to know about embeddings is that a) they are learned and b) are interpretable. We use them because they allow us to provide a more nuanced representation of the thing they represent.
For example, take a column in a .csv file that represents the day of week (Sunday, Monday, etc…). We can represent this by a single number sure, but often that won’t allow us to really infer what a particular day means in the context of whatever task we are running. Much better is it to allow it to be represented by a bunch of numbers, that are learned as the model improves, and then do some analysis to see what they actually mean. And they will prove meaningful because they were learned.
How big to make these embeddings?:
Not sure offhand :). Look at the source code … and if anyone has this info, lmk and I’ll update my post with gratitude!
LR Finder and learning rate selection:
These are my notes from previous courses that I think still hold true to today (if not, please correct me :))
After running learn.lr_find(), you want to look for the strongest downward slope that is sticking around for awhile. If you are not sure what that is, try multiple learning rates to see what works best. Remember to save your model periodically using learn.save() so that you can reload it at that checkpoint if you are testing various learning rates.
How to select the LR:
Sylvain says, "find the bottom and go back 10x
Jeremy says, "find the steepest section
Both say, “its good to also try 10x less and 10x more”
3e-3 is a good default learning rate that works most of the time.
Use learn.summary before/after unfreezing to see what, and how many, parameters are being “trained” (e.g., updated via backprop). Some kinds of layers like batch norm are always set to train and also note that there are several layer types that will always be false because they don’t contain any learnable parameters (they are simply calculations on them). These include your non-linears (ReLu), dropout, max pool, flatten, etc…
How to select the LR AFTER unfreezing:
A good practices is to set the lr_max = to a slice (e.g., slice(1e-6, 1e-4)), where the 2nd part is ~5-10x smaller than your initial LR used when training your fozen model (e.g., 1e-3 becomes 1e-4) and the 1st part is set to a point well before things started getting worse.
Jeremey tends “to look for just before it shoots up and go back about 10x for the first part of the slice and for the second half of the slice, take the LR for the frozen part and divide by 5 or 10.”
Jeremy also says, “for my top learning rate I normally pick 1e-4 or 3-e4 … it always works pretty well.” So this for example: slice(3e-5, 3-34).
Another good idea is to look at the learn.fine_tune code and see the numbers they are using. They are the result of a lot of experience, trials, and errors, and have proven effective … so they are a good starting point.
Ways to set lr_max:
-
lr_max = 3e-3says, "set the LR to 3e-3 for all layer groups -
lr_max = slice(lr)says, "set the last layer group’s LR =lr, and all previous groups tolr/3 -
lr_max = slice(1e-6, 1e-4)says, “train the very first layers at a learning rate of 1e-6, the very last at 1e-4, and distribute the other layer groups in between equally between those two values.”
How many “layer groups” are there?
Run len(learn.opt.param_groups) and it will tell you.
Remember than you can define how the layers in a model are split up. In fastai, the body of a pret-trained model is usually divided into two layer/param groups while a 3rd is created for your custom head.
8 Likes
FYI: Just added the recorded week 6 discussion if anyone is interested.
1 Like
I know this was supposed to be a hint, but I’m lost on how to proceed.
Tokenizer and functions like Tokenizer.from_df don’t give actual examples on how to do a simple transformation. show_batch docs doesn’t show the return type, the source instead does indicate that the return type is a dataframe but show_batch is supposed to create that. So It’s unclear what the actual error is…
Can someone help me through a simple usecase: Suppose our usecase is to uppercase a sentence, according to NB 11 this would be something like this
- Create a Transform (
setups()is not included since no setup needed)
class Upper(Transform):
def encodes(self, x):
return x.upper()
def decodes(self, x):
return x.lower()
- Create a Pipeline if multiple transforms are needed:
tfms = Pipeline([u])
- Pass transformer to dataloader
dls_lm = DataBlock(blocks = TextBlock(tok_tfm = u,
is_lm=True),
get_items = get_file,
splitter=RandomSplitter(valid_pct=0.2))
This would run without errors,
- But at show_batch() it still breaks apart
dls_lm.show_batch(max_n=2)
Gives the following:
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-196-c63ae8c01a09> in <module>
----> 1 dls_lm.show_batch(max_n=2)
~/.local/lib/python3.6/site-packages/fastai2/data/core.py in show_batch(self, b, max_n, ctxs, show, unique, **kwargs)
93 if b is None: b = self.one_batch()
94 if not show: return self._pre_show_batch(b, max_n=max_n)
---> 95 show_batch(*self._pre_show_batch(b, max_n=max_n), ctxs=ctxs, max_n=max_n, **kwargs)
96 if unique: self.get_idxs = old_get_idxs
97
~/.local/lib/python3.6/site-packages/fastcore/dispatch.py in __call__(self, *args, **kwargs)
96 if not f: return args[0]
97 if self.inst is not None: f = MethodType(f, self.inst)
---> 98 return f(*args, **kwargs)
99
100 def __get__(self, inst, owner):
~/.local/lib/python3.6/site-packages/fastai2/text/data.py in show_batch(x, y, samples, ctxs, max_n, trunc_at, **kwargs)
111 @typedispatch
112 def show_batch(x: LMTensorText, y, samples, ctxs=None, max_n=10, trunc_at=150, **kwargs):
--> 113 samples = L((s[0].truncate(trunc_at), s[1].truncate(trunc_at)) for s in samples)
114 return show_batch[TensorText](x, None, samples, ctxs=ctxs, max_n=max_n, trunc_at=None, **kwargs)
115
~/.local/lib/python3.6/site-packages/fastcore/foundation.py in __call__(cls, x, *args, **kwargs)
39 return x
40
---> 41 res = super().__call__(*((x,) + args), **kwargs)
42 res._newchk = 0
43 return res
~/.local/lib/python3.6/site-packages/fastcore/foundation.py in __init__(self, items, use_list, match, *rest)
312 if items is None: items = []
313 if (use_list is not None) or not _is_array(items):
--> 314 items = list(items) if use_list else _listify(items)
315 if match is not None:
316 if is_coll(match): match = len(match)
~/.local/lib/python3.6/site-packages/fastcore/foundation.py in _listify(o)
248 if isinstance(o, list): return o
249 if isinstance(o, str) or _is_array(o): return [o]
--> 250 if is_iter(o): return list(o)
251 return [o]
252
~/.local/lib/python3.6/site-packages/fastai2/text/data.py in <genexpr>(.0)
111 @typedispatch
112 def show_batch(x: LMTensorText, y, samples, ctxs=None, max_n=10, trunc_at=150, **kwargs):
--> 113 samples = L((s[0].truncate(trunc_at), s[1].truncate(trunc_at)) for s in samples)
114 return show_batch[TensorText](x, None, samples, ctxs=ctxs, max_n=max_n, trunc_at=None, **kwargs)
115
AttributeError: 'L' object has no attribute 'truncate'
u is not a valid Tokenizer transform. It needs to have a signature that matches what is described here.
See BastTokenizer as an example of how this is done.
Sorry, that was a typo. u should’ve been tfms. Copying the BaseTokenizer and passing it to Tokenizer() resolves the error, however it calls the decodes() and encodes() of the Tokenizer class.
To create custom decodes & decodes should we subclass Tokenizer? If so then what’s the purpose of subclassing Transform according to this FastAI example from nb11
class NormalizeMean(Transform):
def setups(self, items): self.mean = sum(items)/len(items)
def encodes(self, x): return x-self.mean
def decodes(self, x): return x+self.mean
More specifically what’s the difference between a Transform and Tokenizer? Is a Transform not supposed to be passed directly to a Data Loader, but instead should be wrapped into a Tokenizer and then passed?
Thank you
another point of clarification the signature described there is BaseTokenizer(split_char=' ', **kwargs). Yet the signature for Spacy is SpacyTokenizer(lang='en', special_toks=None, buf_sz=5000). Both signatures don’t match – what do you mean when you say “it needs to have a signature that matches”?
Should all Tokenizers implement or extend BaseTokenizer(split_char=' ', **kwargs)? Sorry I’m really lost on the language.
Another point of confusion the tutorial says:
" A tokenizer is a class that must implement a pipe method. This pipe method receives a generator of texts and must return a generator with their tokenized versions. Here is the most basic example:"
Is this pipe the same as Pipeline from nb11?