update:
The CUDA version is not compatible with the torch version. Not sure what to do since creating a new venv does not handle system level software and I believe upgrading cuda would require administrator permission to the shared instance.
I did not realize the discrepancy between
print(torch.version.cuda) and nvcc --version
Paperspace consistently uses the CPU for my code unless I am trying a fastAI example with clean data. I am trying to train a model to cull images. I mounted a large amount of data to an AWS S3 bucket. If I run the FastAI examples, it works great. I realized that every time I define learn, it sets the device as the cpu so I use this trick to change the device to the GPU:
learn = vision_learner(dls, resnet34, metrics=accuracy)
# learn.model = learn.model.to(device)
learn.to('cuda')
print(next(learn.model.parameters()).device)
Which returns cuda:0, yet it still only uses the CPU.
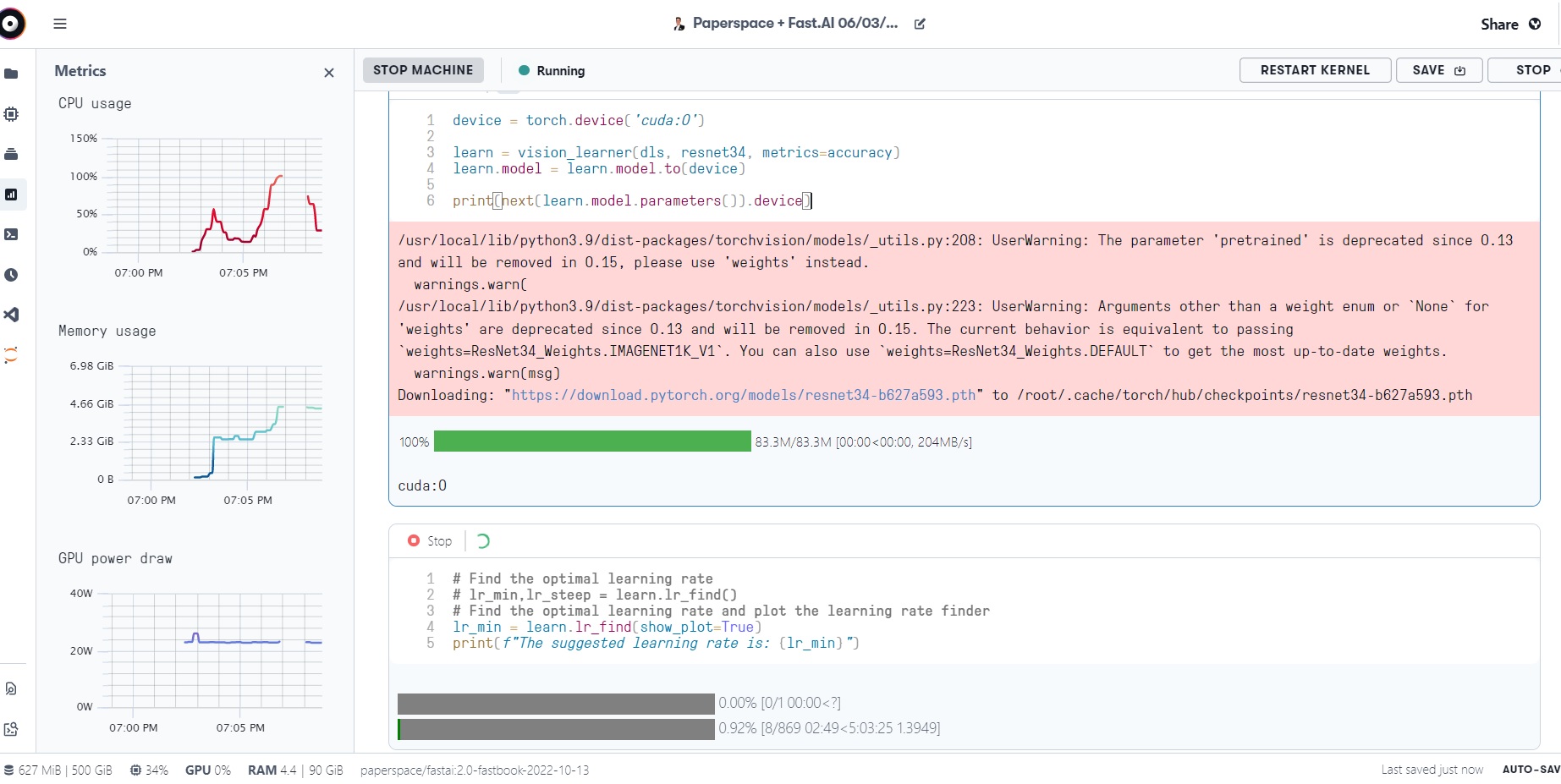
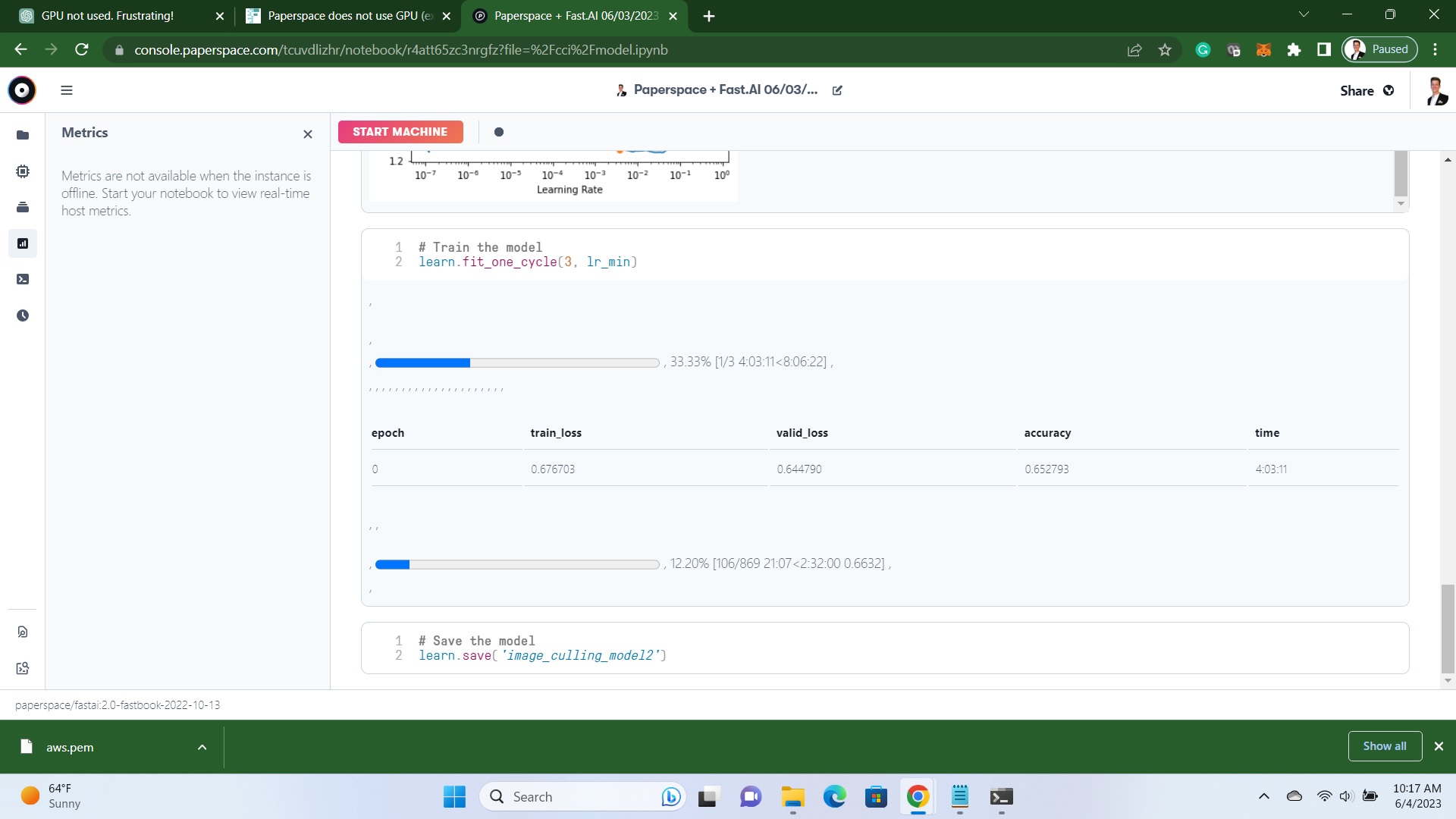
When I try to find the learning rate it takes hours and only uses the CPU.
Any advice or resources would be greatly appreciated. This was the only tutorial I could find from Jeremy for Paperspace but it brought me to this dead link: http://course-v3.fast.ai/start_gradient.html
my code to train a model to cull photos:
from fastai.vision.all import *
import pandas as pd
import torch
import fastai
! [ -e /content ] && pip install -Uqq fastbook
import fastbook
fastbook.setup_book()
print(torch.cuda.is_available())
print(torch.version.cuda)
print(torch.__version__)
to_be_culled_df = pd.read_csv('/datasets/aws/v3/corrected_paths2.csv', encoding='utf-8')
to_be_culled_df['Image Path'] = to_be_culled_df['Image Path'].str.replace('/dir_in_docker', '/datasets/aws/v3')
# Extract filename from 'Image Path'
to_be_culled_df['filename'] = to_be_culled_df['Image Path'].apply(lambda x: os.path.split(x)[-1])
# Now sort by 'Project Name', 'Report Number', and 'filename'
to_be_culled_df = to_be_culled_df.sort_values(by=['Project Name', 'Report Number', 'filename'])
# Reset the index of the dataframe
to_be_culled_df = to_be_culled_df.reset_index(drop=True)
# Define function to retrieve the image files
def get_x(row):
return row['Image Path']
# Define function to retrieve the image labels (Survived column)
def get_y(row):
return row['Survived']
dblock = DataBlock(blocks=(ImageBlock, CategoryBlock),
splitter=RandomSplitter(valid_pct=0.2, seed=42),
get_x=get_x,
get_y=get_y,
item_tfms=[Resize(460, method='pad', pad_mode='zeros')],
batch_tfms=aug_transforms(size=224, max_rotate = 0.0, flip_vert=True))
# Create a DataLoader
# dls = dblock.dataloaders(to_be_culled_df, num_workers=4)
dls = dblock.dataloaders(to_be_culled_df, num_workers=4)
dls.device = 'cuda:0'
# Display a batch to check if everything is alright
dls.show_batch(max_n=4, nrows=1)
from fastai.torch_core import default_device
print(default_device())
learn = vision_learner(dls, resnet34, metrics=accuracy)
learn.to('cuda')
print(next(learn.model.parameters()).device)
lr_min = learn.lr_find(show_plot=True)
print(f"The suggested learning rate is: {lr_min}")
# Train the model
learn.fit_one_cycle(7, lr_min)
# Save the model
learn.save('image_culling_model2')
Finding a learning rate took 20 minutess and only uses CPU. One epoch takes hours and zero GPU utilization. I changed from the default batch size to 64 and it still takes hours, I will try a larger number next but not hopeful.
Send help and cookies