5. Analysis
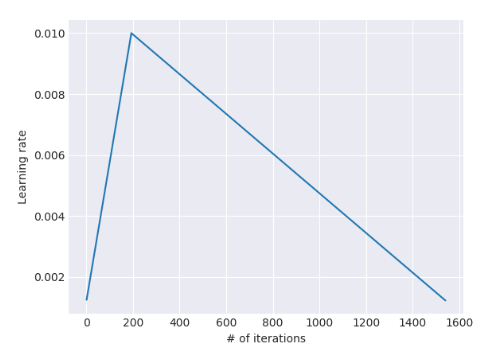
为了评估每项贡献所产生的影响,我们进行了一系列的分析和消融。我们对 IMDb、TREC-6 和 AG 这些语料库进行实验,它们在不同的任务、流派和大小上具有典型代表性。在所有实验中,我们将 10% 的训练集划分出来,并使用单向 LM 在此验证集上展示错误率。我们微调分类器 50 轮(epoch),采用早停法训练除了 ULMFiT 以外的所有方法。
Low-shot learning
迁移学习的主要好处之一,是能够为只有少量标签的任务训练模型。我们采用两种设置中对不同数量的标记样本进行 ULMFiT 的评估:只有标记样本可用于微调 LM(“监督”)以及所有数据都能获取到并可用于微调 LM(“半监督”)。我们将 ULMFiT 与从头开始的训练进行比较(对于基于超列的方法从头训练是必要的)。我们拆分出训练数据的平衡部分(balanced fractions  ),保持验证集固定不变,并使用与之前相同的超参数。图3中展示了结果。
),保持验证集固定不变,并使用与之前相同的超参数。图3中展示了结果。
图 3: 监督和半监督的 ULMFiT vs. 从头开始训练不同数量的IMDb,TREC-6和AG训练样本(从左到右)的验证错误率。
在 IMDb 和 AG 上,受监督的 ULMFiT 仅用100个标记样本就分别能达到用 10 倍以上和 20 倍以上的数据从头开始训练的性能表现,这清楚地表明了通用领域 LM 预训练的好处。 如果我们允许ULMFiT 也使用未标记的样本( IMDb 为 50k,AG 为 100k),在 100 个示例样本时,分别能与在 AG 上以 50 倍以上和 IMDb 上以 100 倍以上的数据从头开始训练得到的性能相同。 在 TREC-6 上,ULMFiT 比从头开始训练有显著提高,但因为样本更短更少,所以监督和半监督的 ULMFiT 结果相似。
Impact of pretraining
我们在表 4 中展示了没有用预训练和用了在 WikiText-103 的预训练的比较结果。预训练对于中小型数据集是最有用的,这种数据集在商业应用中最常见。但即使对于大型数据集,预训练也可以提高性能。
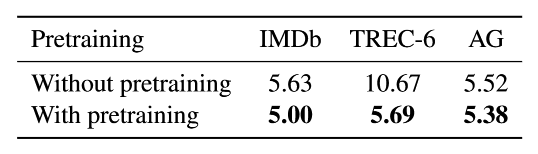
表 4: ULMFiT 有预训练和无预训练时的验证错误率。
Impact of LM quality
为了说明选择合适的 LM 的重要性,我们在表 5 中将普通 LM 与没有任何 dropout 但有相同超参数的 LM 、使用精调的 dropout 参数的 AWD-LSTMLM 进行比较。使用我们的微调技术,即使是常规的 LM 在更大规模的数据集上都达到了惊人的良好性能。在规模较小的 TREC-6 上,没有dropout 的普通 LM 存在过度拟合的风险,这会使性能降低。
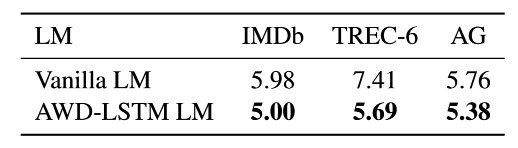
表 5: ULMFiT 使用普通的 LM 和 AED-LSTM LM 的验证错误率。
Impact of LM fine-tuning
我们在表 6 中将没有微调的模型与微调整个模型(‘Full’),以及有或没有差异化微调(‘Discr’)和斜三角学习率(‘Stlr’)相比较。微调 LM 对较大的数据集是最有利的。‘Discr’ 和 ‘Stlr’ 在所有三个数据集上都提高了性能,并且对于较小的 TREC-6 是十分必要的,此时常规的微调没有益处。
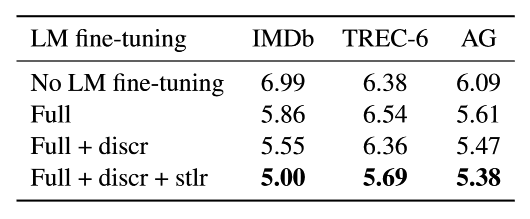
表 6: ULMFiT 使用不同变种的 LM 微调方法的验证错误率 。
Impact of classifier fine-tuning
我们对比了从头开始训练、微调整个模型(‘Full’)、只微调最后一层(‘Last’)、链解冻(‘Chain-thaw)'和逐渐解冻(‘Freez’)。并进一步评估了差异化微调(‘Discr’)和斜三角学习率(‘Stlr’)的重要性。我们将后者用激进的余弦退火方案(‘Cos’)作为替代并进行比较。对于 ‘Discr’ 我们设置学习率 \eta^{L}=0.01 。对于 ‘Chain-thaw’ 设置最后一层的学习率为 0.001,所有其他层为 0.0001。其他的学习率设为 0.001。表 7 中展示了结果。
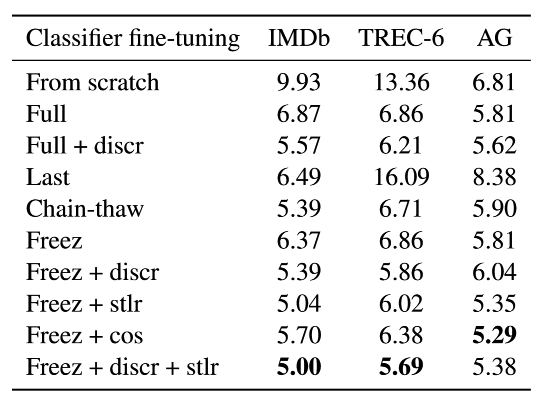
表 7: ULMFiT 使用不同方法微调分类器的验证错误率。
微调分类器的方法比从头开始训练有显著的改善,特别是在小型数据集 TREC-6 上。 CV 中的标准微调方法 “Last” 严重欠拟合,完全不能将训练误差降低到 0。‘Chain-thaw’ 在较小的数据集上的表现与其他相似,但在大型的 AG 上的表现很出色。 ‘Freez’ 与 ‘Full’ 的表现相类似。除了大型的 AG 外,‘Discr’ 一直都比 ‘Full’ 和 ‘Freez’ 的性能更优。余弦退火比起斜三角学习率在数据集大的时候表现相似,但在较小的数据集上表现不佳。最后,完整的 ULMFiT 分类器微调(最后一行)在 IMDB 和 TREC-6 上性能表现最佳,在 AG 上表现与其他相似。值得一提的是,ULMFiT 是唯一全面表现出色的方法,因此也是唯一的通用方法(universal method)。
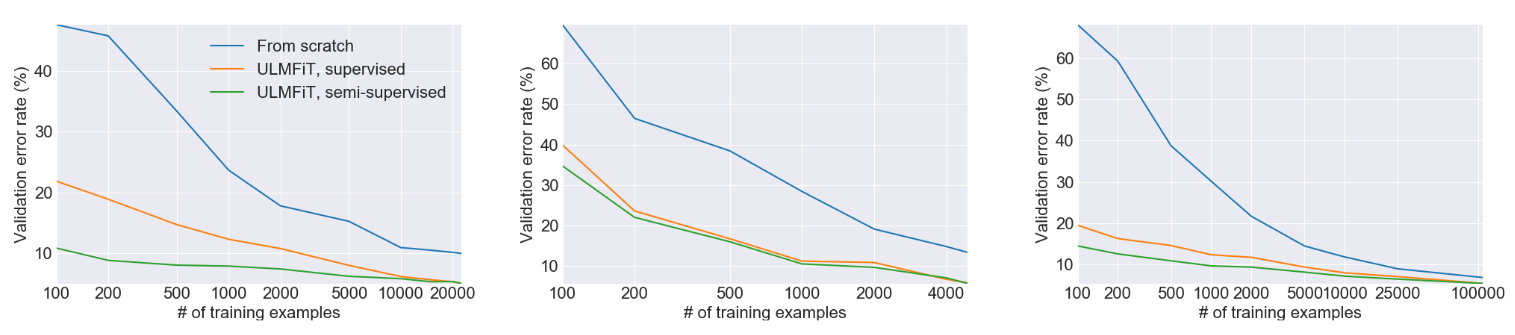
Classifier fine-tuning behavior
虽然我们的结果表明,如何微调分类器会产生显着的差异,但目前 NLP 中对归纳式迁移的微调还未被进一步探索,因为这被普遍认为是没用的。为了更好地理解我们模型的微调行为,我们在图 4 中比较了训练期间用 ULMFiT 和 ‘Full’ 微调分类器的验证误差。
图 4: 在IMDb,TREC-6和AG(从上到下)数据集上,使用ULMFiT和“Full”微调分类器的验证错误率曲线。
在所有数据集上,对整个模型进行微调可以在训练中较早地得到最低误差,例如在 IMDb 上的第一个 epoch 之后。但随着模型开始过拟合并且预训练捕获的知识开始丢失,错误也随之增加。相比之下,ULMFiT 更加稳定并且没有遭遇这种灾难性的遗忘。直到最后的 epoch,性能表现也依然保持稳定或继续提高,这展现了学习率方案(schedule)的优势。
Impact of bidirectionality
以需要训练第二个模型的代价,对正向和反向 LM 分类器的预测进行融合(ensemble),能使性能提升约为0.5~0.7。在 IMDb 上,我们将测试误差从单个模型的 5.30 降低到双向模型的 4.58。
 标记
标记