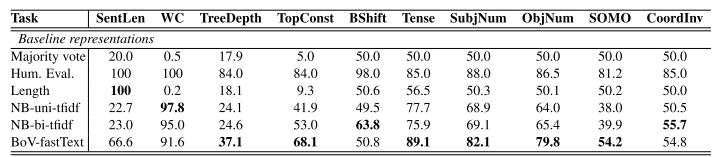
I have started reading this paper, and I am having some questions as I read through it so I was hoping somebody else has either read it or is wanting to read it and discuss the paper. So far, it is a really interesting read and I think it is a worthwhile ready, but I am having troubles with some of the results. If you look at Table 2, it shows Majority Vote
and it looks terrible, so my thought is that “Majority Vote” is probably what the authors assume the minimum value is for this field but was hoping if somebody else has read through this, you could provide your input.
I’m reading this paper now. I think that majority vote picking the single most common class or output and applying to all cases. At the end of section 2 the authors say “all sets are balanced having equal number of instances in each target class”
With sentence lenght, they claim to have 6 buckets and equal weighted. I’m guessing they used dummy vars and 5 groups. So picking on group for all classes you get 20% accuracy as displayed. For TopConst they have 20 way output and equal so 5%. For the others to the right, 50% is just guessing a single category for all of them.
Like you said, I think this is the floor. You have a binary or multi class problem and it is balanced and you guess a single class.
It is an interesting platform to “test” how well the encoder works for general problems. Have you tried to implement the techniques and compare to their data? If not, do you want to work on that together? I bet we’d learn a lot about how these architectures all work by matching the results.