Hello all.
I recently had the fortune of working with VITA, UT-Austin on a very exciting paper - APP: Anytime Progressive Pruning where we propose a new progressive pruning framework in ALMA regime that we call APP.
We answer the following question in our paper:
Given a dense neural network and a target sparsity, what should be the optimal way of pruning the
model in ALMA setting?
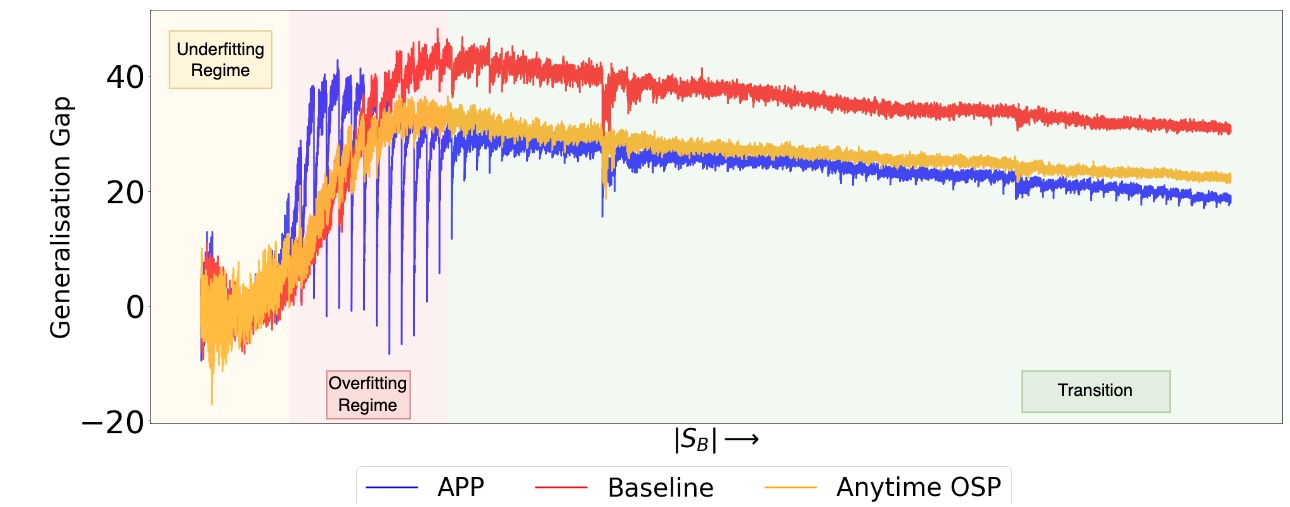
We spent a lot of time and effort for this work - training over 400 models in total, all of whose logs can be accessed on our W&B dashboard. We also find very interesting training dynamics on long sequence ALMA as shown in the plot below:
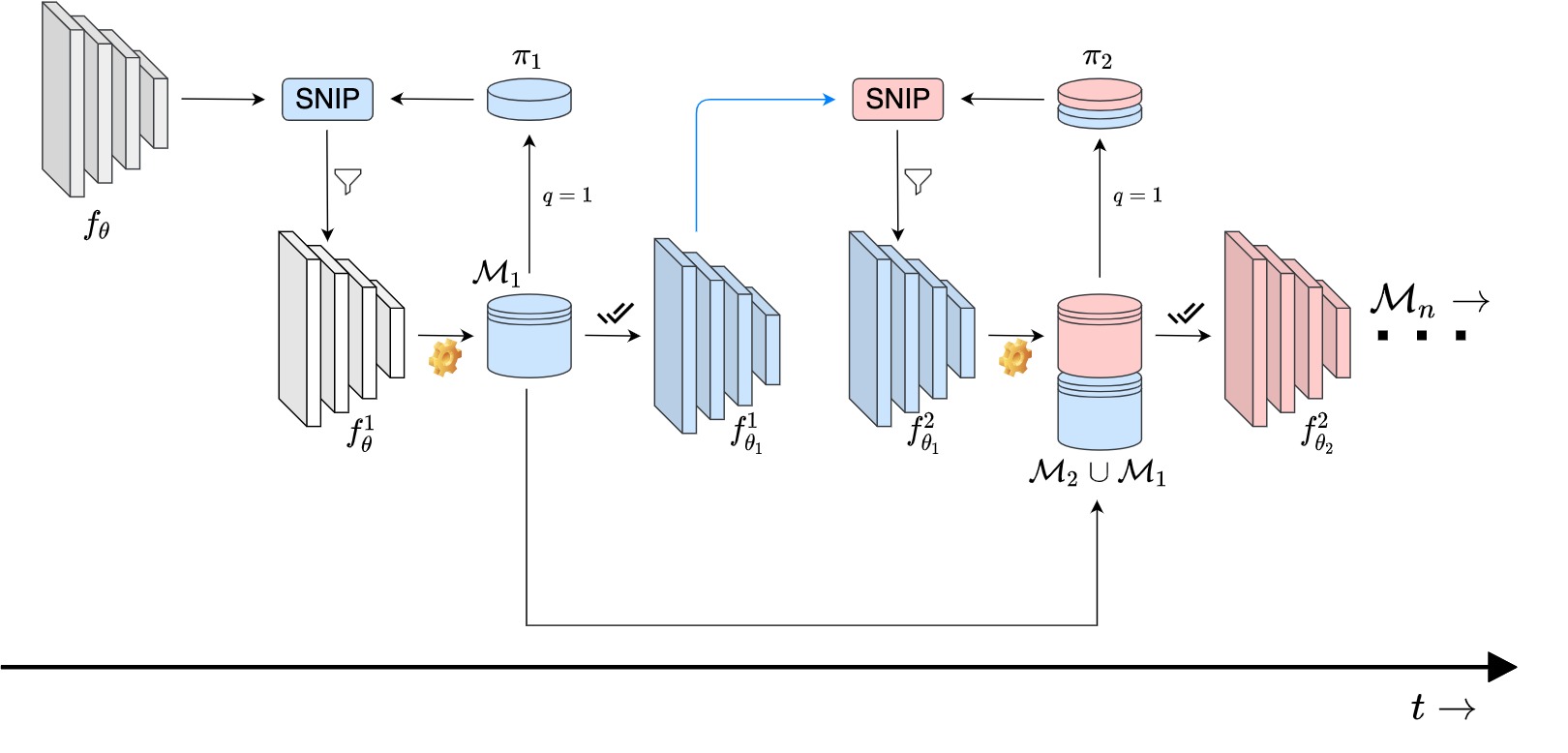
Framework design:
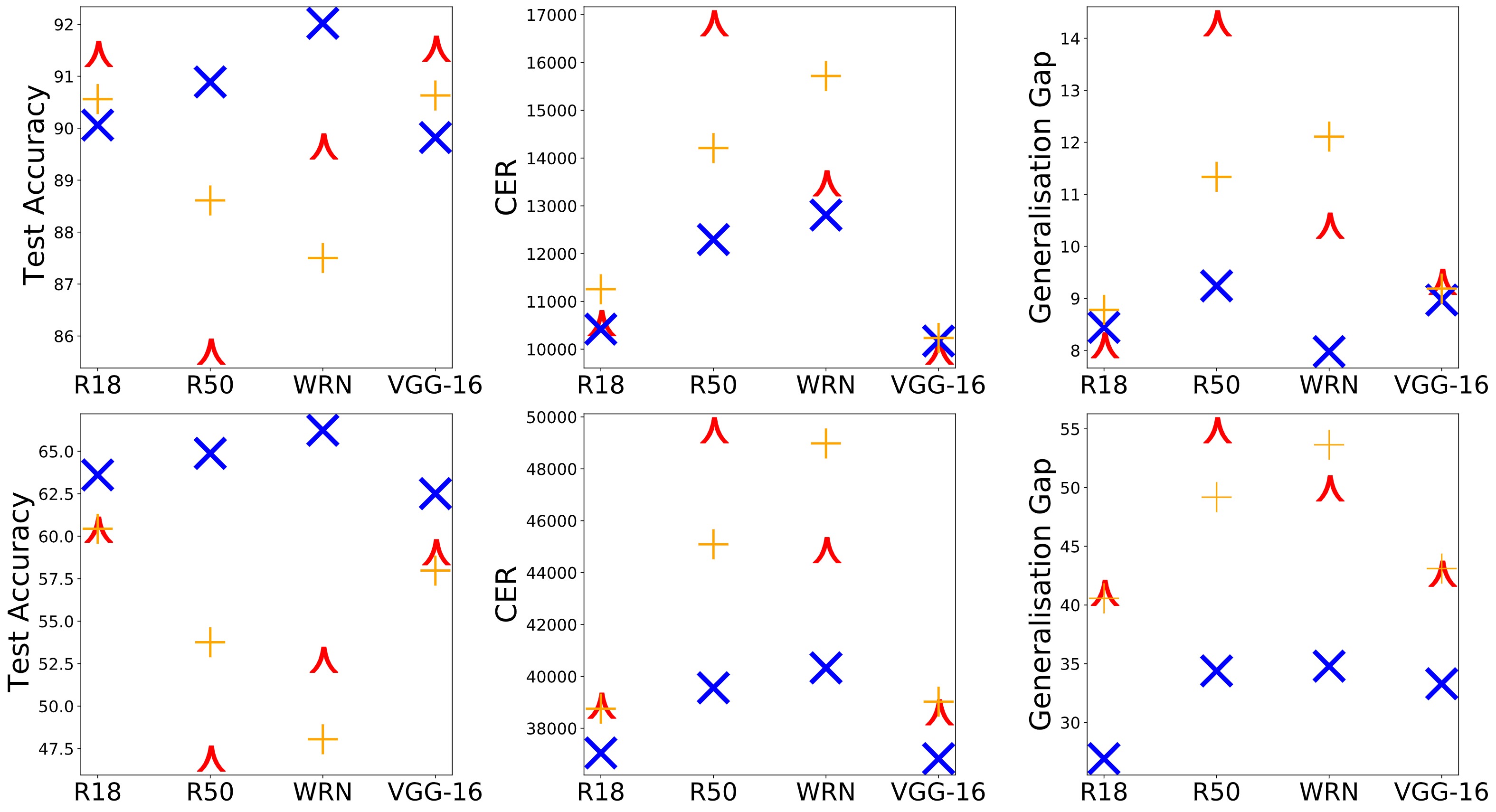
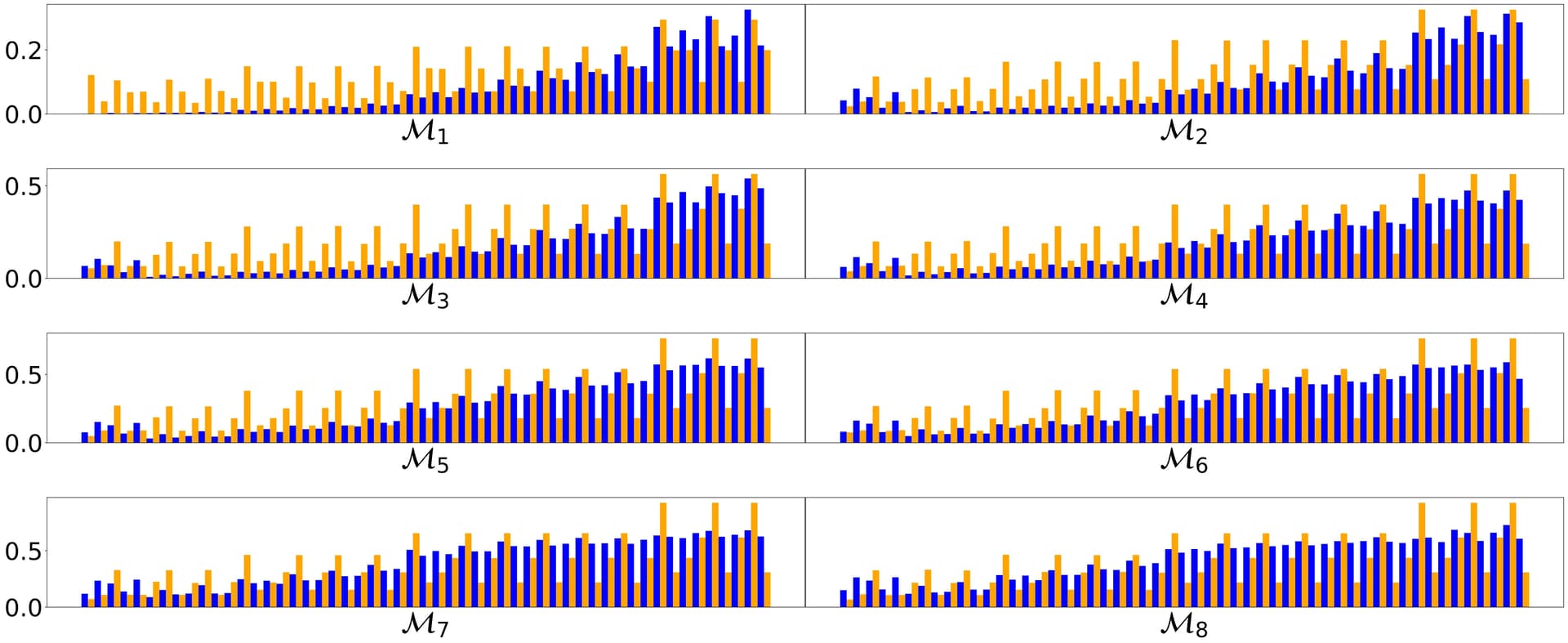
Results (\color{red}\curlywedge, \color{orange}+ and \color{blue}\times represent the baseline, Anytime OSP, and APP. First Row - CIFAR-10. Second Row - CIFAR-100. Higher Test Accuracy better, Lower CER better, Lower generalisation gap better. APP and Anytime OSP is 1/3rd the parametric complexity of the baseline.) :
Non-monotonic transition in the generalisation gap as a function of # megabatches (|S_B| = 100):
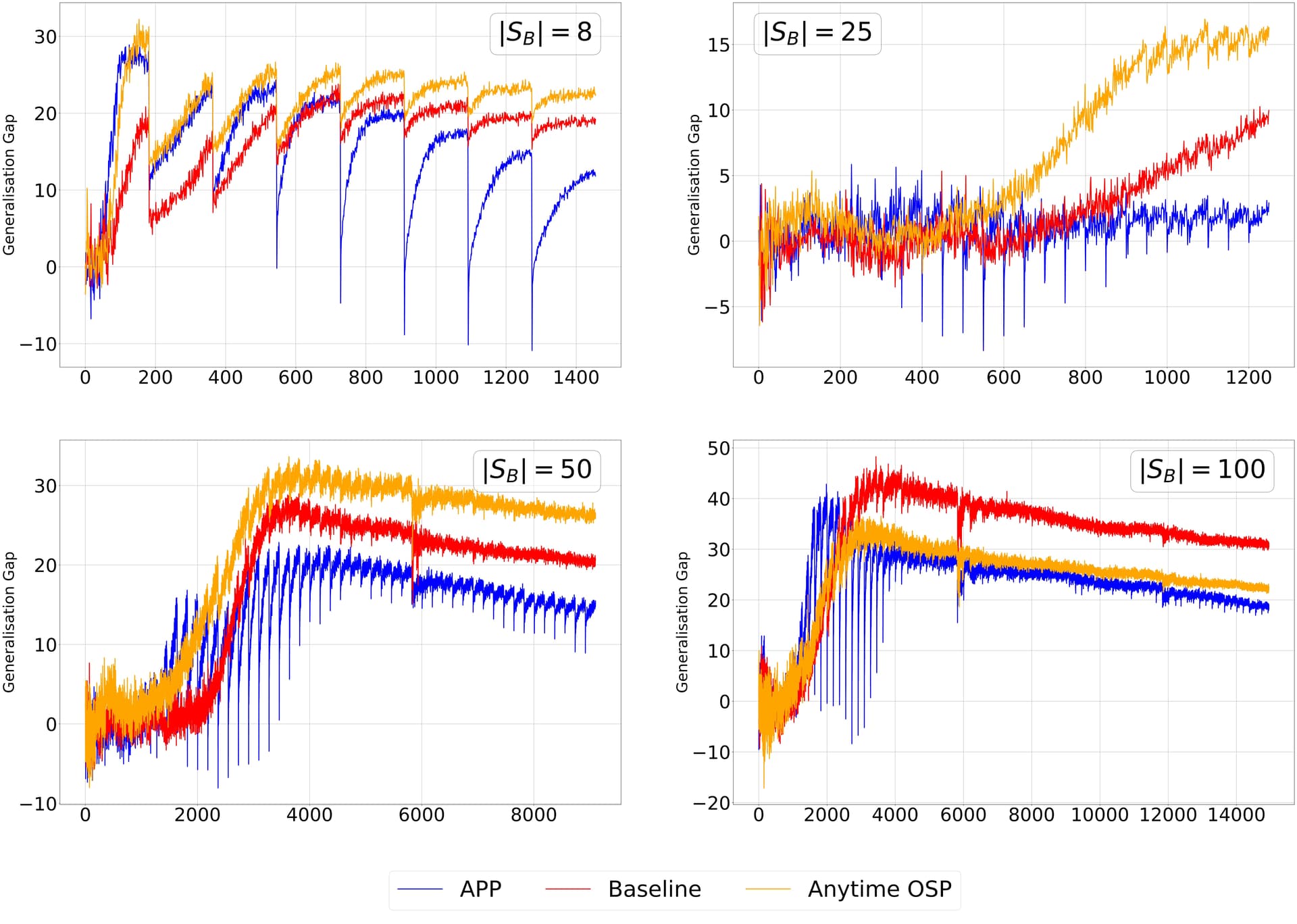
Generalisation gap as a function of number of megabatches (|S_B| represents the number of megabatches):
Layer-wise sparsity analysis for ResNet-50 on CIFAR-10 using |S_B| = 8 (\color{blue}SNIP, \color{orange}Magnitude Pruning) (\tau = 4.5)
Abstract
With the latest advances in deep learning, there has been a lot of focus on the online learning paradigm due to its relevance in practical settings. Although many methods have been investigated for optimal learning settings in scenarios where the data stream is continuous over time, sparse networks training in such settings have often been overlooked. In this paper, we explore the problem of training a neural network with a target sparsity in a particular case of online learning: the anytime learning at macroscale paradigm (ALMA). We propose a novel way of progressive pruning, referred to as \textit{Anytime Progressive Pruning} (APP); the proposed approach significantly outperforms the baseline dense and Anytime OSP models across multiple architectures and datasets under short, moderate, and long-sequence training. Our method, for example, shows an improvement in accuracy of ≈7% and a reduction in the generalization gap by ≈22%, while being ≈1/3 rd the size of the dense baseline model in few-shot restricted imagenet training. We further observe interesting nonmonotonic transitions in the generalization gap in the high number of megabatches-based ALMA. The code and experiment dashboards can be accessed at this https URL and this https URL, respectively.
Paper link - [2204.01640] APP: Anytime Progressive Pruning
We will appreciate any feedback on our work. There are a lot of open problems using this framework which would be exciting to work on if anyone wants to try their hands on it. Some of those ideas were discussed during the talks linked on this page - https://landskape.ai/publication/app/