I have this particular data distribution.
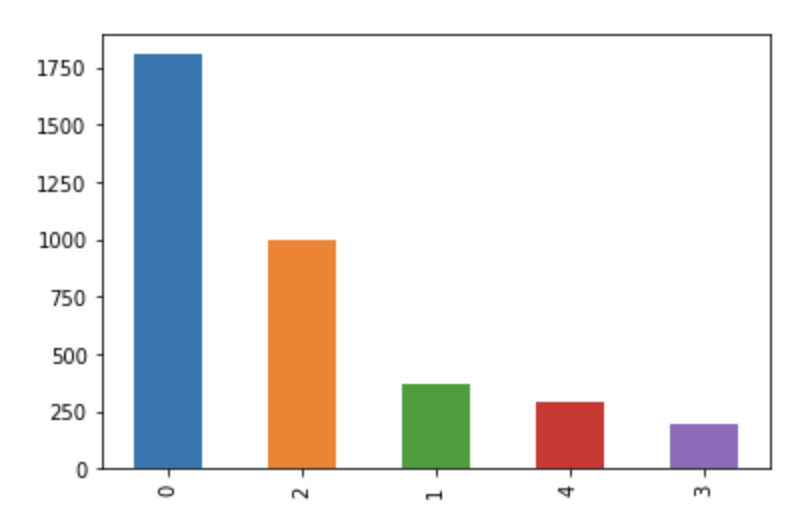
To improve my training results I thought I would use the OverSamplingCallback to re-balance the distribution. But when I use it, I get significantly worse results.
Assuming I’ve chosen good learning rates, and kept all the hyperparameters constant, is there any reason why that would be?
FYI I am using this in a regression problem rather than as a classification problem. Would this have any affect?
The following is the Oversampling callback being used:
from torch.utils.data.sampler import WeightedRandomSampler
class OverSamplingCallback(LearnerCallback):
def __init__(self,learn:Learner,weights:torch.Tensor=None):
super().__init__(learn)
self.labels = self.learn.data.train_dl.dataset.y.items
_, counts = np.unique(self.labels,return_counts=True)
self.weights = (weights if weights is not None else
torch.DoubleTensor((1/counts)[self.labels.astype(int)]))
self.label_counts = np.bincount([self.learn.data.train_dl.dataset.y[i].data for i in range(len(self.learn.data.train_dl.dataset))])
self.total_len_oversample = int(self.learn.data.c*np.max(self.label_counts))
def on_train_begin(self, **kwargs):
self.learn.data.train_dl.dl.batch_sampler = BatchSampler(WeightedRandomSampler(self.weights,self.total_len_oversample), self.learn.data.train_dl.batch_size,False)