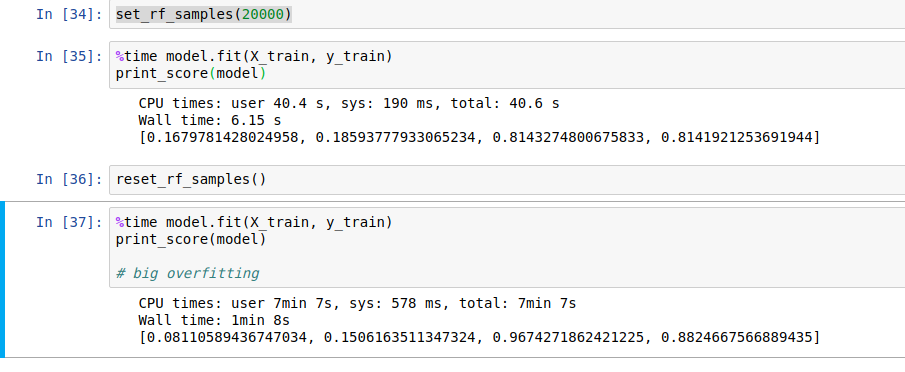
I’m training a Random Forest to predict future sales and using the set_rf_samples() function that Jeremy showed in Lesson 2 of ML1.
Using 20000 samples to train the train and test R2 scores are about the same (~0.81). If I use the whole ~350k rows of data to train the model the R2 on the test set goes up to 0.88 while on the training set it goes up to 0.97, so there’s overfitting.
Is this valid or I should look for other parameters where the ratio train set score / test set score is closer to 1, or should I try to maximize the test set score, even if I’m overfitting on the training data? I did some grid search and the hyperparameters I’m using are near the best ones it found.
Thanks!