In an attempt to address the issue, I have done the following:
stopped all other notebooks currently running
restart the Lesson2 notebook kernel
stop/restart the instance
After restarting the Lesson2 notebook, I downloaded htop (an interactive process viewer) on my instance in order to look at all of the running processes and memory usage. Initially, the Memory usage was fairly low; however, by the time I get to the following lines:
What are trn_data.shape and val_data.shape? What if you split the cell in two, so you first do val_data, and then do trn_data? Does saving just val_data work (since it’s quite a bit smaller)?
into 2 cells. What I noticed is that the memory went up to 55.2 with the first save_array (with the train data). After the save_array(model_path+ 'train_data.bc', trn_data) cell ran, the memory was sustained. So by the time I got to the cell with just trn_data = load_array(model_path+'train_data.bc'), I immediately got a memory error.
So, it does seem as if just saving the val_data would work. However, I’m not sure why I’m running into this issue and apparently others are not – do other people have greater memory?
I have the same issue on a P2 instance. But, I’m not worried about it since we already have the training data and validation data arrays loaded into memory at this point in the notebook. No need to reload them again (unless, of course, you restart your notebook and want to continue where you left off). If you want, you can add del trn_data and del val_data before the load_array() calls. That’ll free up the memory occupied by those variables before loading them back up from the saved data.
Exactly, @jeff ! You only want to run load_array() if you’re wanting to avoid waiting for get_data(), and you’ve run get_data() before and saved the results. There’s no reason to run load_array() immediately after running save_array() - you already have the array calculated, so there’s no need to load it.
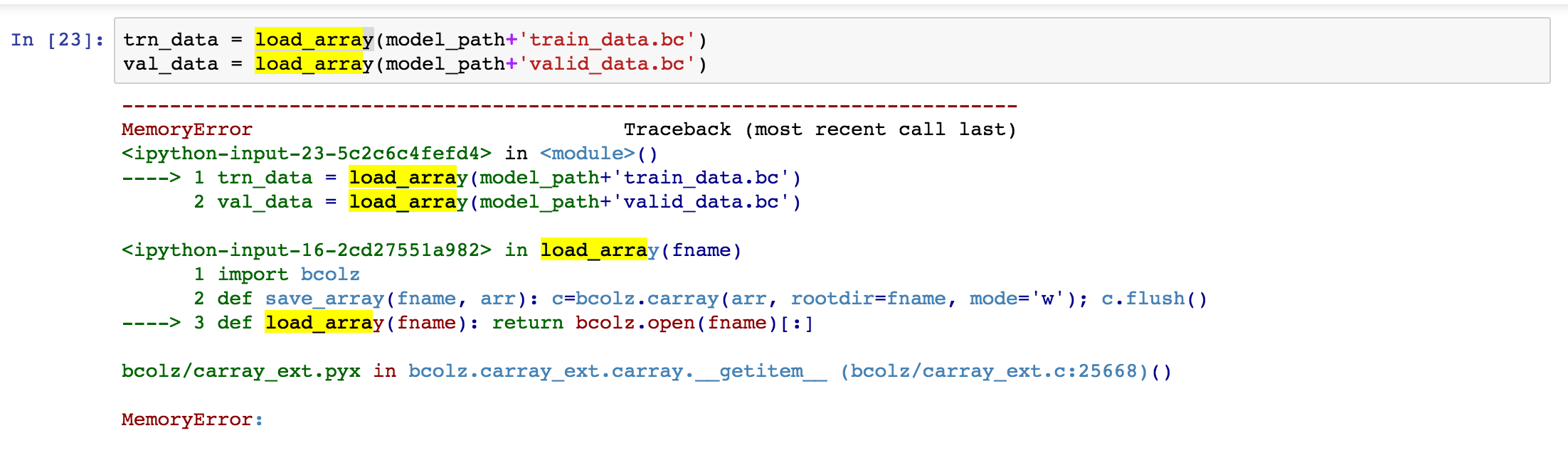
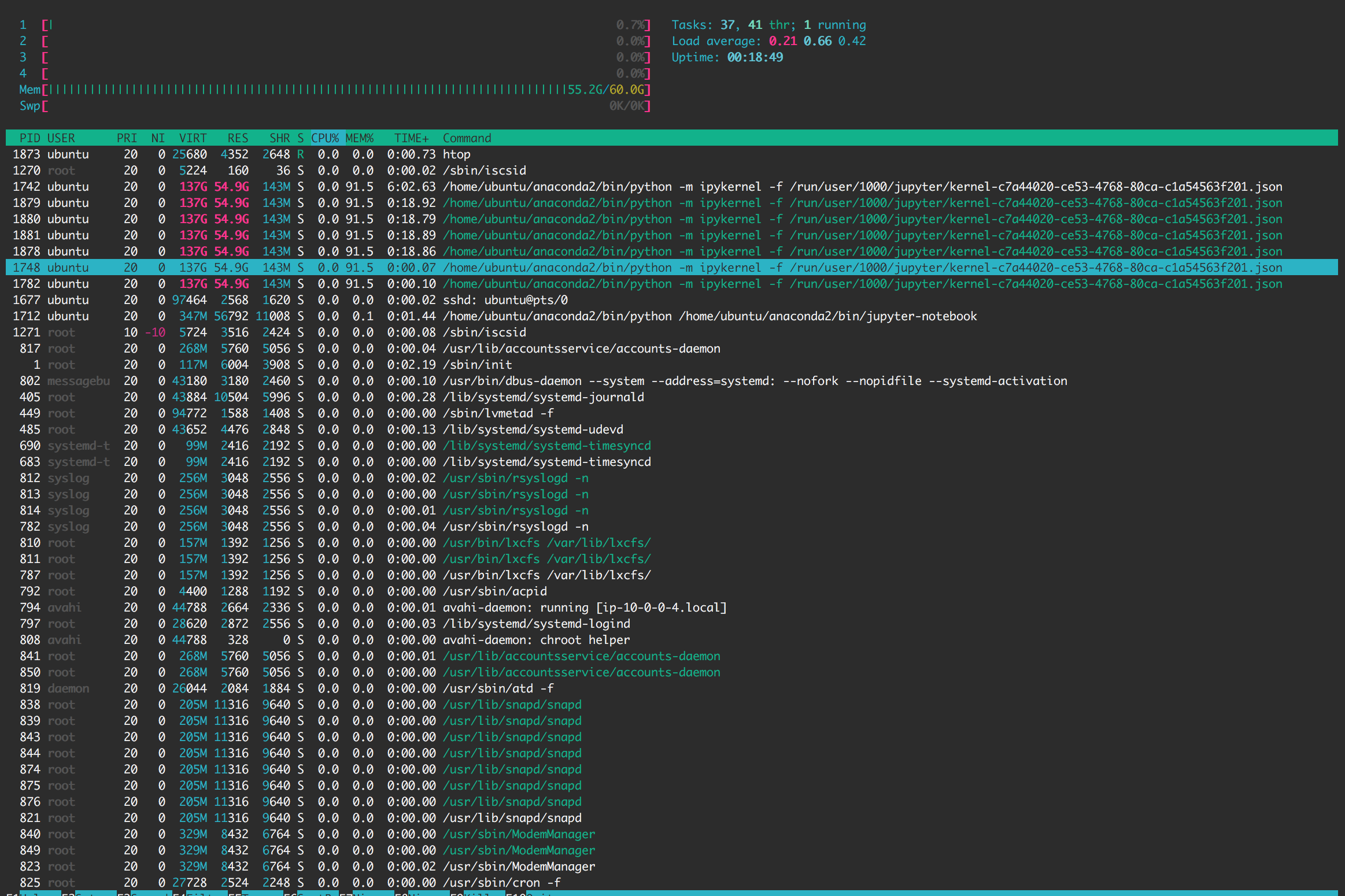
 Has anyone else run into this problem? Any ideas on ways to get around the memory issue?
Has anyone else run into this problem? Any ideas on ways to get around the memory issue?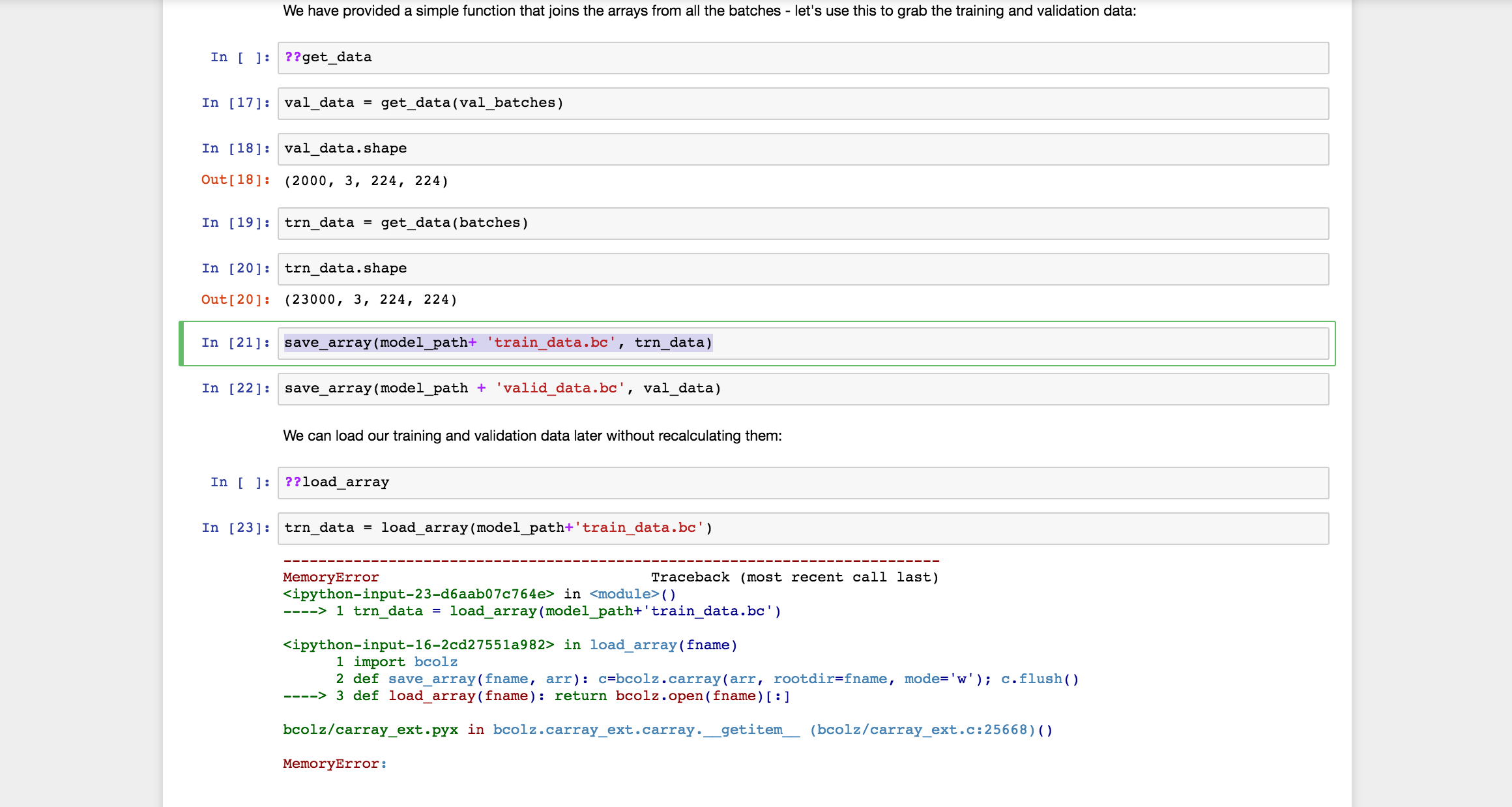
 You only want to run load_array() if you’re wanting to avoid waiting for get_data(), and you’ve run get_data() before and saved the results. There’s no reason to run load_array() immediately after running save_array() - you already have the array calculated, so there’s no need to load it.
You only want to run load_array() if you’re wanting to avoid waiting for get_data(), and you’ve run get_data() before and saved the results. There’s no reason to run load_array() immediately after running save_array() - you already have the array calculated, so there’s no need to load it.