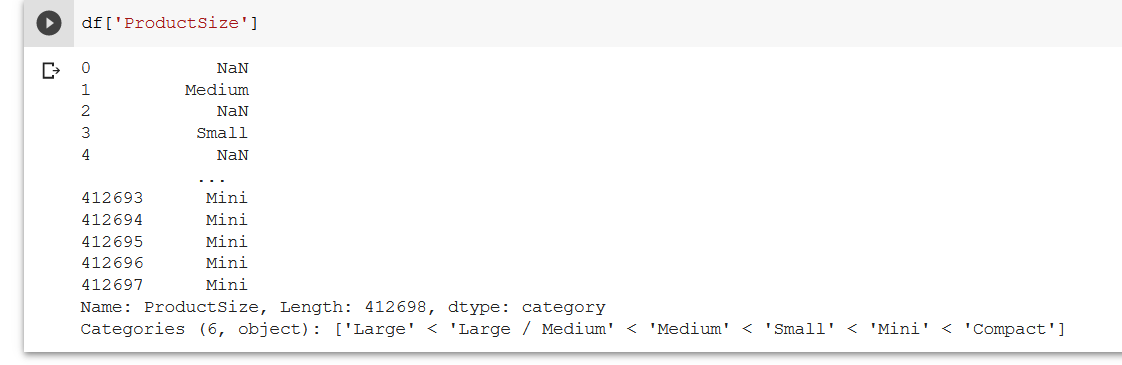
I believe that this order is backwards? “Compact” is largest and “Large” is smallest. Perhaps this doesn’t matter because the order is the same but reversed so the NN will just learn correctly anyway. But am I missing something? Is there a reason to order the data like this?
P.S. There is a single line of code you can use in Pandas to do the same thing:
It’s possible that I’m misunderstanding you, but I’m pointing to the last line of the cell output that starts with “Categories”. It shows the ordinality of the data with " ‘Large’ <‘Large/Medium’…"
My point is that it should be" ‘Large’>‘Large/Medium’… "
But I suspect it doesn’t matter because the NN just figures that out since relative positions are unchanged.
We explicitly did create an order to the categories earlier in the Jupyter notebook.
if you create an ordered category with [‘a’, ‘b’, ‘c’, ‘d’] then the underlying values will be
a=0
b=1
c=2
d=3
so a < b < c < d, but you’re right in that it doesn’t matter. a correlation between ProductSize and your target, or between ProductSize and another variable can be positive or negative but it’s the amount of correlation which is important, not which direction it goes in.
eg: correlation between height and weight is positive, when one goes up the other goes up. correlation between ice cream sales and umbrella sales is negative, when (the weather changes and) one goes up the other goes down but there is a strong relationship between them. apologies if i’m over-simplifying here.
what matters is that even if the categories look ‘back to front’ to you, how strong (or weak) the correlation is, doesn’t change and your network will still figure things out.