Hi everyone,
While playing with SGD on lesson 2, I came up with a simple idea to improve training and avoiding the need to tune the learning rate.
Vanilla SGD is based on steps: it computes the gradient, makes an small step (according to the learning rate) and then repeat it for the new weights. It looks like a kind of blind algorithm, that only can scan the very close surrounding through its white cane. Additionally, tuning the learning rate is critical to achieve a good performance.
Basically, the idea is to take “walks”, instead of “steps”. The sequence for each iteration is as follows:
- Compute the gradient: getting a promising direction to explore.
- Walk: Compute multiple steps (sets of new weights) by using the same gradient, but different learning rates. It can be thought as walking multiple steps in a linear path following the gradient direction, but of different distances.
- Compute the loss for every step and choose the step with the lower loss.
- Compute the gradient of the best step and use it to update the weights (the others non-optimal steps are dismissed).
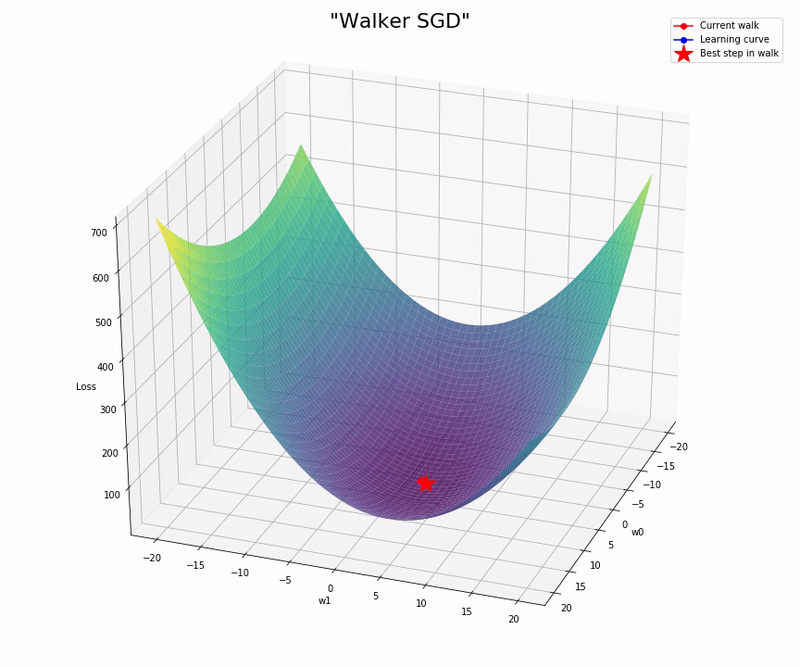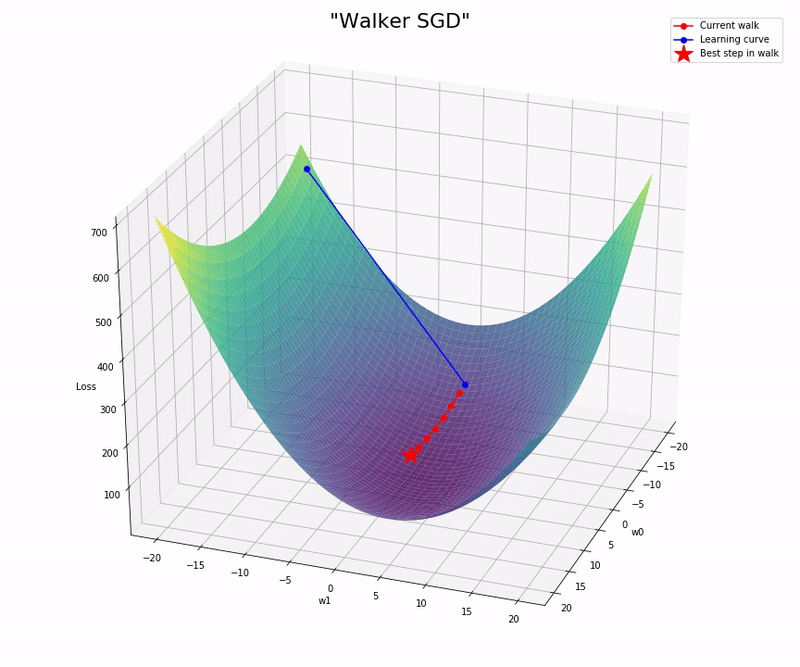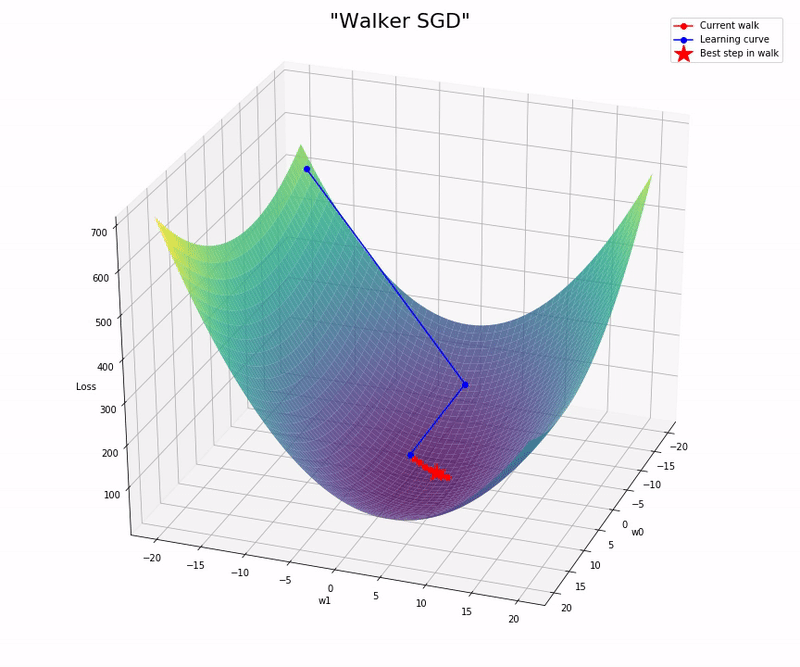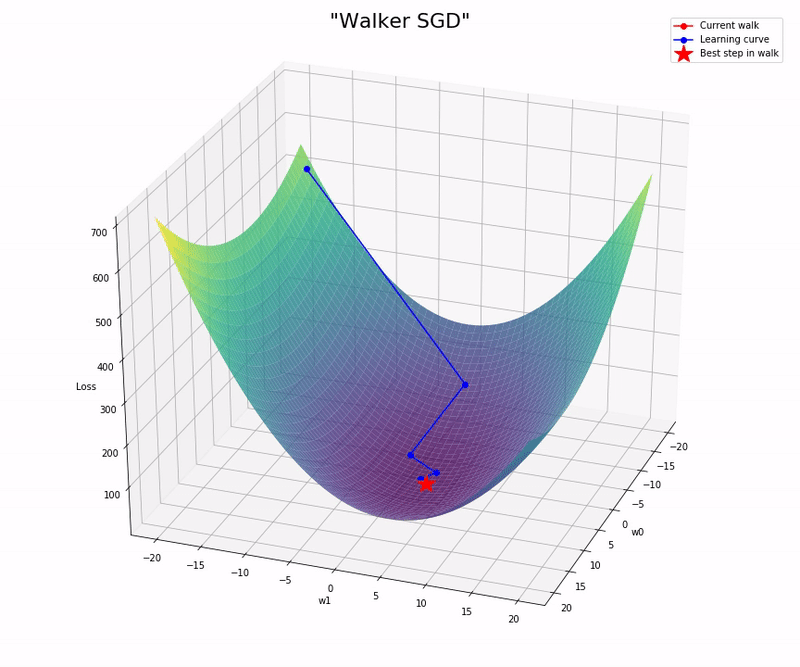
Here is the notebook with the implementation and some experiments I run:
Some intuitions:
-
In a training loop, I think backprop is the more computationally demanding task. So, it makes sense to squeeze the hard-to-compute gradients and use them multiple times with different learning rates.
-
I guess it could complement with optimized learning algorithms, like adam, RMSprop, etc. Unlike those algorithms that leverage on the training history (momentum) to adjust the learning rate, this technique can adjust the learning rate very fast in every iteration. I will try to run some experiments.
-
An optimization could be to use vanilla SGD on most iterations and this technique once in a while. This would allow to run faster, but also providing the freedom to adjust learning rates quickly.
Benchmark:
I performed same basic benchmark, with the following conclusions:
- Usually trains faster than vanilla SGD, since it converges in less epochs.
- It shows low-variance training time, unlike vanilla SGD that trains a little bit faster if tuned with the optimal learning rate, but can take much longer with sub-optimal learning rates.
There are a lot of questions that came to my mind:
- Does this technique already exist?
- Is it useful/applicable or there are important drawbacks?
- How it would behave with more complex networks and higher dimensional data?
I’m eager to receive some feedback!
