I do not think that the LanguageModelLoader is the root cause because sgugger already made a major reduction in peek memory.
My version allocate memory for a tensor storage area and the then fill this storage without allocating new memory.
I do not think that the LanguageModelLoader is the root cause because sgugger already made a major reduction in peek memory.
My version allocate memory for a tensor storage area and the then fill this storage without allocating new memory.
I’m curious whether memory reduction is the cause of performance (both in terms of runtime and accuracy) issues that I’m having, given that the system I’m on has adequate onboard memory. Unfortunately, I’m very much a FastAI user than a dev, so its not immediately clear where the problem could lie.
I had my system admins reboot the system as the system had been on for nearly a month. But a reboot didn’t help with the issue.
nvidia-smi revealed that the Cuda driver the system was using was version 10.0 and I installed Pytorch using conda install -yc pytorch pytorch torchvision cuda100. I’m curious whether the version 10.0 has anything to do with (although if I recall correctly, the earlier version of the code that I ran, also ran on Cuda 10.0).
I suggest using a limited amount of data to test. This thread (GPU Optimizations Central) can help for memory tracking.
another change a couple of weeks ago was that sgugger implemented a change to reduce the memory peek
Make sure that you dont have another process utilizing your GPU, this kind of training time is too way to slow for a regular bug, and I haven’t seen such performance degratdation on my tests.
Pycharm profiling works wonders with pytorch, run it on smaller dataset so it ends reasonably fast and keep in mind that most of the gpu computation and cpu computation runs in parallel (pytorch calls are asynchronous).
This is the GPU information from the target system:
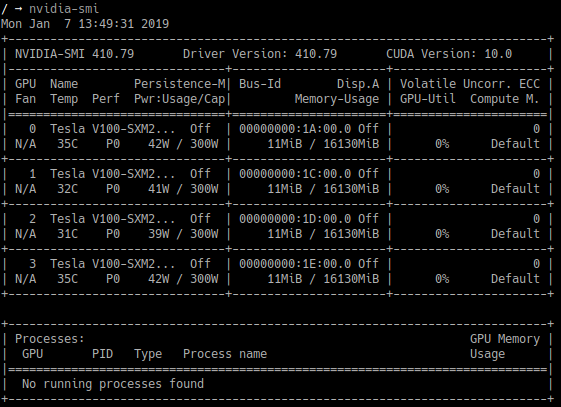
Whenever I run my notebooks, I usually have a panel open running watch -n 1 nvidia-smi. Earlier when I ran my notebook, I got 96% GPU utilization constantly. Consequently, the runtime was limited to 28 hours (11 epochs) with an accuracy of 0.583.
However, in the latest run, I noticed that I constantly have 0-10% GPU utilization and only a maximum of 70% in-between. I have never seen GPU utilization of over 70% in the latest runs. Again, just a reminder, nothing has changed in terms of my data and my code.
Here is an example screenshot:
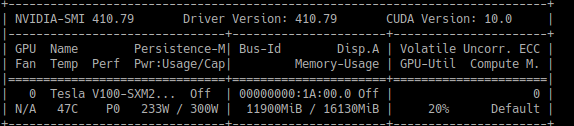
I can see how the runtime is drastically slower, since the GPU utilization is so much slow.
I am sure my process is the only one utilizing the GPU.
Unfortunately, I am restricted to the command line and Jupyter notebooks as this is a remote system on which I don’t have admin privileges.
Also, following my previous post in this thread,
I created a new environment with the default installation instructions, but no vain. Performance is still slow.
One of the things i do to minimize memory allocations is to reuse in memory storage for the batch on the cpu side and creating views onto that storage. This is a core feature of numpy and pytorch, but one can easily end up making a copy instead of a view. To test these optimisations i have created a notebook : https://github.com/kasparlund/nlp/blob/master/test_np_pytorch_storage_views.ipynb
Here is an update. I started checking out earlier release branches and running through the same code, since I knew everything worked well before. I started working from branch release-1.0.35. I worked through each release running the same code including databunch creation and running the language model for 1 epoch.
I find that, speed is same up until release-1.0.39. Up until this release, a single epoch for my dataset takes a little over 2 hours (I didn’t run it for the entire 2 hours, I’m just going by the estimate). When I ran it in release-1.0.39, the estimate for a single epoch was more than 12 hours.
So, as far as I can tell, wrt to the language model fine-tuning code, changes from release-1.0.38 to release-1.0.39 seems to have drastically affected performance in terms of GPU speed. I could also take a guess and say this would also affect performance in terms of accuracy.
I’m hoping this information will help in diagnosing the problem further.
Thanks.
I’d need a reproducible example of that. Is it only for a very large dataset? I haven’t seen any drop in speed on my side, but you’re not the first one to report this.
It is on a relatively large dataset. Should I just link a notebook with my code? This notebook is pretty much what I executed for all the texts. This one was run earlier when everything was working well.
Whats the best way for me to share an example?
I’m trying to use github’s compare facility to compare the changes between master and release-1.0.38 here. But it shows that only the version file has been changed. However, the branch itself is 212 commits behind master. I’m confused as to what was changed in text.
I also saw a slowdown with a big data set but had yet to dig into it.
I have managed to replicate the problem in a compact way (I think) by mocking up a big data set from, then look at the estimates. You can make the data arbirarily large and I am not sure how much that slows things down, but it is consistently slower with the newer version.
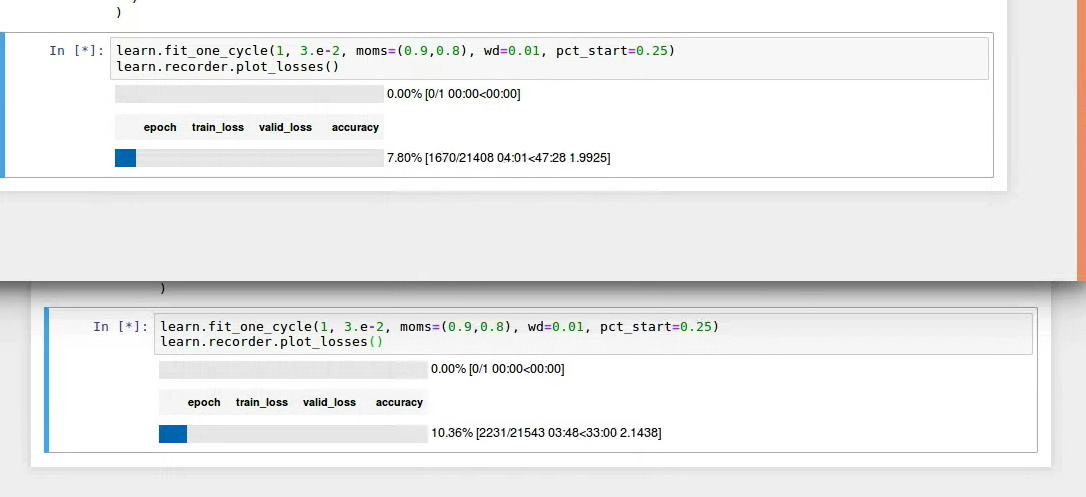
In this below example (aprox):
v1.0.40dev0 : 51 minutes (top of graphic)
v1.0.37 : 36 minutes
Between these two versions the batch sized was moved to the first dimension. I wonder if Pytorch or CUDNN has some optimization that you lose when you change that. It is only a guess, I have not looked into detail.
Here is the code to replicated it. I also posted as a gist here in case that is easier since I did the test in a notebook.
from fastai import *
from fastai.text import *
imdb = untar_data(URLs.IMDB_SAMPLE)
df = pd.read_csv(imdb/'texts.csv')
replicated_data = pd.concat([df.copy() for _ in range(300)]) #you can make this large or small at will...
data_lm = TextLMDataBunch.from_df('./',replicated_data,df)
bptt = 100
emb_sz,nh,nl = 400,1111,2
learn = language_model_learner(data_lm,bptt,emb_sz,nh,nl,drop_mult=0.5,qrnn=True)
learn.unfreeze()
learn.model
learn.fit_one_cycle(1, 3.e-2, moms=(0.9,0.8), wd=0.01, pct_start=0.25)
#learn.recorder.plot_losses()
Is that the only change that happened between them in terms of text? Also, in my experiments, version release-1.0.38 was good and things went slow in release-1.0.39. Did you have a similar experience?
I don’t know what else changed; likely a lot of details.
I will try other versions and see what exact change creates the difference in time.
FWIW, total time difference was 47 vs. 37 minutes once the training was completed.
that must have been the same slowdown i saw on mac
i have submitted a PR with the optimisations i have developed the last couple of weeks: https://github.com/fastai/fastai/pull/1470
New comparison of the current version of fastai and the one submitted PR 1470
Current version of fastai: Total time: 3:54:01
| epoch | train_loss | valid_loss | accuracy |
|---|---|---|---|
| 1 | 4.761493 | 5.216155 | 0.226916 |
| 2 | 4.455210 | 4.944639 | 0.245408 |
| 3 | 4.266388 | 4.803604 | 0.258620 |
| 4 | 4.080987 | 4.689150 | 0.269394 |
| 5 | 3.935183 | 4.667518 | 0.272271 |
PR 1470 Total time: 3:25:11
| epoch | train_loss | valid_loss | accuracy |
|---|---|---|---|
| 1 | 4.773715 | 5.202889 | 0.226930 |
| 2 | 4.423928 | 4.951905 | 0.244844 |
| 3 | 4.251030 | 4.799040 | 0.258060 |
| 4 | 4.068891 | 4.684124 | 0.269447 |
| 5 | 3.949466 | 4.662094 | 0.272399 |
The main practical difference is that the current version of fastai LanguageModelPreLoader takes 14% more time and process about 1% less tokens pr epoch that PR 1470.
This concludes this optimization thread.
I tried to pull for release 1.0.38 and 1.0.39. To confirm, I re-ran my 1.0.40dev0 version.
I can no longer replicate my slow times.
Not sure what that means, but I wanted to attached to this thread so it is documented. Code is the same as posted in the gist above. Not sure why it could/would be so different re-running the same code. Maybe something more complicated is going on with my OS.
v1.0.40dev0 : 31 minutes (top of graphic)
v1.0.39 : 32 minutes
v1.0.38 : 20.5 minutes
v1.0.37 : 36 minutes
Are you saying that the current master is working as fast as before?
for me, today, using this code: yes. I cannot replicate my slow code from yesterday. Maybe I messed up my environment install, but from all I can tell, they perform about the same across different version.
Do you have a replicating example that shows slowness? Does my example show slowness on your machine?