Hi everyone!
From last few weeks, I am trying to implement this fabulous paper https://arxiv.org/pdf/1803.09820.pdf by @Leslie in Tensorflow, but I am not able to get the optimal results mentioned in the paper. I have several doubts regarding the implementation since there is no good Tensorflow implementation of it.
- During the LR range test, what momentum value we should be using, since this is the first step of the whole recipe (be it remain at a constant value of 0.9 or should it be linearly decreasing with the increase in LR)?
- What value of min_lr and max_lr should we use, although in the original paper he suggested to start with very small LR of 1e-6 and increase it linearly or exponentially till the point where training loss starts diverging but in the report that I referenced earlier is using only a small LR range of let’s say 1e-2 to 1e-1 (similar to 1 cycle policy, so I am wondering how one came up with value of 1e-2).
- To find optimal momentum, should we be using one cycle policy (max_lr found from step 1 and min_lr, one-tenth of max_lr) in which the max_mom is the hyperparameter and min_mom is 0.8 or 0.85? One more doubt, should we run the experiment for only half the cycle (in which LR is increasing from min value to max value only or run it for the entire cycle)?
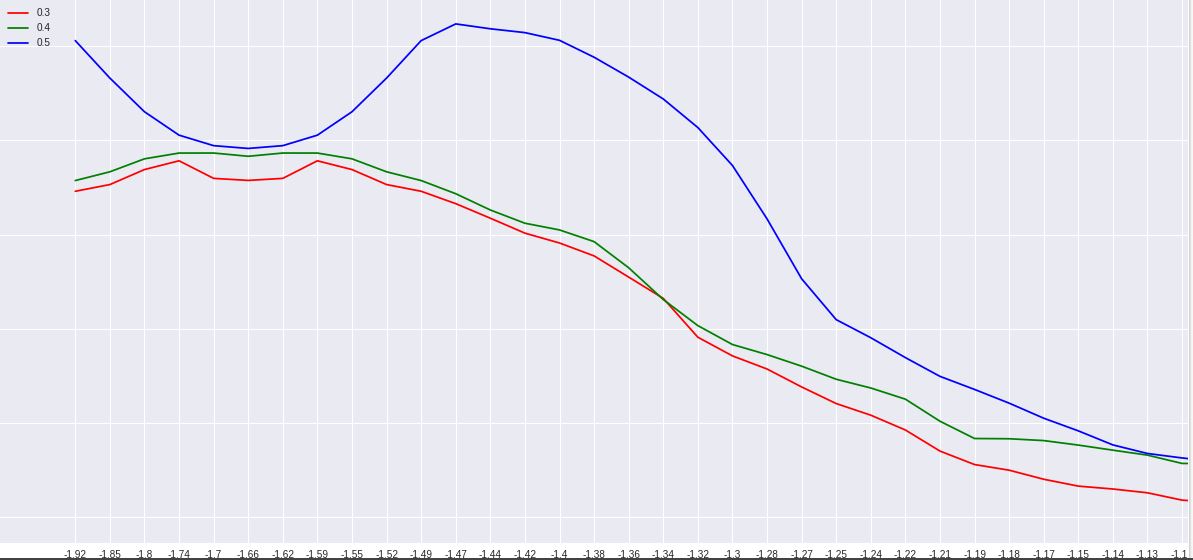
I am also not getting a proper instability in the validation loss (all hyperparameters are converging to the same low loss value, suggesting of under fitted model). I am also attaching a pic of my experiment (for a search of dropout). My max LR from LR range test was coming put to be 10^(-1.1) = 0.08, so I ran the One cycle policy for only half the cycle. I kindly request you, people, to look into this doubt.
@jeremy @rachel @Leslie @radek
- List item
I am not able to explain a few things to myself. I am observing that I can use much large learning rate compared to what found from LR range test (that exp is giving me a value of 0.08 but I am able to use LR up to 1 and reducing the overall epochs for training), then what’s the point of running LR range test if it’s not able to provide me the max LR?
