I will be in our classroom at 5:30pm for any questions.
I had a doubt from lesson 4.
I know embeddings are more powerful over one hot encoding. Is there any situation where we would prefer one hot encoding over the former?
Embeddings need to be learned and they can also overfit your data. One-hot encodings are simpler.
One other type of encoding people do when they have many categories is to use feature hashing which is another type of embedding (random).
1 Like
@yinterian Do you have any references related to calculating the optimum embedding size for non word vector applications?
Not too many papers on the subject all together. (-:
Any recommended reference code for visualizing embeddings in fastAI / Pytorch?
Hey! Had a question regarding lesson 4 structured data … Suppose we are merging different datasets like we did with Rossmann (Google Trends, Weather etc) to training and test database… In Rossmann example, in the test database we replaced empty NAN columns with a random integer that was not present before for integer columns. Similarly can we place random strings in the test database for columns of the test database that are empty or NAN and are of dtype object (strings)?
Not fastAI - but found this interesting entity-embedding-rossmann/plot_embeddings.ipynb at master · entron/entity-embedding-rossmann · GitHub
Its from the Rossmans 3rd place winners Github.
4 Likes
Thanks. I saw the images in their paper but lacked the insight to check their github account!
How do you define Structured Data?
Data in well known given format?
Hi Yannet. Thanks for taking time to answer our questions. I have the following questions regarding previous lectures:
- In Lecture 4, when we use proc_df to split into train and validation sets, we have a mapper object containing mean and variance of the train set. The documentation says it will be used on the validation set when try the model. Why is this better than, say, using the mean and variance of overall data or using different means and variances for train and validation sets?
- In Lecture 4, we constructed a language model before doing sentiment analysis. We tried predicting the next words of the language model to check how good it is. Is there a more objective way to measure performance of a language model?
- This might not have come up in the lectures directly, but embedding layers return vectors as an output. Are word vectors such as GloVe trained by using embedding layers also? If so, what are the input and the target?
Thank you.
Q: “In Lecture 4, we constructed a language model before doing sentiment analysis. We tried predicting the next words of the language model to check how good it is. Is there a more objective way to measure performance of a language model?”
Look at perplexity in that lecture
Q: This might not have come up in the lectures directly, but embedding layers return vectors as an output. Are word vectors such as GloVe trained by using embedding layers also? If so, what are the input and the target?
Glove is trained by minimizing the equation in page 13/30 of this presentation. You compute a co-occurrency matrix by looking at words that occur nearby (2 to 3 words away). The Glove model is much more simple than the model Jeremy is learning which is an RNN.
http://llcao.net/cu-deeplearning15/presentation/nn-pres.pdf
Here is the lecture:
1 Like
Hi @yinterian… Whenever you get the time, could you please clear this doubt. Thank you!
But embeddings are just one-hot encodings - they’re simply a computational performance trick which gives the same result?.. And aren’t they easier than one-hot encodings, since you don’t have to encode anything?
1 Like
I was thinking these embeddings should mean something and can be used to understand which users/movies are similar to each other. But after I looked at lesson 5 notebook I see just a cloud of weights in embedding matrixes: no structure, no clusters visible. Have anybody used somehow these embeddings for clustering/segmentation ?
Take a look at the section ‘Analyze Results’ of this notebook from part 1 v1, maybe this will be of help 
I think you might also want to look at UMAP - sounds like a great use case to experiment with it.
1 Like
Thanks radek. Because of this notebook I have this feeling that embeddings should mean something.
Now I think I am starting to get it. There are 9K movies being rated and only 50 were plotted. These 50 have the highest/lowest score which means they were significantly different from others. I have two assumptions I am going to check:
- I think if we plot 500 movies we want see any structure
- these top 50 movies have high number of ratings - i think only in this case embeddings really work. 1 movies - 1 rating - no need for embeddings.
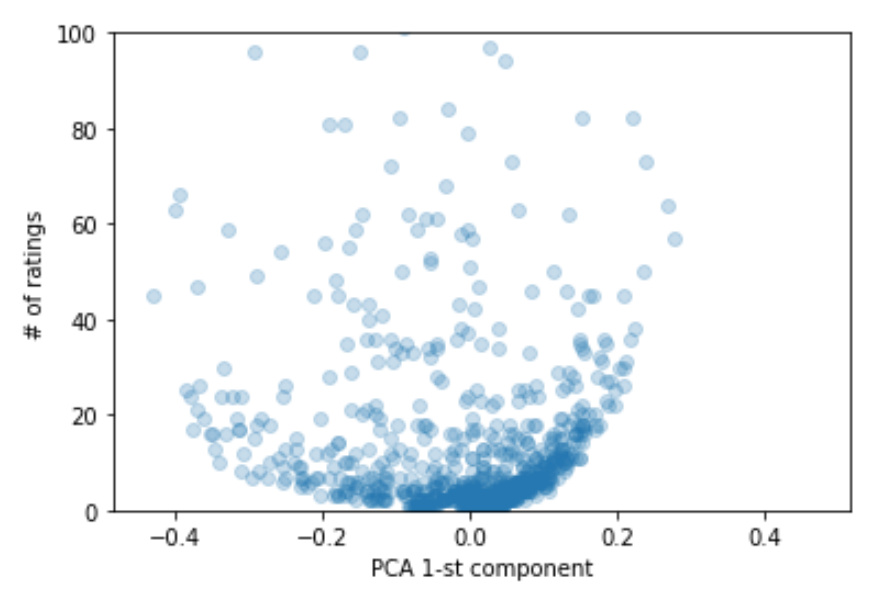
Trying to wrap my mind around your statement that embeddings are OHE for some days already… and still don’t get it. I mean… even if only one dimension of embeddings size, still you would have OHE + weights…
Wouldn’t the conceptual comparison be more to a likelihood encoding (with embedding of one dimension), and a <insert here new name for possibly new concept, non linear “likelihood, or y aware, or impact”, encoding> for >1 embeddings size?
@sermakarevich, even if you only have one rating of a user that rating is giving you info about what he likes/dislikes. (Say its a romantic movie and he rated with 5 stars). You only need one rating to guess things about that user, in that case that possibly doesnt hate romatic movies. And the concept of “latent factors” implies that they mean something (other question is that you can guess the meaning  )
)
1 Like
Thanks for keeping the conversation @miguel_perez. I would mention that you do not have this “romantic movie” marker in your users-movies-ratings dataset. This marker your are trying to learn with embeddings and extracting “latent” factors, right?
In lesson 5 notebook there are genres in a separate file, but
- we do not use it
- there are typically multiple genres per movie
Adventure|Animation|Children|Comedy|Fantasy- how good a prediction can be in this case?
What I am trying to do is to cluster based on latent factors. And what I have found is that these latent factors become meaningful and more accurate when you have a lot of ratings. If you have 1 rating per user-movie these latent factors are just random as at the weight initialisation stage. CF just does not have to change them as there is nothing to learn.