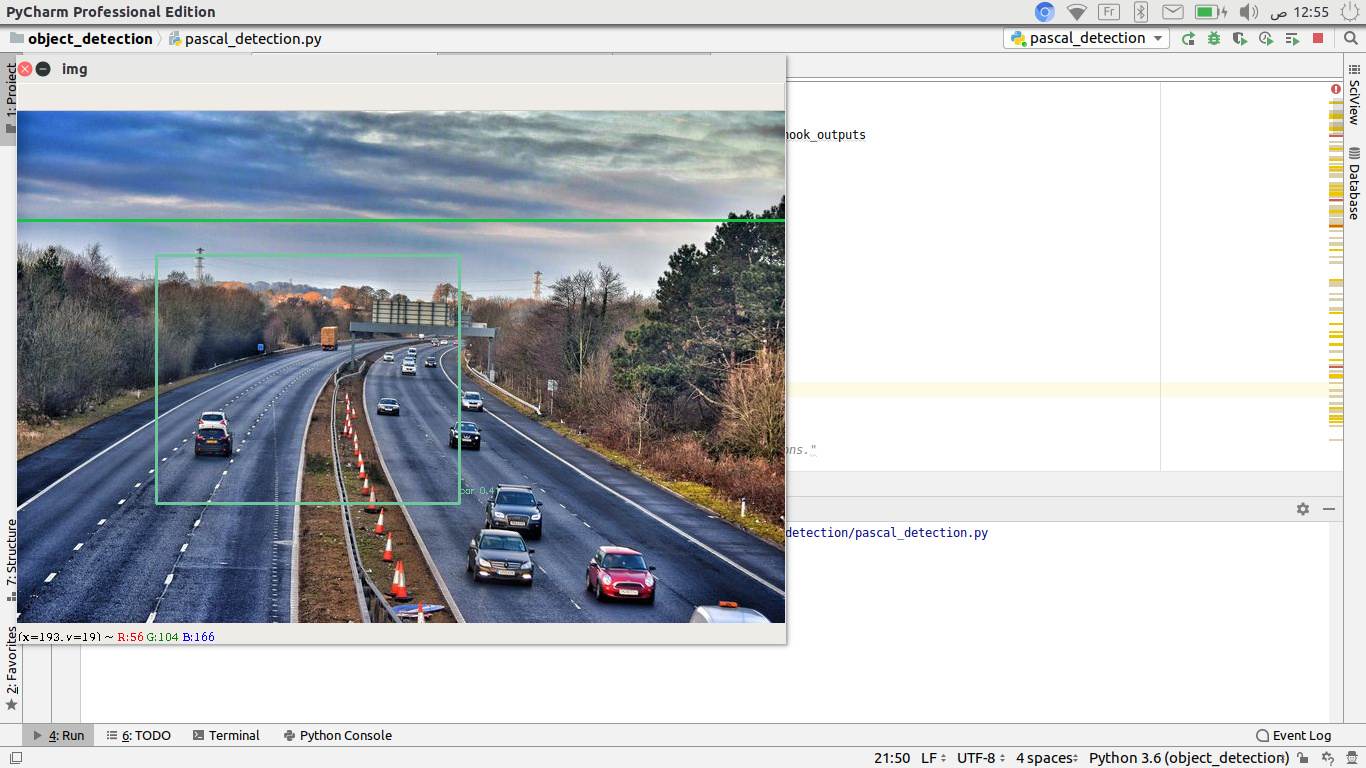
Hi there, I wonder if anyone can help me please.
I have adapted the Retinanet model (using focal loss) for multi-object detection and my results are quite poor. The notebook I have used can be found here: https://github.com/fastai/course-v3/blob/master/nbs/dl2/pascal.ipynb I have obviously changed parts to use my data etc and the original image sizes are 640 x 640.
The aim of the model is to detect the wooden poles used in street lighting. The images I am training on contain labels for trees and wooden light poles, the trees are labelled to help the model distinguish between wooden poles and actual trees since poles could look like tree branches.
I have tried running the model on two different types of dataset:
The original has 839 Training images and 160 Validation Images.
The second used imgaug to augment each of the images in the original dataset doubling it to 1678 images in the training set and 320 images in the validation set.
I ran three version of the model.
- Without any transformations and using the original dataset.
- Using get_transforms
- Using the augmented dataset and using the get_transforms method.
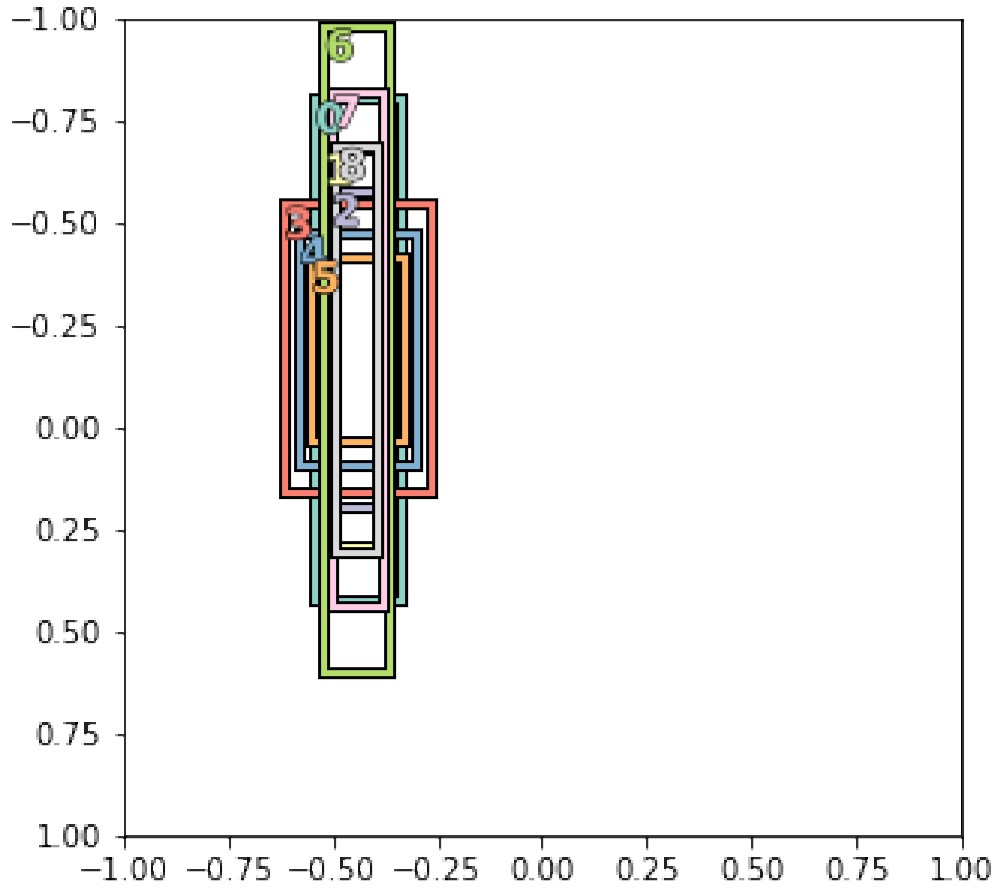
Anchor Boxes:
I believe my problem may come from the anchors I am using in the model. There is a function called create_anchors which will create a set of 9 anchors using different scales and ratios.
However, I find this function rather frustrating for the following reason:
In the images I have labelled, poles are always long, thin and rectangular whereas the trees I have labelled can span across the width of the entire image, tree bounding boxes can be massive, or small, and span larger regions than the poles do. The problem is, getting anchors to fit the bounding boxes of poles and trees which seems impossible to do with this function because it seems there is very little control in the function. I can manage to get good shaped anchors for poles say 5 good pole anchors, by entering some sizes and aspect ratios etc but then remaining 4 of the generated anchors are not a good enough size to fit my trees bounding boxes and therefore they don’t get detected in the model.
I decided to choose anchors to purely fit the shape of poles as shown below and I got the following Average Precisions:
Pole = 4.7 and Trees = 0, using No Augmentations on the Original Dataset
Pole = 11.16 and Trees = 0, using the Get_Aug transformations on the Original Dataset
Pole = 20.32 and Trees = 0, using the Augmented Dataset
As expected, the trees weren’t detected due to the shapes of the anchor boxes.
I changed the ratios and scales again for the anchors to try and get some shapes that would fit both the tree and pole objects as shown below and I got the following Average Precisions:
Pole = 9.14 and Trees = 1.9, using No Augmentations on the Original Dataset
Pole = 7.59 and Trees = 3.2, using the Get_Aug transformations on the Original Dataset
Pole = 13.76 and Trees = 3, using the Augmented Dataset
As can be seen, the AP for the poles got worse and the trees were beginning to be detected. I can’t seem to get a good balance between anchors for poles and trees with this create_anchors function.
I have a few questions as a result:
- Does the Retinanet model have to have 9 anchors per grid cell or can this be changed to have as many anchors as I want?
- Has anybody come across or developed a function that will allow me to create custom anchors, in my case for trees and poles separately and would they mind me using / adapting it ? I have dabble with creating a new function to achieve such a task but with no success.
- If changing the anchor sizes like this is going to be a problem, would it be a good idea to train a model to detect trees only, then use this as a pretrained model that I could then use to train to detect poles only.
- Does anybody know how I could accomplish question 3 ? Using my own pretrained model for object detection.