Hi @KarlH,
Did you solve the issue with the ‘background’ data? I could create a databunch with both labelled and unlabelled data. Everything seems ok but when I tried to fit the data I got the following error:
RuntimeError Traceback (most recent call last)
<ipython-input-64-f250d77c386e> in <module>
----> 1 learn.fit_one_cycle(4, 1e-3, wd=1e-3)
~/anaconda3/envs/Fastai/lib/python3.7/site-packages/fastai/train.py in fit_one_cycle(learn, cyc_len, max_lr, moms, div_factor, pct_start, final_div, wd, callbacks, tot_epochs, start_epoch)
21 callbacks.append(OneCycleScheduler(learn, max_lr, moms=moms, div_factor=div_factor, pct_start=pct_start,
22 final_div=final_div, tot_epochs=tot_epochs, start_epoch=start_epoch))
---> 23 learn.fit(cyc_len, max_lr, wd=wd, callbacks=callbacks)
24
25 def fit_fc(learn:Learner, tot_epochs:int=1, lr:float=defaults.lr, moms:Tuple[float,float]=(0.95,0.85), start_pct:float=0.72,
~/anaconda3/envs/Fastai/lib/python3.7/site-packages/fastai/basic_train.py in fit(self, epochs, lr, wd, callbacks)
198 else: self.opt.lr,self.opt.wd = lr,wd
199 callbacks = [cb(self) for cb in self.callback_fns + listify(defaults.extra_callback_fns)] + listify(callbacks)
--> 200 fit(epochs, self, metrics=self.metrics, callbacks=self.callbacks+callbacks)
201
202 def create_opt(self, lr:Floats, wd:Floats=0.)->None:
~/anaconda3/envs/Fastai/lib/python3.7/site-packages/fastai/basic_train.py in fit(epochs, learn, callbacks, metrics)
99 for xb,yb in progress_bar(learn.data.train_dl, parent=pbar):
100 xb, yb = cb_handler.on_batch_begin(xb, yb)
--> 101 loss = loss_batch(learn.model, xb, yb, learn.loss_func, learn.opt, cb_handler)
102 if cb_handler.on_batch_end(loss): break
103
~/anaconda3/envs/Fastai/lib/python3.7/site-packages/fastai/basic_train.py in loss_batch(model, xb, yb, loss_func, opt, cb_handler)
28
29 if not loss_func: return to_detach(out), to_detach(yb[0])
---> 30 loss = loss_func(out, *yb)
31
32 if opt is not None:
~/anaconda3/envs/Fastai/lib/python3.7/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
545 result = self._slow_forward(*input, **kwargs)
546 else:
--> 547 result = self.forward(*input, **kwargs)
548 for hook in self._forward_hooks.values():
549 hook_result = hook(self, input, result)
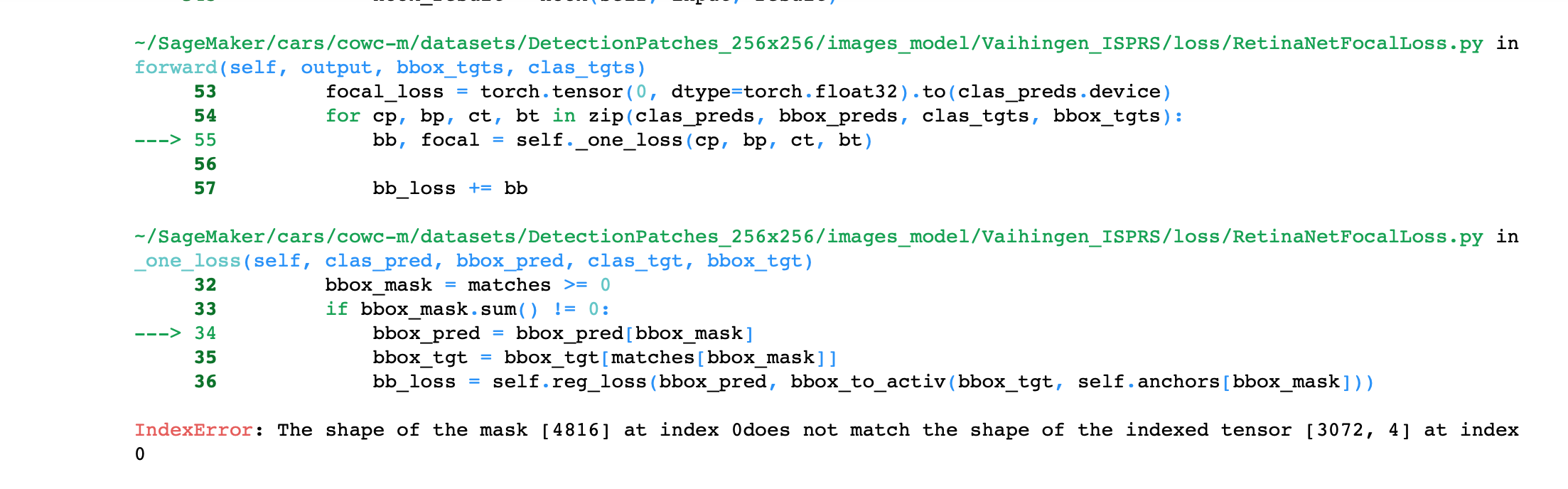
~/DeepLearning/ObjectDetection/loss/RetinaNetFocalLoss.py in forward(self, output, bbox_tgts, clas_tgts)
53 focal_loss = torch.tensor(0, dtype=torch.float32).to(clas_preds.device)
54 for cp, bp, ct, bt in zip(clas_preds, bbox_preds, clas_tgts, bbox_tgts):
---> 55 bb, focal = self._one_loss(cp, bp, ct, bt)
56
57 bb_loss += bb
~/DeepLearning/ObjectDetection/loss/RetinaNetFocalLoss.py in _one_loss(self, clas_pred, bbox_pred, clas_tgt, bbox_tgt)
28
29 def _one_loss(self, clas_pred, bbox_pred, clas_tgt, bbox_tgt):
---> 30 bbox_tgt, clas_tgt = self._unpad(bbox_tgt, clas_tgt)
31 matches = match_anchors(self.anchors, bbox_tgt)
32 bbox_mask = matches >= 0
~/DeepLearning/ObjectDetection/loss/RetinaNetFocalLoss.py in _unpad(self, bbox_tgt, clas_tgt)
15
16 def _unpad(self, bbox_tgt, clas_tgt):
---> 17 i = torch.min(torch.nonzero(clas_tgt - self.pad_idx))
18 return tlbr2cthw(bbox_tgt[i:]), clas_tgt[i:] - 1 + self.pad_idx
19
RuntimeError: invalid argument 1: cannot perform reduction function min on tensor with no elements because the operation does not have an identity at /opt/conda/conda-bld/pytorch_1565272271120/work/aten/src/THC/generic/THCTensorMathReduce.cu:64
`
Checking the forums seems to be somethig related with the images/labels, so I guess is due to the [0,0,0,0] ['background'] trick. Any idea how to solve it?
Thanks!

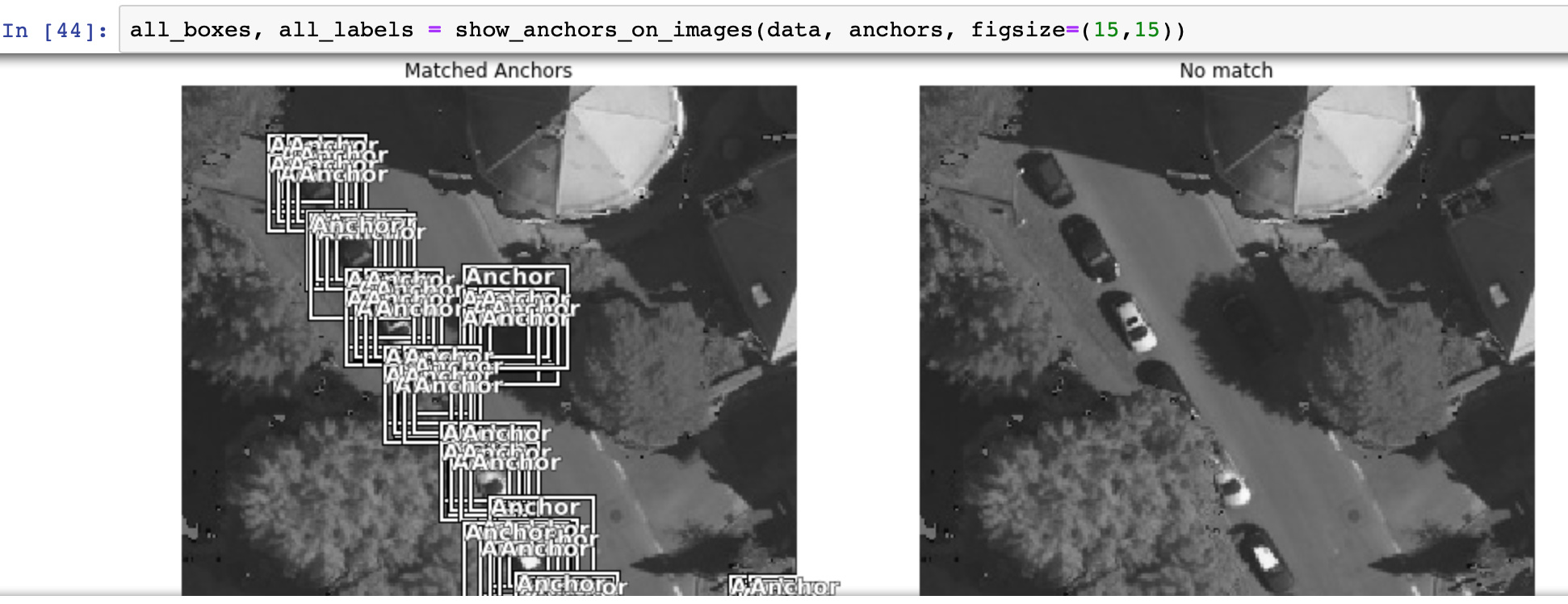


 and also I am sorry if this is a stupid question, I am still new to all this stuff…)
and also I am sorry if this is a stupid question, I am still new to all this stuff…)