ok in the pascal nbk we dont have any metric defined ??
What do you mean by pascal nbk ? I found this in his Cocotiny nb:
In [15]:
voc = PascalVOCMetric(anchors, size, [i for i in data.train_ds.y.classes[1:]])
learn = Learner(data, model, loss_func=crit, callback_fns=[ShowGraph, BBMetrics],
metrics=[voc])
i was talking about this fai notebook which is in dev phase
In this notebook are they using above metrics or any other metrics?
I haven’t run this nb yet. But at the end I found mAP. I don’t know if they show any others metrics during learning.
Hi,
the models return three thinks:
- [1, 24480, 3] -> [Batchsize, number of boxes, classes + background] -> classification results for each anchor
- [1, 24480, 4] -> [Batchsize, number of boxes, box-coordinates refinements] -> how the anchors should be resized to match the objects in the image
- Feature map shapes. You can ignore that for a start is more for debug purposes
For inference please take a look at the following colab notebook:
https://colab.research.google.com/drive/16un8u65D4oTWiWzpdjMU_cpnVasaQ72n
or this function in the repo:
3 Likes
Great !! Thank you so much
THanks christian
I wanted to ask few more things related to metrics and bbox coordinates
- I am using RSNA kaggle competition dataset where they have provided bbox in this order as x, y width height
Do i have to do swap the x y and width & height here so that is why m doing as below
train_df[‘bbox’]= train_df.loc[:,[‘y’,‘x’,‘height’,‘width’]].values.tolist() # x ,y,width ,height
train_df[‘bbox’]= train_df[‘bbox’].apply(lambda x:[[x[0],x[1],x[2]-x[0]+1,x[3]-x[1]+1]])
- I am having a doubt if bbx are drawn correctly or not when i see in data.show_batch so wanted to check if i m passing coordinates correctly to API.
- In the above problem we are doing binary classification 0 and 1 so will this metric work for this ?
what does this metric tries to evaluate ?
PascalVOCMetric(anchors, size, [i for i in data.train_ds.y.classes[1:]])
Thanks in advance for your time
Moin,
sorry I have problems understanding your questions.
1-2) Are the boxes correctly drawn at schow_batch?
- Yes that would work to evaluate the mAP at train time on the validation dataset for the one class you have.
With kind regards,
Christian
By looking at the picture i had doubt for that reason i wanted to take one image for which i can draw bbox using rectangle patch and compare that to show batch .
But problem is show batch takes pics at random every time.
Any alternate suggestion to cross verify ?
I tried using below means.But i get an error message show has no param y.
before calling BBoxcreate, i read the image using pydicom (Since img format is .dcm and it stores numpy array in field ) and converted numpy array to PIL Img object before passing it to method.
img = open_image(path/'train'/train_images[1])
bbox = ImageBBox.create(*img.size, train_lbl_bbox[1][0], [0, 1], classes=['person', 'horse'])
img.show(figsize=(6,4), y=bbox)Thanks for your notebook @Bronzi88! I tried to recreate your success with the SVHN dataset, however I am stuck when it comes the training part. As soon as I run learn.recorder.plot() or learn.fit_one_cycle() it throws the following error, which I don’t know how to handle:
RuntimeError: The size of tensor a (3) must match the size of tensor b (4) at non-singleton dimension 3
Are my images the wrong size? I resized them to be 48x48. Are the anchors set wrong?
1 Like
Hi (Moin),
the minimal supported image size is 256x256 at least until now.
But that would lead to a different error  message.
message.
Can you post the notebook or some code? Then I could try to replicate the error.
With kind regards,
Christian
Hi (Moin),
the following code should work.
img = open_image(coco/ 'train_sample' / images[0])
image_boxes = img2bbox[images[0]][0] #[[x1,y1,x2,y2], [x1,y1,x2,y2]]
bbox = ImageBBox.create(*img.size, bboxes=image_boxes, labels=[0,0,0], classes=['TV'])
img.show(figsize=(6,4), y=bbox)
plt.show()
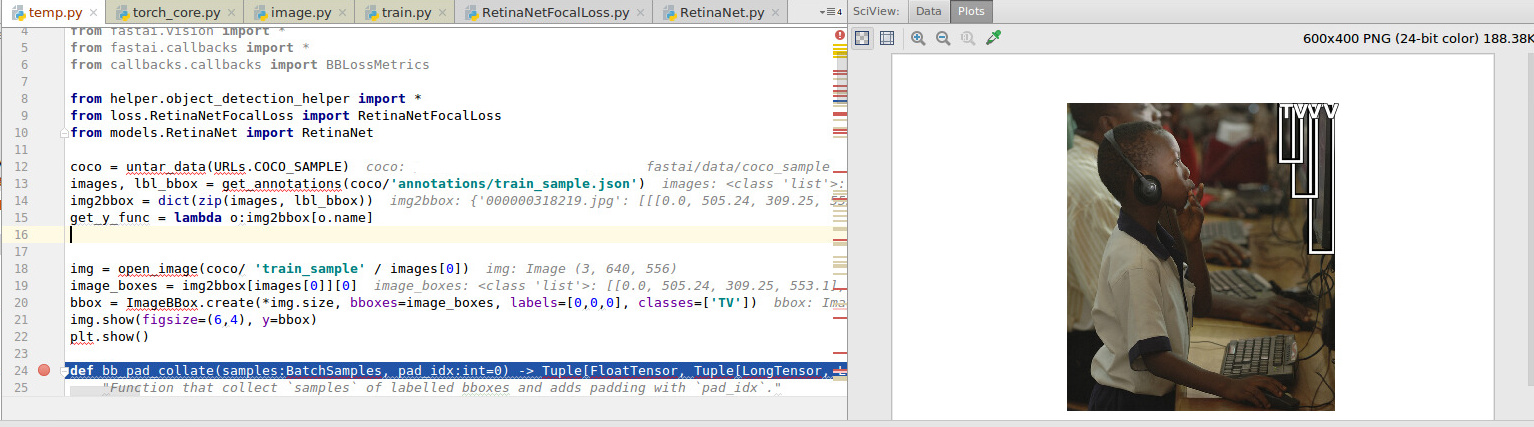
With kind regards,
Christian
I’m trying to adapt the RetinaNet notebook to a dataset that contains empty images with no objects. Does anyone know how I might go about adapting the current notebook to accommodate this?
Right now the notebook as is works fine when I use the subset of the data that contains images, so everything is good there. When I try to add in images without labels, I get errors. Specifically the create method of the ImageBBox class tries to index into an empty list.
Does anyone know a good format for representing empty images in bounding box format? I’ve considered adding some dummy coordinates like [0, 0, 0, 0] but I’m concerned that will have weird effects on training.
Hi (Moin),
if you use [0, 0, 0, 0] with the background class as the label that should be work just fine.
With kind regards,
Christian
Gave this a try. It causes some sort of numerical issue. When I create a dataloader, I get a ton of UserWarning: Tensor is int32: upgrading to int64; for better performance use int64 input
When I try to call data.show_batch(rows=3), the kernel dies. The issue repeats.
Maybe extending the bounding box for the background to the entire picture area helps to avoid this problem?
HI,
in case you don’t have any labels
def get_y_func(o):
if str(o.id) in img2bbox: #Labels?
return img2bbox[str(o.id)]
else: #No labels?
return [[[0,0,0,0]], ['background']]
works just fine for me.
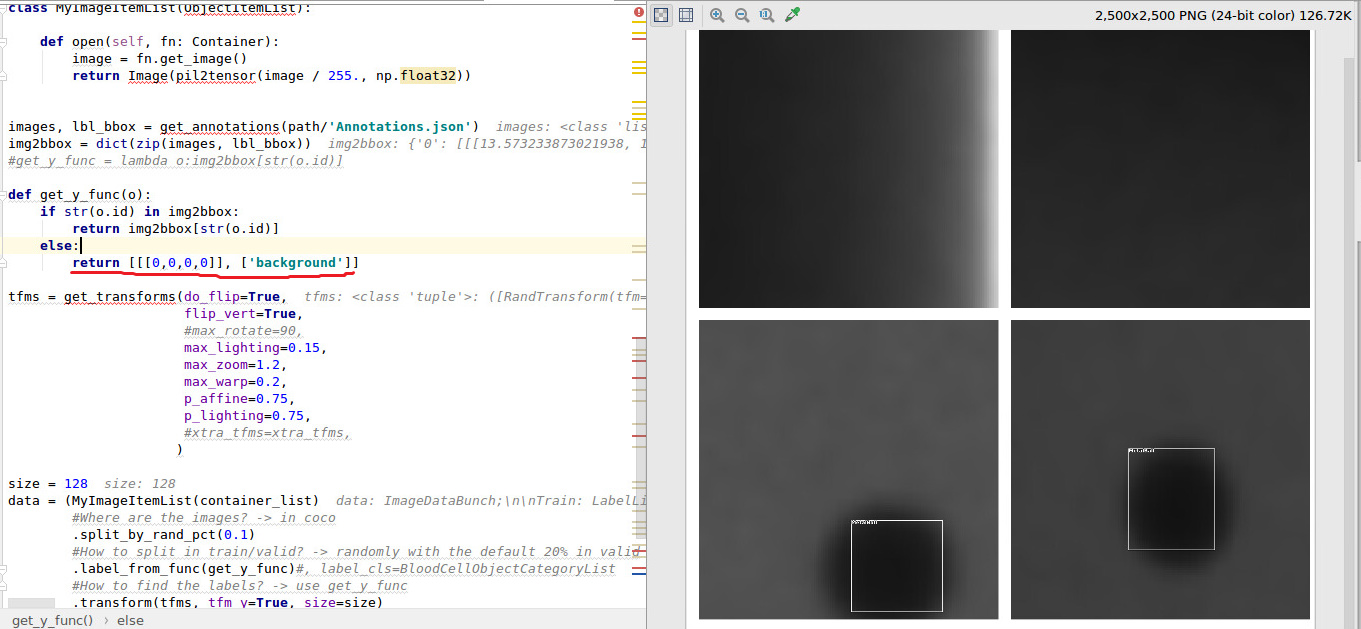
This does work for dealing with empty images. You do end up with an extra class (‘background’ is listed twice in data.classes and data.c is 3, but monkey patching these seems to work.
The dead kernel thing is still an issue, which is weird. It seems like if the dataloader gets a batch of empty images, something goes wrong. I’m doing this on Windows 10 so this could be an OS specific issue. My first thought was maybe it’s a multiprocessing thing, so I set num_workers=1 but that didn’t solve it. I’m not really sure how to troubleshoot because things go from fine to dead kernel without any kind of error.
Might spin up an Ubuntu server and see if the issue persists there.
Moin,
to deactivate multiprocessing, you have to set num_workers to zero. At least if I remember correctly.
'background’ is listed twice. Okay, that is not what I intended. But the fastai method generate_classes add [‘background’] anyway and do not check if its already in the list of classes. Sorry about that.
But you can easily fix that by overwriting the method generate_classes from the class ObjectCategoryProcessor.
With kind regards,
Christian
1 Like
yes thanks . It worked. problem ws i import PIL image also so it was not working with fai Image object.
some more asks
- My loss dsnt improves after certain value like 1.70 .
I have doubt on the matches function if it is assigning the ground truth box correctly.
In my case there is only a single object to be detected and single class.
. Finall output of matches function ( that tends to assign gt bb to anchor) yields me anchor with dim more than 1 so n * 4 . and dim of target is 1 * 4 ( it expands as n*4 ) before going to loss function for regression.
I thought we should get only one anchor .that has gt box. by furhter using max
Here is my understanding on matches if i understand correctly
bbox_tgt, clas_tgt = self._unpad(bbox_tgt, clas_tgt)
matches = match_anchors(self.anchors, bbox_tgt)
bbox_mask = matches>=0
if bbox_mask.sum() != 0:
bbox_pred = bbox_pred[bbox_mask]
bbox_tgt = bbox_tgt[matches[bbox_mask]]
bb_loss = self.reg_loss(bbox_pred, bbox_to_activ(bbox_tgt, self.anchors[bbox_mask]))
a) calculate Iou between class object bbox and all possible anchor bbox
b) get the anchor which can identify a particular class out of multiple classes if any using iou. max
c) Apply threshold to separate the bg and foreground. and assign the id of class to all the anchor who are able to find this particular class id.
Now shldnt there be one more filter to get that anchor which further has got best iou match with Ground truth of class it is confident about ?
- what is the purpose of activ to boox and vice versa . box to activation .
why is that needed.