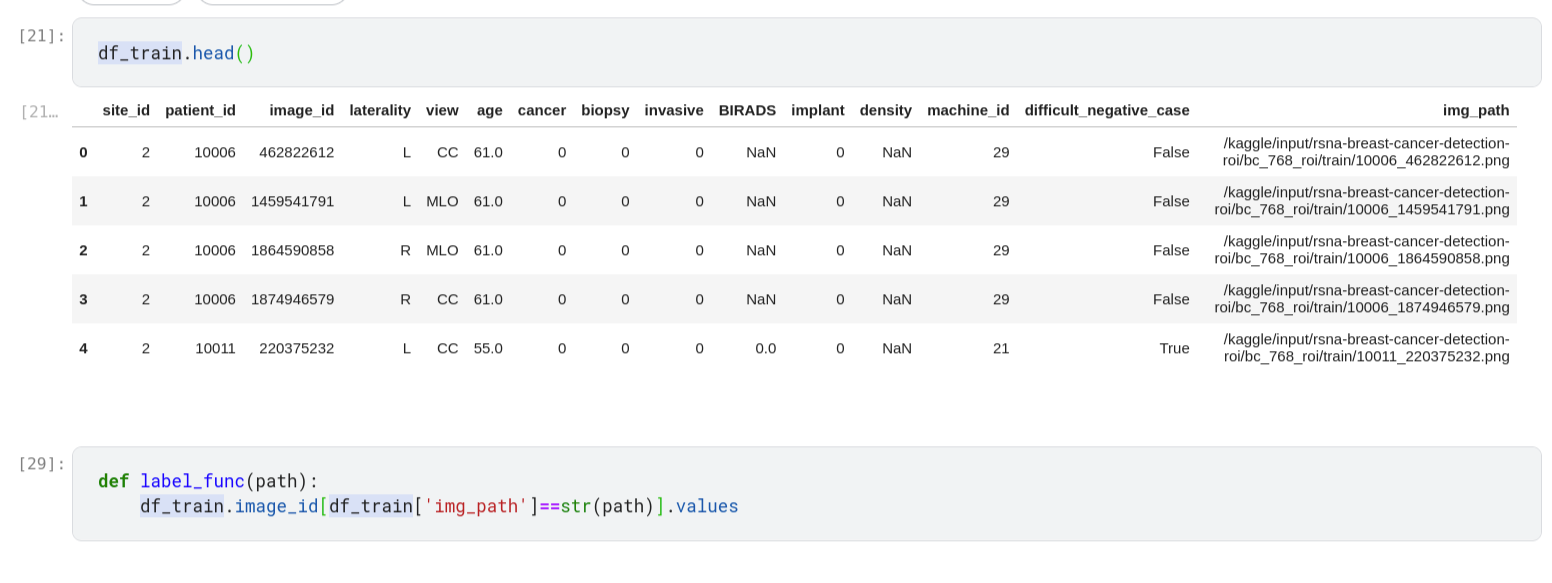
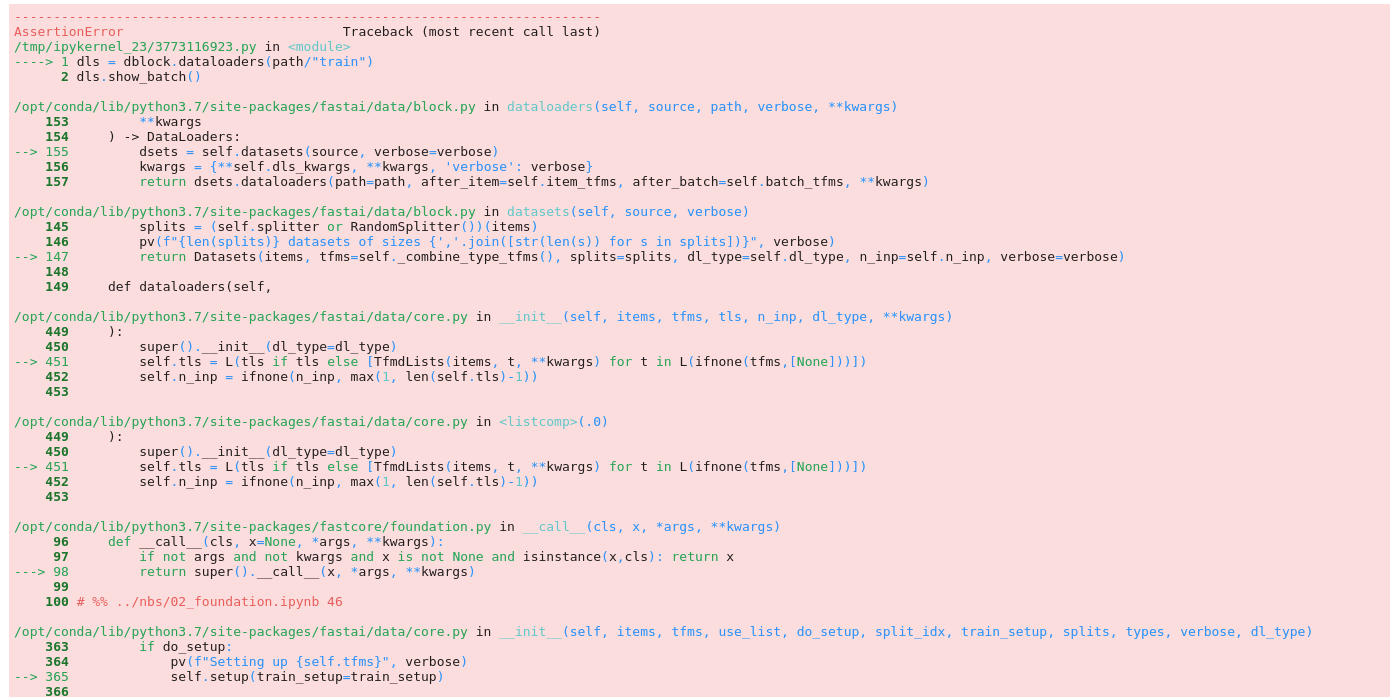
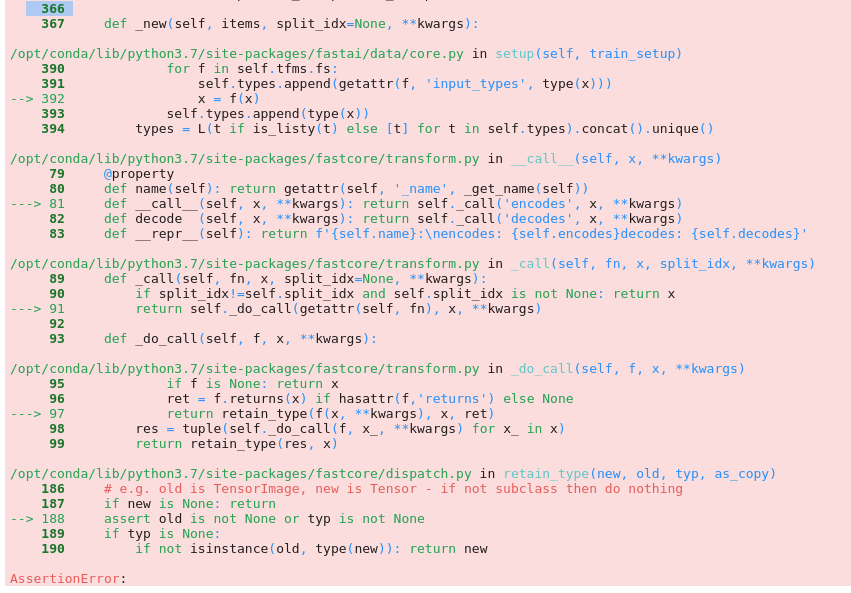
thank you for the suggestion but I get with your function this error here:
I don’t know why?
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
/tmp/ipykernel_23/1823673056.py in <module>
6 item_tfms = Resize(64))
7
----> 8 dls = dblock.dataloaders(path/"train")
9 dls.show_batch()
/opt/conda/lib/python3.7/site-packages/fastai/data/block.py in dataloaders(self, source, path, verbose, **kwargs)
153 **kwargs
154 ) -> DataLoaders:
--> 155 dsets = self.datasets(source, verbose=verbose)
156 kwargs = {**self.dls_kwargs, **kwargs, 'verbose': verbose}
157 return dsets.dataloaders(path=path, after_item=self.item_tfms, after_batch=self.batch_tfms, **kwargs)
/opt/conda/lib/python3.7/site-packages/fastai/data/block.py in datasets(self, source, verbose)
145 splits = (self.splitter or RandomSplitter())(items)
146 pv(f"{len(splits)} datasets of sizes {','.join([str(len(s)) for s in splits])}", verbose)
--> 147 return Datasets(items, tfms=self._combine_type_tfms(), splits=splits, dl_type=self.dl_type, n_inp=self.n_inp, verbose=verbose)
148
149 def dataloaders(self,
/opt/conda/lib/python3.7/site-packages/fastai/data/core.py in __init__(self, items, tfms, tls, n_inp, dl_type, **kwargs)
449 ):
450 super().__init__(dl_type=dl_type)
--> 451 self.tls = L(tls if tls else [TfmdLists(items, t, **kwargs) for t in L(ifnone(tfms,[None]))])
452 self.n_inp = ifnone(n_inp, max(1, len(self.tls)-1))
453
/opt/conda/lib/python3.7/site-packages/fastai/data/core.py in <listcomp>(.0)
449 ):
450 super().__init__(dl_type=dl_type)
--> 451 self.tls = L(tls if tls else [TfmdLists(items, t, **kwargs) for t in L(ifnone(tfms,[None]))])
452 self.n_inp = ifnone(n_inp, max(1, len(self.tls)-1))
453
/opt/conda/lib/python3.7/site-packages/fastcore/foundation.py in __call__(cls, x, *args, **kwargs)
96 def __call__(cls, x=None, *args, **kwargs):
97 if not args and not kwargs and x is not None and isinstance(x,cls): return x
---> 98 return super().__call__(x, *args, **kwargs)
99
100 # %% ../nbs/02_foundation.ipynb 46
/opt/conda/lib/python3.7/site-packages/fastai/data/core.py in __init__(self, items, tfms, use_list, do_setup, split_idx, train_setup, splits, types, verbose, dl_type)
363 if do_setup:
364 pv(f"Setting up {self.tfms}", verbose)
--> 365 self.setup(train_setup=train_setup)
366
367 def _new(self, items, split_idx=None, **kwargs):
/opt/conda/lib/python3.7/site-packages/fastai/data/core.py in setup(self, train_setup)
390 for f in self.tfms.fs:
391 self.types.append(getattr(f, 'input_types', type(x)))
--> 392 x = f(x)
393 self.types.append(type(x))
394 types = L(t if is_listy(t) else [t] for t in self.types).concat().unique()
/opt/conda/lib/python3.7/site-packages/fastcore/transform.py in __call__(self, x, **kwargs)
79 @property
80 def name(self): return getattr(self, '_name', _get_name(self))
---> 81 def __call__(self, x, **kwargs): return self._call('encodes', x, **kwargs)
82 def decode (self, x, **kwargs): return self._call('decodes', x, **kwargs)
83 def __repr__(self): return f'{self.name}:\nencodes: {self.encodes}decodes: {self.decodes}'
/opt/conda/lib/python3.7/site-packages/fastcore/transform.py in _call(self, fn, x, split_idx, **kwargs)
89 def _call(self, fn, x, split_idx=None, **kwargs):
90 if split_idx!=self.split_idx and self.split_idx is not None: return x
---> 91 return self._do_call(getattr(self, fn), x, **kwargs)
92
93 def _do_call(self, f, x, **kwargs):
/opt/conda/lib/python3.7/site-packages/fastcore/transform.py in _do_call(self, f, x, **kwargs)
95 if f is None: return x
96 ret = f.returns(x) if hasattr(f,'returns') else None
---> 97 return retain_type(f(x, **kwargs), x, ret)
98 res = tuple(self._do_call(f, x_, **kwargs) for x_ in x)
99 return retain_type(res, x)
/opt/conda/lib/python3.7/site-packages/fastcore/dispatch.py in retain_type(new, old, typ, as_copy)
186 # e.g. old is TensorImage, new is Tensor - if not subclass then do nothing
187 if new is None: return
--> 188 assert old is not None or typ is not None
189 if typ is None:
190 if not isinstance(old, type(new)): return new
AssertionError: