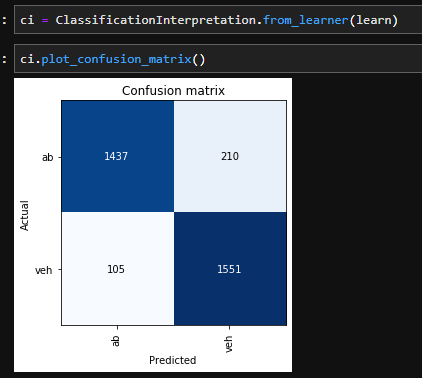
I wan to train a Resnet152 based binary classifier, using 20k images (10k in each category). My original images, are 2048x2048, however, their full size do not fit into GPU memory (RTX 2080Ti), so I’m using rescaling.
As suggested by Jeremy, I first fine-tunef Resnet152 on a smaller resolution (512), I achieved a very high accuracy of 0.9803, however, when I wanted to use max possible size, that fits the GPU memory (1536 pixels), I can’t achieve convergence nor overfitting and thus very puzzled by this behaviour. Any recommendations will be highly appreciated.
Here is the snippet of my code:
data = ImageDataBunch.from_df(path_to_images, df_images, ds_tfms=get_transforms(do_flip=True, flip_vert=True, max_rotate=None, max_zoom=1.0, max_warp=None), valid_pct=VALID_PCT, bs=16, size=512).normalize(imagenet_stats)
learn_512 = cnn_learner(data, models.resnet152, metrics=accuracy, bn_final=True, ps=0.5)
learn_512 .model = torch.nn.DataParallel(learn_512 .model)
learn_512 .fit_one_cycle(5, max_lr=1e-2)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.388392 | 0.292082 | 0.895884 | 07:37 |
| 1 | 0.354566 | 0.285786 | 0.944007 | 07:14 |
| 2 | 0.306108 | 0.237093 | 0.971852 | 07:26 |
| 3 | 0.255985 | 0.582608 | 0.971247 | 06:53 |
| 4 | 0.219943 | 0.210191 | 0.979722 | 07:06 |
learn_512 .unfreeze()
learn_512 .fit_one_cycle(1, slice(1e-6, 5e-3))
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.206563 | 0.474366 | 0.980327 | 08:53 |
learn_512.save(‘clf_512’)
The same, but now with 1536 resolution:
data = ImageDataBunch.from_df(path_to_images, df_images, ds_tfms=get_transforms(do_flip=True, flip_vert=True, max_rotate=None, max_zoom=1.0, max_warp=None), valid_pct=VALID_PCT, bs=16, size=1536).normalize(imagenet_stats)
learn = cnn_learner(data, models.resnet152, metrics=accuracy, bn_final=True, ps=0.5).load(‘clf_512’)
learn.to_fp16()
learn.model = torch.nn.DataParallel(learn.model)
learn.fit_one_cycle(5, max_lr=3e-4)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.596490 | 0.486517 | 0.862591 | 43:44 |
| 1 | 0.604683 | 0.507021 | 0.858656 | 43:34 |
| 2 | 0.601637 | 0.570700 | 0.836562 | 43:33 |
| 3 | 0.613324 | 0.517586 | 0.862288 | 44:10 |
| 4 | 0.587535 | 0.480734 | 0.878632 | 44:07 |
learn.unfreeze()
learn.fit_one_cycle(10, slice(1e-8, 3e-5))
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.616416 | 0.470562 | 0.897397 | 53:42 |
| 1 | 0.582632 | 0.473497 | 0.886501 | 53:33 |
| 2 | 0.590366 | 0.495948 | 0.885593 | 53:26 |
| 3 | 0.581906 | 0.475689 | 0.868341 | 53:56 |
| 4 | 0.563544 | 0.494985 | 0.858353 | 53:35 |
| 5 | 0.585111 | 0.491389 | 0.887107 | 53:32 |
| 6 | 0.589545 | 0.460681 | 0.895278 | 53:36 |
| 7 | 0.591109 | 0.535952 | 0.859262 | 53:52 |
| 8 | 0.593550 | 0.485988 | 0.883475 | 53:23 |
| 9 | 0.570294 | 0.468092 | 0.877421 | 53:22 |
Can anyone explain these results? It seems like the models is underfitting, but when I remove droput, and augmentation, it does not help either. Thanks!