We could absolutely delete this thread but, I’m not getting much help from the community, probably because we sometimes tend not to check some threads.
Problem - Managing test data without label with splits
Context:
The splits used in Arxiv and IMDB creates text and label properties for all data (for the test data as well).
e.g. pos/neg labels for IMDB:
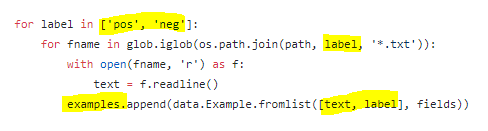
The code as shown above, will look for folders pos or neg in all specified paths. For lesson 4 nb, we’ve specified train and test, both of which are labelled. The folder structure is:
data/imdb/train/pos/…
data/imdb/test/pos/…
data/imdb/train/neg/…
data/imdb/test/neg/…
So, when the code (shown above), iterates over it, it finds data for train and test and thus successfully creates splits. Such splits have text and label properties for all examples.
struck at:
For Kaggle competitions, the typical structure of files will be:
data/imdb/train/pos/…
data/imdb/val/pos/…
data/imdb/train/neg/…
data/imdb/val/neg/…
data/imdb/test/…
If you notice highlighted part, there are no pos or negative folders for test-set. So, when we use the same code, in the absence of labels/folders, below code will return null/zero items thus our test-set split will be empty.
![]()
Steps taken so far:
Created dummy label for test-set with following structure. This created split with label all.
data/imdb/test/all…
My model had valid test data loader but I noticed below which I’m unable to understand:
a. The output has 3 probabilities against 2 classes. Is 3rd one for ‘all’ label?
b. These probabilities don’t add to one. If I pass these through softmax (after np.exp), the submission file has worst performance. While training, I have a validation set (20% of the train) which shows 85%+ accuracy thus I don’t expect the test to have this huge loss value.
c. The number of items in my test split has expected items but the number of rows returned by predict have 8-10 fewer rows in the outcome.
For cases where we don’t have labels for test data, how do we handle this?
- If we don’t specify any label for the test, the default code will add zero examples in test split. This is from the constructor’s loop.
- I tried adding a dummy label (‘all’), thus split has data. Unfortunately, prediction then has these 3 outcomes which I’m unable to understand:
a. The output has 4 probabilities against 3 classes
b. These probabilities don’t add to one. If I pass these through softmax (after np.exp), the submission file has worst performance. I do have a validation set (20% of the train) with 85%+ accuracy thus I don’t expect the test to have this large loss.
c. Even though split through has a correct number of rows for test data, for some weird reason, my outcome has 8-10 fewer rows than split.
Thoughts:
- Should my code be modified to check for test path and not assign label? (Sort of skipping all highlighted parts)?

- Is there any other method than using split for getting the model for NLP?
Environment:
p2.xlarge on AWS using fastai AMI (Virginia)
The code in Arxiv (lesson 4) is also similar.
Kindly advise.
cc’d: @rsrivastava, @Moody
#ImConfused #Needhelp