When I use Fast.ai to process some Chinese movie comments with the NLP algorithm, something weird happened with the text segmentation.
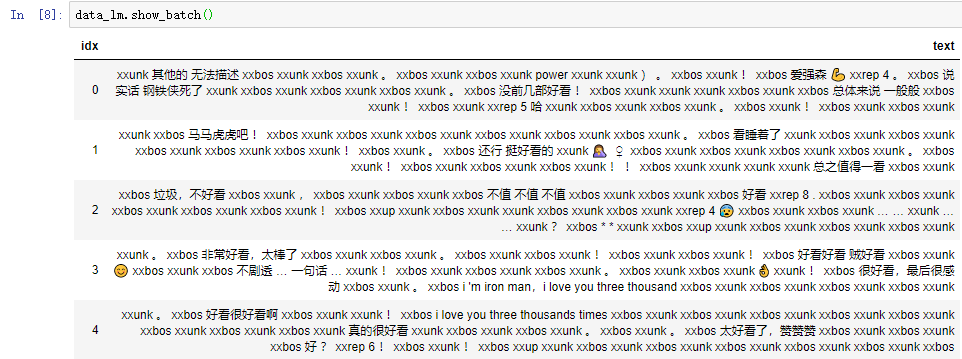
Just like the picture showed above, almost lots of words have been transformed wrong. For example, the words “好好看” should be divided into three words not a single one. And you can also see tons of unidentified words “xxunk”.
So I will appreciate it if you can so help me solve these questions:
- Can I use the python package named jieba (https://github.com/fxsjy/jieba) instead of the Fastai build-in text segmentation algorithm? It can work well with Chinese text segmentation.
- Does the pretrained model WK104 only support English? Does it mean that I can’t use it with Chinese?
- How can I solve this segmentation problem if I just use the Fastai build-in segmentation system?