Just for people who get an unbalanced dataset and would like to see how truncating can help, here is my first path Option1 (I know there are ways to deal with an unbalanced dataset, especially “punishing” the NN a good deal when it fail to predict the class with low amount of related data)
Option1 : truncate class1 and training with :
class1 : 141253
class2 : 141253
Now, I have far better results.
I think the unbalanced was clearly the problem, here.
FYI, I’m still using a stligthly different version of the IMDB Jupyter notebook.
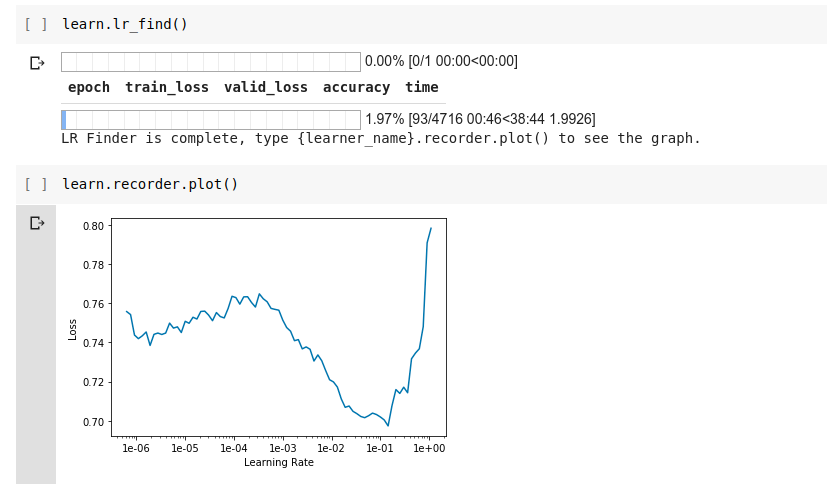
Learning rate :
I chose the value 1e-2 for my fit_one_cycle methode with 30 epochs :

Here are some of my first epochs from that same method :
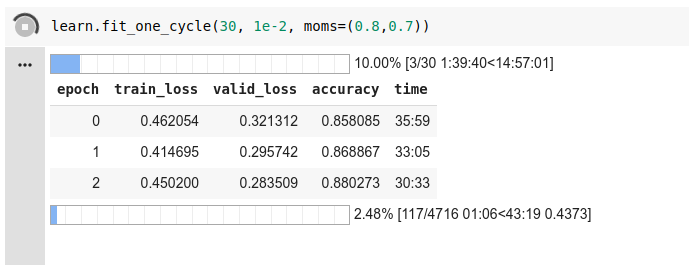
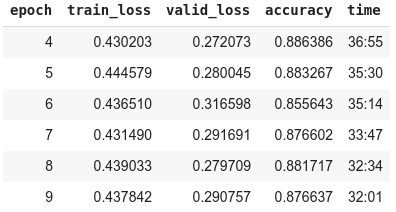
As you can see my train_loss and valid_loss values wouldn’t converge to 0 even if my accuracy was pretty high.
At this point I told myself this training was getting nowhere (I don’t know how to play with weight decay and dropout yet! I will soon, don’t worry  ) and that I needed to pick one of my saved model from the best epoch and unfreeze another layer. I took epoch9.
) and that I needed to pick one of my saved model from the best epoch and unfreeze another layer. I took epoch9.
After I unfroze the last 2 layers, I got :
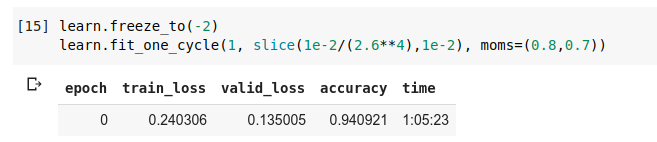
After I unfroze the last 3 layers, I got :
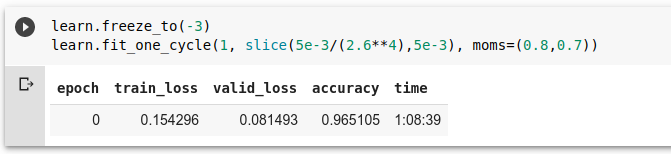
At this point I copied my jupyter notebook, and used inference of the last backed up model to try and predict some texts. My class1 and class2 were predicted right! 
learn.load('third-1e-2-epoch9-bouture');
learn.predict("my class1 text")
learn.predict("some class2 text")
Returning to my main notebook:
My last fit_one_cycle method with two epochs on a totally unfrozen model are now done.
The train_loss, valid_loss are still going lower and the accuracy higher.
Que demande le Peuple ?

Until I know more (in that field that keeps me awake at night ) :
Yes, truncating works!
Have a great week-end.
Stay safe and good luck.
Alexandre.