Hey guys, I’m tackling an NLP task and I’m having problems improving my model. It’s a text classification task and I’m of course using ULMFiT techniques to train my model. Thing is, I can’t even fit training data properly, let alone have a good enough model for my task. What do you guys reckon I should be doing?
I’ve tried using both LSTMs and QRNNs with no sucess without sucess.
I’ve considered the fact that I might be using a learning rate that’s too small but this is the graph I’m getting with lr_finder and I’ve tried everything from 1e-7 to 1e-2. Anything past that just gets the model to diverge (or should I try it out for a few epochs?)
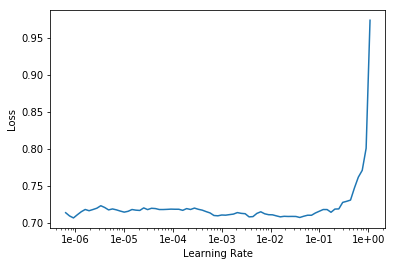
My model plateaus at a loss of 0.65, not that below of what the lr_finder function achieved which is pretty worrying.
Using various data cleaning methods the most I’ve achieved is 69% accuracy while other people have achieved ~80% accuracy.
Any pointers or help? Thanks!