Hi all.
I want to design a multitask unet network, with segmentation at its end, and per-image classification drawn from the encoder’s end (mid of unet).
Looking at forums, I find that many times people wrap the original network, with some new nn.module where the modifications are defined.
However, I’m not sure
(a) how each module can be correctly extracted from the original net, to allow the “forward chaining”?
(b) how to return two “forward branches” (here, x & y)
Being a layman, I tried the following naive (and probably awkward) approach:
learn = unet_learner(data, models.resnet34)
class MultiTaskUnetResnet(nn.Module):
def __init__(self,pretrained_unet_resnet34):
super(MultiTaskResnet, self).__init__()
self.unet_resnet34=pretrained_unet_resnet34
self.fc1 = nn.Linear(512 * 16 * 16, 200)
self.fc2 = nn.Linear(200, 3)
def forward(self, x):
for n in range(len(learn.model.layers)):
m = self.unet_resnet34.layers[n]
x = m(x)
if n == 7:
y = self.fc1(x)
y = self.fc2(y)
return x, y
a = MultiTaskResnet(learn.model)
Results indicate that this is a disaster (I get x=True here (?!!?), when debugging).
I beg anyone to show me the path to enlightenment 
Thanks in advance for any help!
Just to clarify first, what you call self.resnet seems to be a full unet here, right ?
Indeed. I now gave it a more detailed name.
Ok, so to I figured the way to access the encoder in fastai’s DynamicUnet is learn.model[0] (as DynamicUnet stores all its layers in a ModuleList). So I think you might want to do something like (to stay with the naive idea):
class MultiTaskUnetResnet(nn.Module):
def __init__(self,pretrained_unet_resnet34):
super(MultiTaskResnet, self).__init__()
self.unet_resnet34=pretrained_unet_resnet34
self.fc1 = nn.Linear(512 * 16 * 16, 200)
self.fc2 = nn.Linear(200, 3)
def forward(self, x):
x = self.unet_resnet34[0](x)
y = self.fc1(x)
y = self.fc2(y)
for m in self.unet_resnet34[1:]:
x = m(x)
return x, y
I didn’t test but I am pretty sure it should work. Other options would be to directly modify the code of DynamicUnet to make it do what you want (which might not be easy as it uses a fastai wrapper called SequentialEx that I didn’t explore much) or use a hook to store the value after the encoder. Also keep in mind that if you want to do that you need to create a custom loss that takes into account the fact that your output yields 2 tensors. That could look like this:
class DoubleLoss(nn.Module):
def __init__(self, loss_seg, loss_clf):
self.loss_seg = loss_seg
self.loss_clf = loss_clf
def forward(input, target):
input_sef, input_clf = input
target_seg, target_clf = target
return loss_seg(input_seg, target_seg), loss_clf(input_clf, target_clf)
Finally, you could add a wrapper around your loss tensors so that you can return Wrapper(loss_seg(input_seg, target_seg), loss_clf(input_clf, target_clf)) and call backward on it directly (basically, you would just need to implement a backward func that calls backward on the 2 losses). After that I think your multi task learner could work well with fastai API. I did not make any test so it is highly possible that some part of this proposition is wrong or incomplete, but it should at least get you started.
1 Like
Thanks for your reply!
I tried defining your MultiTaskUnetResnet class, but I quickly fail when tried:
learn_tmp = unet_learner(data, models.resnet34)
learn = unet_learner(data, MultiTaskUnetResnet(learn_tmp.model))
Which raised:
".../fastai/vision/learner.py in unet_learner(data, arch, pretrained, blur_final, norm_type, split_on, blur, self_attention, y_range, last_cross, bottle, cut, **learn_kwargs)
114 meta = cnn_config(arch)
–> 115 body = create_body(arch, pretrained, cut)"
That raised:
".../fastai/vision/learner.py in create_body(arch, pretrained, cut)
54 def create_body(arch:Callable, pretrained:bool=True, cut:Optional[Union[int, Callable]]=None):
—> 56 model = arch(pretrained)"
That raised:
".../modules/module.py(493)__call__()
…
–> 493 result = self.forward(*input, **kwargs)`"
At which point I found that input=True, instead of any other meaningful tensor.

I think you should write
learn = unet_learner(data, resnet34)
model = MultiTaskUnetResnet(learn.model)
learn.model = model
1 Like
That simple solution helped a lot. Thanks!
All this got me quite far… up to the point where no errors arise, but yet -
the network doesn’t train (even on a small dataset).
Here’re my advancements after @florobax’s last hint:
- After doing
learn.model = model, I’ve got an error of the sort: “x.orig doesn’t exist… in Merge layer”. So, after having a glimpse inside the SequentialEx class (discussed here too), I manually implanted that “orig” member in each of the layers I pass through.
- The loss function correctly accepts both types (segmentation + classification) of predictions & targets. I’ve checked that the images & masks correctly match, and that the loss calculation is correct.
But…
- Since the loss values don’t go down when trying to train, I’ve tried monitoring the mean & std of the layers along the way, as is demonstrated in this fastai course notebook.
What I found was quite interesting: The means and stds of the layers activations were quite regular (though somewhat static, see left image below), but the batchnorm layer was crazy, having the value of “3.0” in the 1st batch, and “0” in the 2nd and 3rd batches, going on like that cyclically (see blue line in right image below). Anyone familiar with such a behavior??
.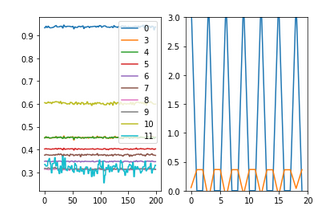
Now all this makes quite a new question that probably shouldn’t appear under this topic. But there is a chance that it actually is directly involved in the “branching out from the middle of a unet…” effort. So I’ll relocate this reply depending on the answer I find for this issue.
Anyway, here’s how the updated model looks like:
a. Architecture described by “learn.model”:
MultiTaskUnetResnet(
(unet_resnet34): ... <identical to the original unet_res34 model>
(clf_layer): AdaptiveConcatPool2d(
(ap): AdaptiveAvgPool2d(output_size=(1, 2))
(mp): AdaptiveMaxPool2d(output_size=(1, 2))
)
(fc): Linear(in_features=2048, out_features=3, bias=True)
)
b. My code for the architecture:
class MultiTaskUnetResnet(nn.Module):
def __init__(self,pretrained_unet_resnet34):
super(MultiTaskUnetResnet, self).__init__()
self.unet_resnet34=pretrained_unet_resnet34`
self.clf_layer = AdaptiveConcatPool2d((1,2))
self.fc = nn.Linear(2*1024, 3)
def forward(self, x):
res = x
res.orig = x
nres = self.unet_resnet34[0](res)
res.orig = None
res = nres
res_clf = res.clone()
res_clf = self.clf_layer(res_clf)
res_clf = self.fc(res_clf.view(res_clf.shape[0],-1))
for l in (self.unet_resnet34[1:]):
res.orig = x
nres = l(res)
res.orig = None
res = nres
return res, res_clf
learn.model = MultiTaskUnetResnet(learner.model).cuda()
How do you compute the gradients in the end ? You call backward on both losses I guess ? That could cause problems if one loss create gradients that are an order of magnitude higher than the others. However I am absolutely not sure this is your problem here. I have actually no idea how a batch norm layer usually behaves, I never checked that (and I guess I should). Something you could try is checking the gradients to make sure they are nonzero and that something is actually learned. You could use a callback like:
class MonitorGrad(LearnerCallback):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.grads = []
def on_backward_end(self, **kwargs):
grads = []
for p in self.learn.model.parameters():
if p.grad is not None:
grad = p.grad.float().mean()
grads.append(grad.item())
mean_grad = sum(grads)/len(grads)
self.grads.append(mean_grad)
It will store the mean gradient on each batch. As I actually have no idea where you problem comes from, it could very well be useless, but probably worth the try.