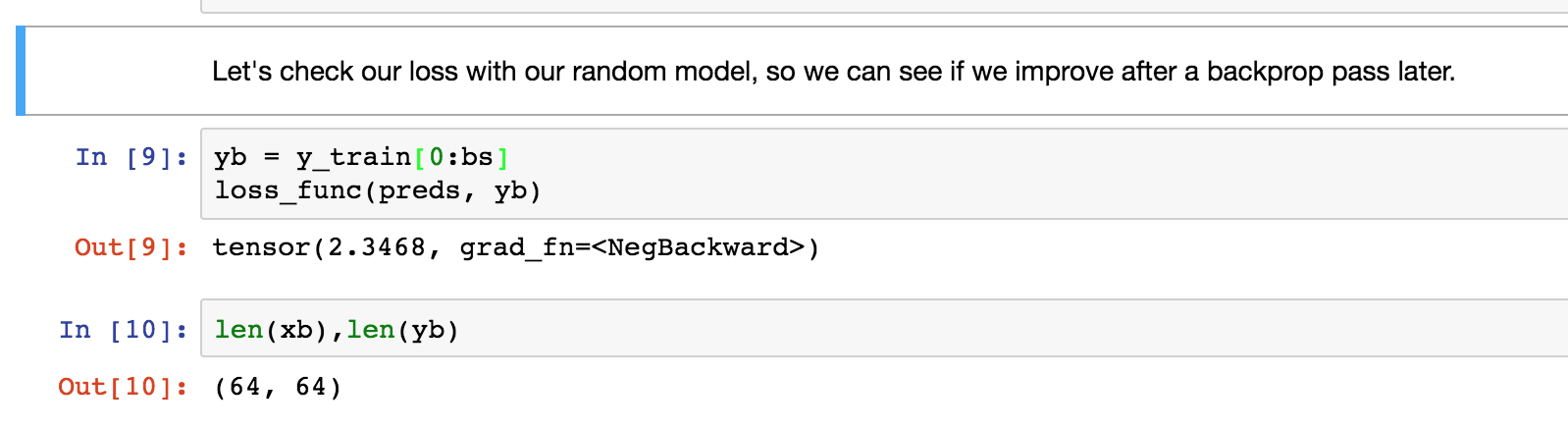
In the notebook, the randomly initialized model’s loss is later compared to the trained model’s loss to show that the loss has decreased, however, it’s not a true apples to apples comparison since during training the xb and yb variables have been modified and now the loss is being computed on a much smaller batch of 16 instead of the original 64. The loss does decrease when compared to the original batch but not as much as it appears unless I’m doing something wrong.
Perhaps a method needs to be added to always get the same original batch when comparing the trained loss.
I’m probably reading it too literally when you say “Let’s check the loss and compare to what we got earlier.” I read that to mean that the loss should be computed on the “exact” same batch of xb, yb for comparison purposes.
I had mentioned about 2 months ago about possibly adding accuracy into this notebook when it was in its earliest stages. I still think it would help the reader to see the accuracy as well as the loss to see how that improves as the loss improves and to understand how the predictions correlate to the target values. It seems like that discussion is somewhat missing from the notebook. Others may not agree. Anyway, I’ve gone ahead and submitted a PR with a sample of what I’m thinking.
PyTorch will even create fast GPU or vectorized CPU code for your function automatically.
This left me wondering how this magic works. Is there a reference for further reading we could add here?
Section Switch to CNN
For people unfamiliar with torch.Tensor.view and Conv2d, would it be helpful to explain the basic mechanics of how the data flows here? E.g. The input channel of size 1 in the first Conv2d layer is created by reshaping the data using xb.view(-1,1,28,28) into image data of size 28x28 with 1 color channel
Typos:
If you’re lucky enough to have access to a CUDA-capable CPU
I like the first notebook, I think it is a good starting point and demystify the high level fastai library. I think this will make people have a general idea of PyTorch and when they read code outside of fastai community, they will understand code in a more “raw” PyTorch code.
Just notice fastai_v1\doc\fastai_full.svg, is it generated by some library?
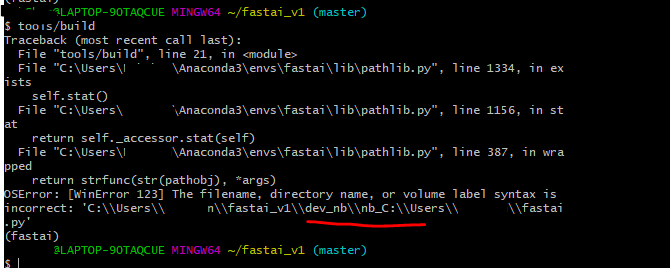
I would like to make a small PR to start with, but I stuck in the tools/build part, I am using Window 10, it seems like the path is not correctly joined. I have tried following the steps in contribute.md, would love any help here, thank you!
(I think in line 16 for tools/build.py, the file should be a relative path but it return absolute path instead and causing the error, not sure if it is Window specific?..) for file in sorted(path.glob('0*ipynb')):
I am able to fix the path by changing it by either
for file in sorted(glob.glob('0*ipynb')): # Not sure is it a difference between pathlib.Path.glob and glob.glob
set path = Path(.)
Note that I am running tools/build from the fastai_v1 directory with git Bash
@nok do you mind asking 2) and 3) over in #fastai-dev and also tagging @stas (who wrote the tools/build thing). You’ll also find a thread there discussing that tool (which is entirely optional for getting started BTW).
One thing I’ve been wondering about this notebook and in subsequent notebooks is that since the log_softmax is removed from the neural network and replaced by the use of F.cross_entropy in the loss function, should it be mentioned somewhere either in this notebook or some subsequent notebook that if the prediction percentages were desired in order to see how confident the prediction was, the outputs would need to be run through the softmax function. Something like the code below for this notebook. I haven’t seen this discussed so far in the notebooks I’ve gone through but I haven’t gone through all of them so perhaps this is discussed in a later one. Or perhaps I’ve not got any of this correct and am misunderstanding. Thanks for any clarification.
For sure. We haven’t started on the whole “model interpretation” stuff yet, so this will go there. I don’t think it need go in this initial pytorch tutorial however.
In Refactor using DataLoader, there is a ... in the sample code being replaced, which isn’t used in other examples.
In Add validation, it might be worthwhile to add a reference/example for why we use model.train() and model.eval(). There is a quora link just above on why shuffling is important, could include something like that for batch norm.
In Switch to CNN, xb.view() is first introduced, but not explained until the nn.Sequential section. Might make more sense to add that explantation in the same section that Conv2d is explained.
In Switch to CNN, First try and nn.Sequential, this code block is present:
Hi @jeremy ,
I think it’s really really good on the “all you need for your understanding part”.
But one thing I’m missing (like in most tutorials) is the “what to do if again something has gone wrong in your model” part. I don’t find traces and debugging helpful. What I then do is logging stuff like that:
I strongly suggest folks use the debugger for this FYI - but either way it’s out of scope for this tutorial (and I’m glad you’ve found a hook-based solution that works for you; you might like the new Hook functionality in fastai v1!)