To continue the documentation of our development of the library, here is where we’re at in terms of optimizer, training loop and callbacks (all in the notebook 004).
Optimizer and easy hyper-parameters access
With a very good idea that I stole from @mcskinner, the optimizer is now wrapped inside a class called HPOptimizer. The four hyper-parameters mostly used are properties of this HPOptimizer named lr, mom, wd and beta, and each has its custom setter that will actually put the value in the right place of the internal optimizer param dictionary.
- lr stands for learning rate and is the same in every optimizer
- wd stands for weight decay and is also the same in every optimizer. It does L2 regularization and not true weight decay (see here for more details on the difference).
- mom stands for momentum, which is the momentum in SGD and RMSProp, and the first element in the betas tuple in Adam.
- beta is the second elements in the betas tuple of Adam, or the alpha in RMSProp
For the end user, you create this HPOtimizer by passing model parameters, an opt_fn (like in fastai) and a initial lr like this:
opt = HPOptimizer(model.parameters(), opt_fn, init_lr)
Then you can access or change any of those hyper-parameters by typing opt.lr = 1e-2, which is far more convenient than in fastai.
This doesn’t support differential learning rates yet, but that will be an easy change once we have decided how to represent the different groups of layer, we’ll just have to adapt the setter for lr (and wd if we want) to handle it.
The training loop
In the current fastai library, the training loop has progressively become a huge mess. This is because each time someone has added something new to the library that affects training, they added a few more lines (or extra arguments) to the training loop. So when a beginner now looks at what is the core of training, he can’t see the important steps. And on the other side, each of those additions (like the training API, half-precision training, swa or stuff specific to the LMs) have bits of code in several places which also make them difficult to understand.
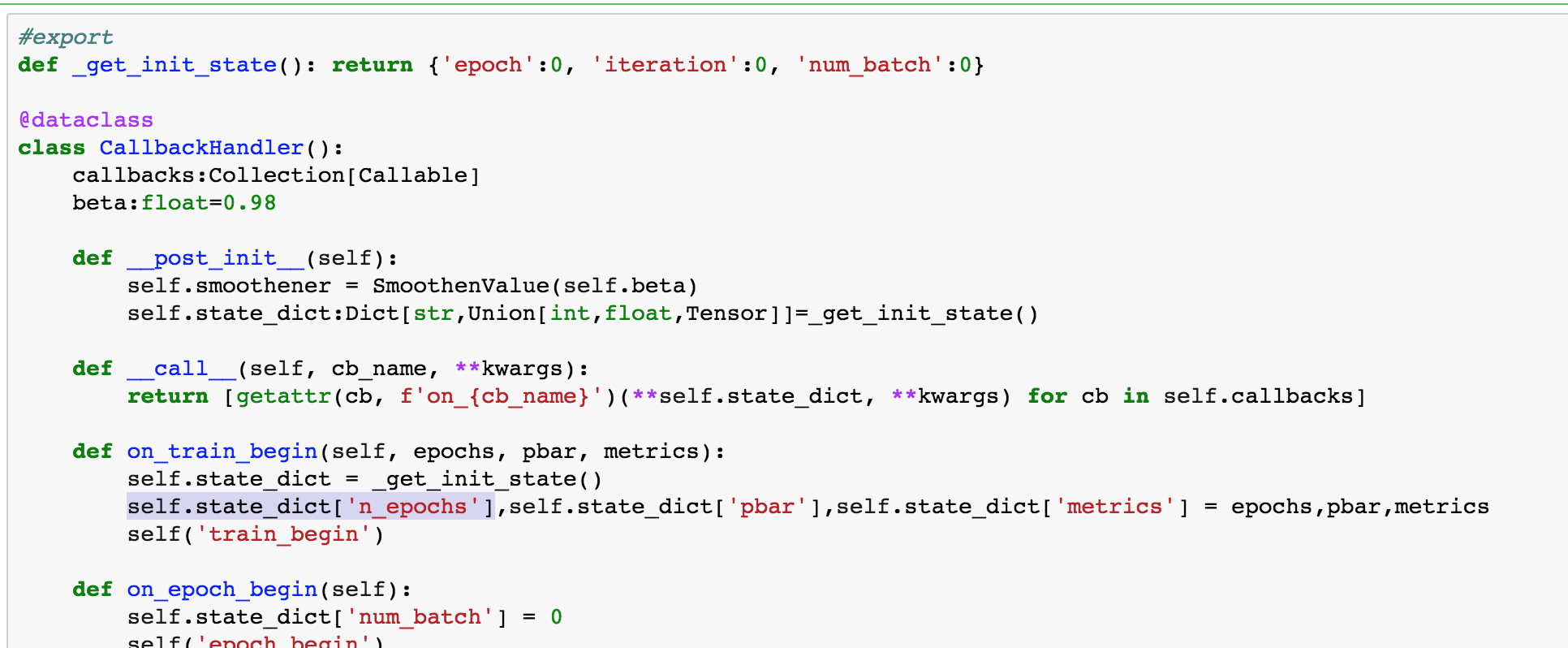
For fastai_v1, we have decided to be more pedagogic, and the training loop won’t move from its version in notebook 004:
def fit(epochs, model, loss_fn, opt, data, callbacks=None, metrics=None):
cb_handler = CallbackHandler(callbacks)
cb_handler.on_train_begin()
for epoch in tnrange(epochs):
model.train()
cb_handler.on_epoch_begin()
for xb,yb in data.train_dl:
xb, yb = cb_handler.on_batch_begin(xb, yb)
loss,_ = loss_batch(model, xb, yb, loss_fn, opt, cb_handler)
if cb_handler.on_batch_end(loss): break
if hasattr(data,'valid_dl') and data.valid_dl is not None:
model.eval()
with torch.no_grad():
*val_metrics,nums = zip(*[loss_batch(model, xb, yb, loss_fn, metrics=metrics)
for xb,yb in data.valid_dl])
val_metrics = [np.sum(np.multiply(val,nums)) / np.sum(nums) for val in val_metrics]
else: val_metrics=None
if cb_handler.on_epoch_end(val_metrics): break
cb_handler.on_train_end()
def loss_batch(model, xb, yb, loss_fn, opt=None, cb_handler=None, metrics=None):
out = model(xb)
if cb_handler is not None: out = cb_handler.on_loss_begin(out)
loss = loss_fn(out, yb)
mets = [f(out,yb).item() for f in metrics] if metrics is not None else []
if opt is not None:
if cb_handler is not None: loss = cb_handler.on_backward_begin(loss)
loss.backward()
if cb_handler is not None: cb_handler.on_backward_end()
opt.step()
if cb_handler is not None: cb_handler.on_step_end()
opt.zero_grad()
return (loss.item(),) + tuple(mets) + (len(xb),)
If you skip all those annoying calls to this cb_handler object, you have the simple training loop:
- range over epochs
- go through the training batches xb, yb
- call the model on xb
- compute the loss between the output and the target yb
- compute the gradients (loss.backward())
- do the optimizer step
- zero the gradient for the next step
- (optional) compute the loss on the validation set and some metrics
So why add all those lines with cb_handler? Well since we don’t want to change the training loop to leave it clear and simple, we have to code all the things that affect this training loop or use information inside it elsewhere. That’s why there is a callback function between every line of the fit function: to code what should go between those lines in a different object.
Callbacks
The guideline to add a new functionality that goes with training in the fastai_v1 library will be to do it entirely in a Callback. This will also help clarity since the code for a given piece to add will all be in one place. To do that, callbacks have access to everything that is happening inside the training loop, can interrupt an epoch or the training at any time and can modify everything (even the data or the optimizer). Just look at the example called EyeOfSauron to see how it’s possible.
As examples for now, you can see how the LRFinder is completely implemented inside a callback (just missing the save the model at the beginning and the load at the end but that’s an easy add once those functions exist), or a 1cycle schedule.

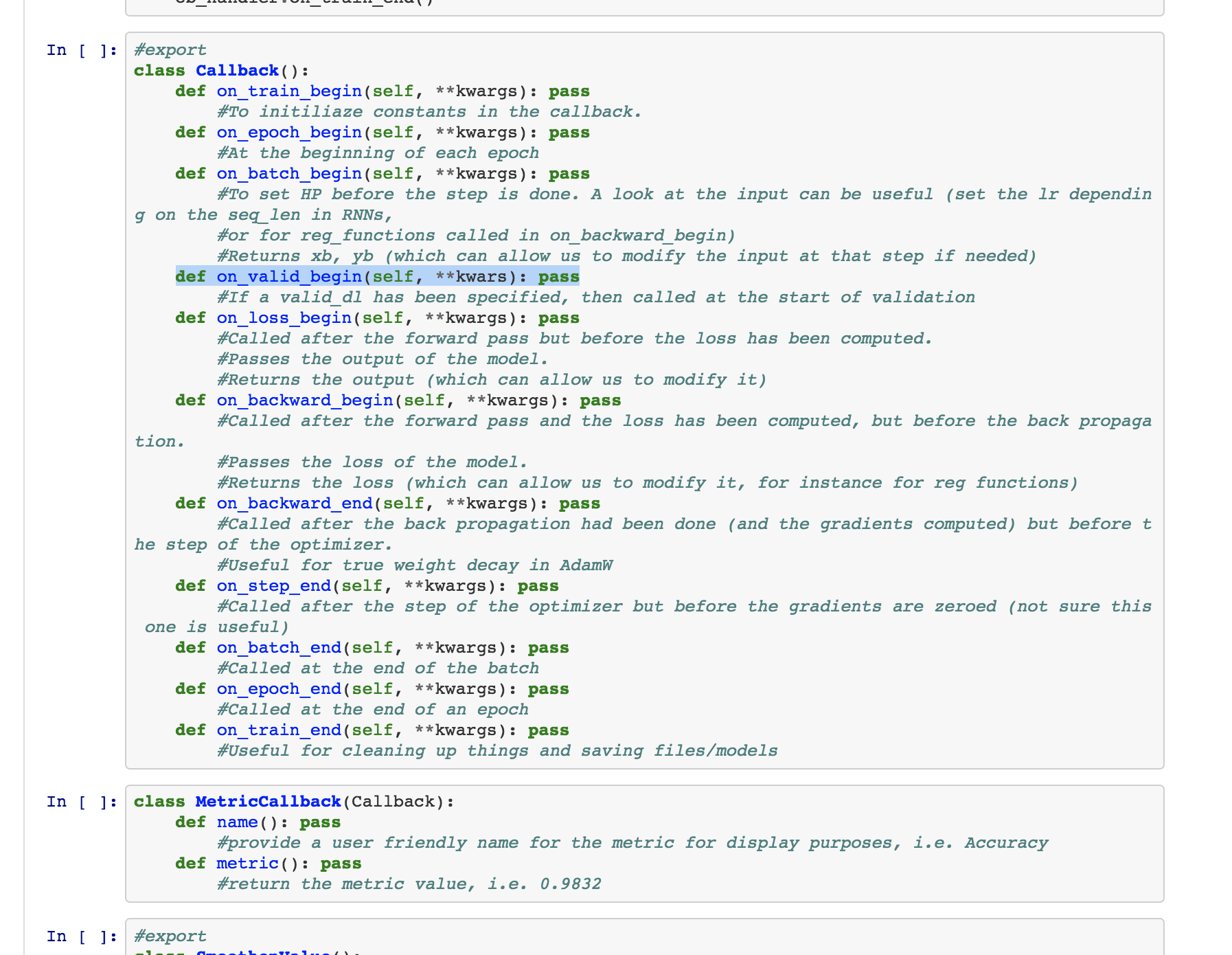
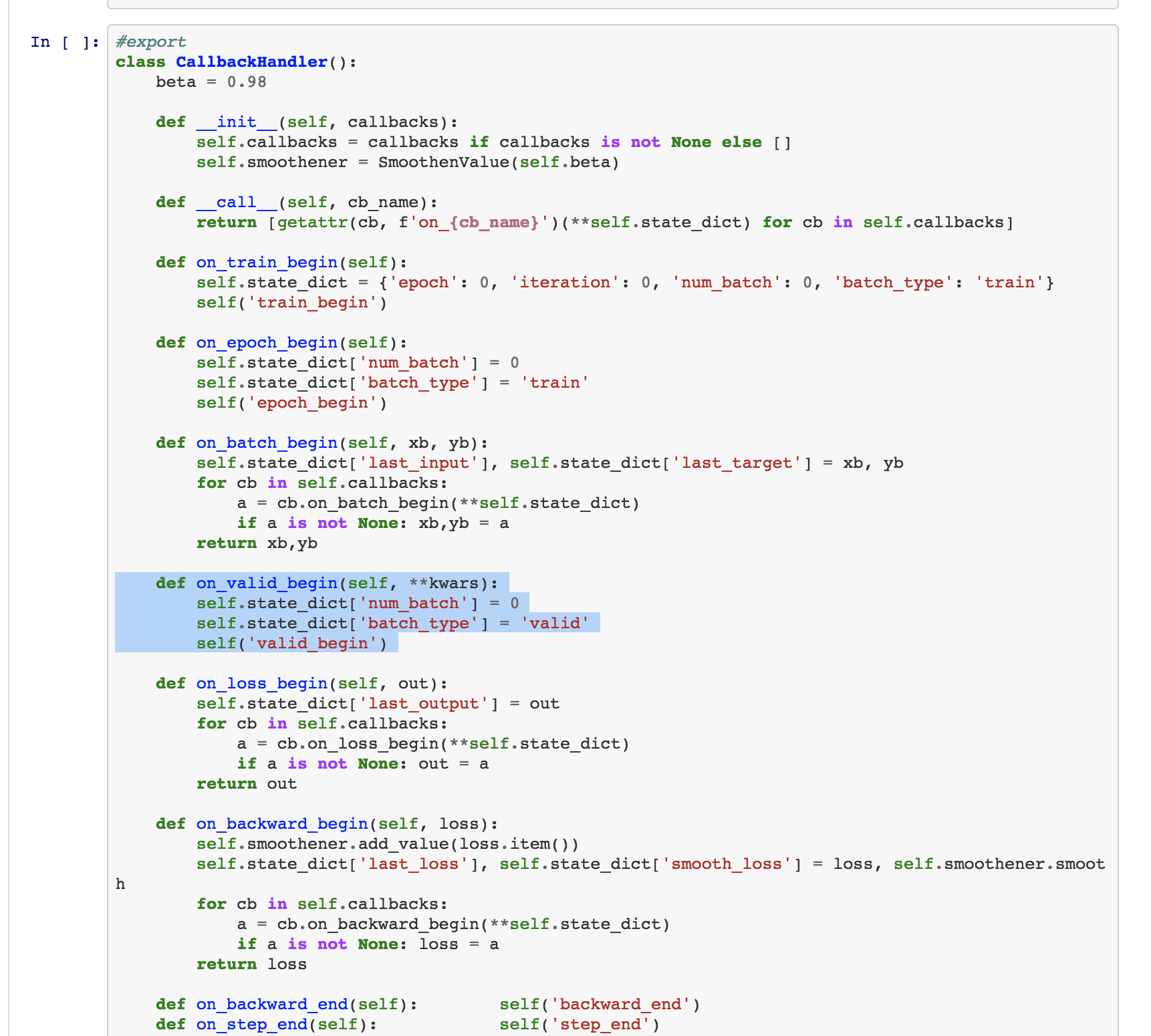
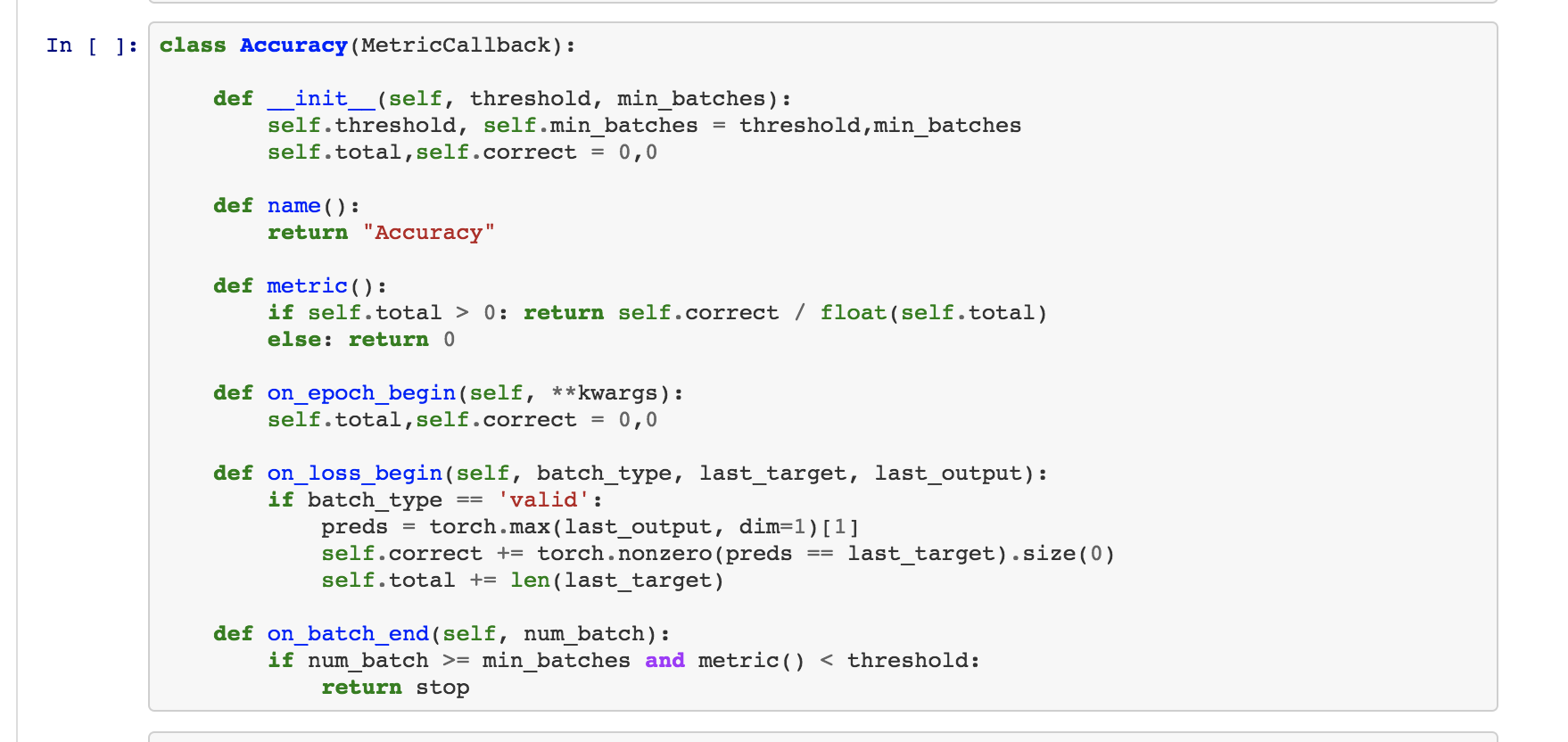
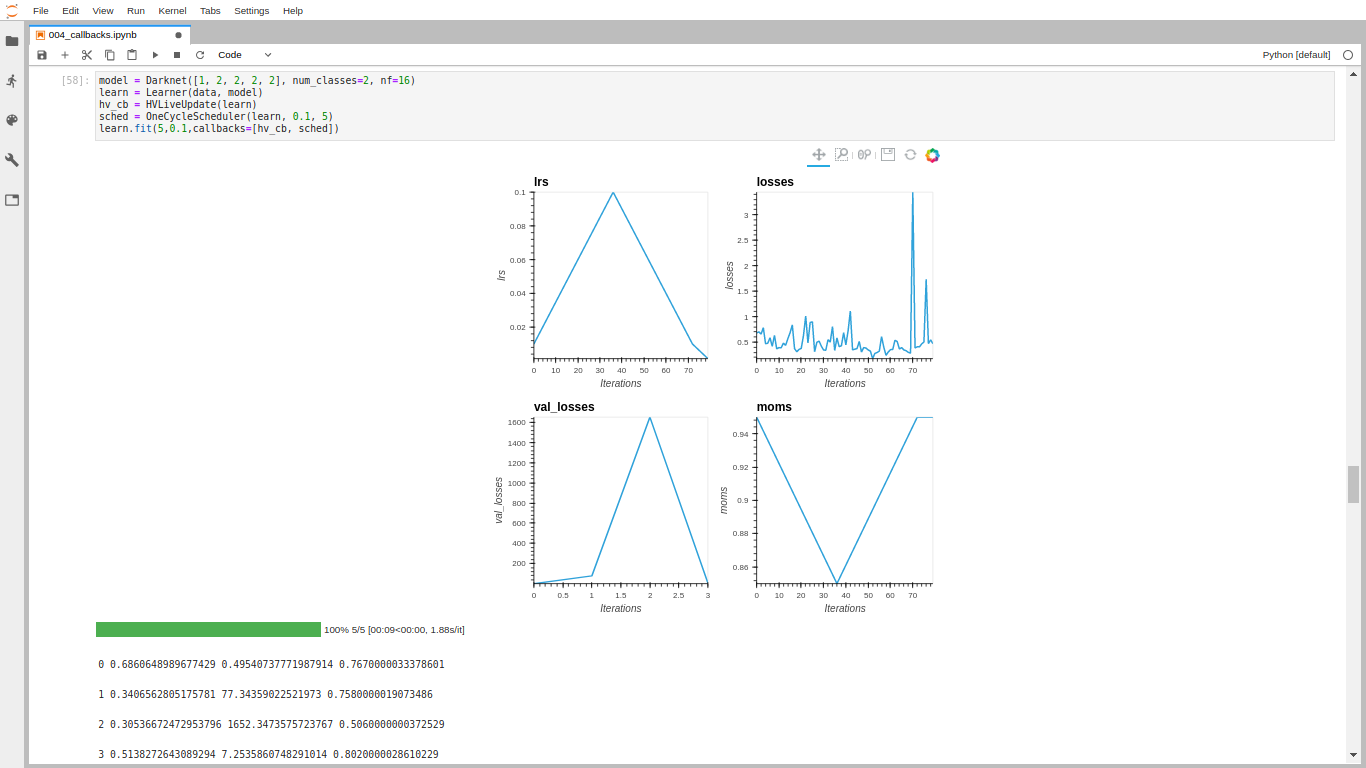
 Inside a callback, you can pop the parameter iteration from the kwarg to do something every n batches.
Inside a callback, you can pop the parameter iteration from the kwarg to do something every n batches.