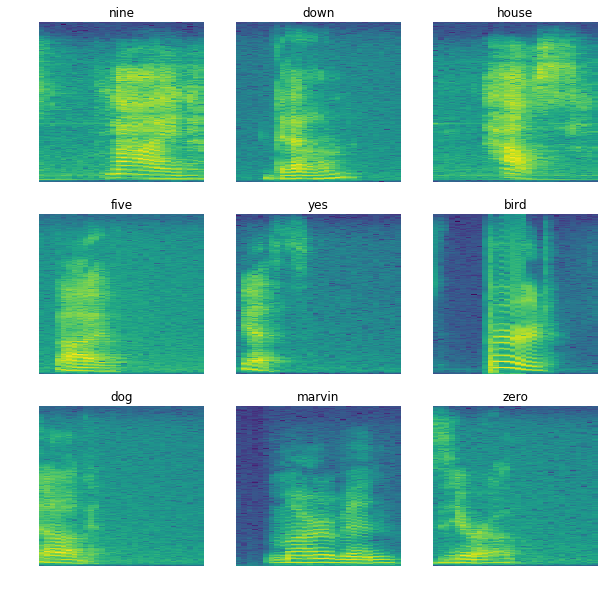
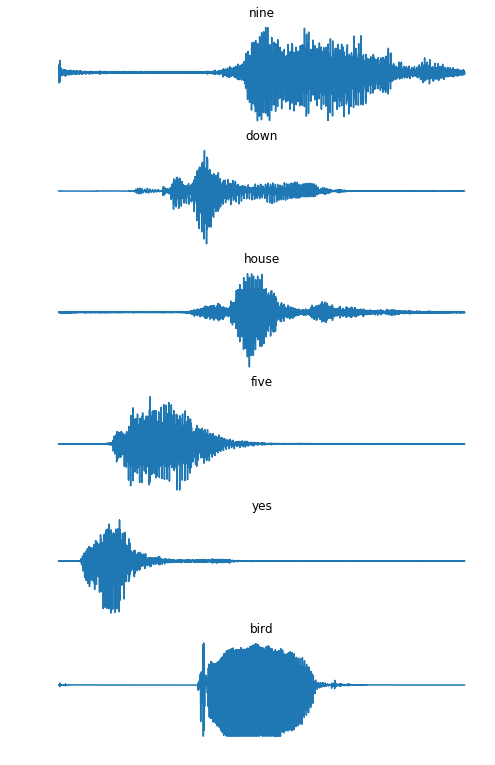
There’s a new Kaggle competition sponsored by Tensorflow and Google Brain. If some of you are considering doing some sort of image recognition off of the audio–>pictures, I’ve put together a translation kernel to get people started.
Let me know if there are any issues with the kernel. I’ve included two basic functional translation options
Caveat: Training set is (1 GB zipped) and Test set is (2.5 GB zipped), be sure to have a good network connection and enough storage space for the 64k audio wave files
Since this isn’t using fastai, perhaps you can run it as a “real” kaggle kernel so we can see the output.
Also, I think you could add some more prose to explain what the data is, how it fits together, etc. Since I’m not familiar with this competition, I got a little lost. It’s nice when EDA doesn’t assume any background knowledge about a dataset or problem, I think.
Thanks, I’ve converted to scipy, so that it will run on the Kaggle Kernel. I still had to comment out the parts of the script that actually write to disk.
Thanks for the other comments, ill update the notebook with the more general details as well.
BTW I think it would be nice to briefly explain what a spectogram is, and why they matter in this competition. (I believe generally people do speech recognition by doing CNN on the spectogram?..)