Interesting that Tesla are considering NeRFs may provide “foundation models for computer vision because they are grounded in geometry and geometry provides a nice way to supervise networks, and frees us of the requirement to define an ontology”
I dream of developing a system to 3D scan industrial equipment like these switchboards, and being able to zoom in close to read the ferruled wire numbers. I’m not sure NeRF would be the best way, but may be fun to explore.
I find NeRF’s fascinating as well. instant-ngp by Nvidia is extremely impressive in how fast it trains (30-60 seconds) and the massive speedups they were able to achieve over older NeRF papers. If you’ve worked with photogrammetry before, it’s easy to recognize the breakthrough in quality and speed this will provide. It’s still pretty rough around the edges currently and I think it needs a few more iterations to be truly useful, but it seems extremely promising. instant-ngp is a little tricky to get set up, but it’s pretty fun to play with. I hope they extend it to incorporate SLAM, which is a pre-processing step that calculates the location of the camera for each image, in the next iteration as that is by far the slowest part currently and is not included in the 30-60s training time.
Here is a nerf I did of a shelf in my basement. The results aren’t super clean, especially compared to some of the examples I’ve seen, but I think it gives you a pretty realistic expectation of what you currently get from the network.
One thing to watch out for to temper your expectations is that many nerf video renderings follow the same path as the original camera does which makes the results look better than they would if random viewpoints are shown. The ‘floaters’ are much less visible when the rendering camera track matches the track that the camera that captured the input images took and is something that is very easy to do in the instant-ngp rendering application. This makes sense as ‘floaters’ are incorrect positional predictions and these incorrect predictions must still make sense visually from the original positions and perspectives of the input images that were used to train the model.
It a good problem statement, as this paper shows ([2203.04424] SLAM-Supported Self-Training for 6D Object Pose Estimation); self supervised training from slam can help in having consistency among the pose estimates. The camera pose can be derived from the object pose using extrinsics (of the camera). This pseudo camera pose can be used as decent geometrical prior for NERF’s.
iMAP - Implicit Mapping and Positioning in Real-Time - live operation without prior data, building a dense, scene-specific implicit 3D model of occupancy and colour which is also immediately used for tracking
Stero Radiance Fields (SRF): Learning View Synthesis For Spaarse Views of Novel Scenes - NeRF designed to learn a single scene with a neural network from scratch, which takes 2-3 days. SRF learns structure instead of over-fitting on a scene. SRF generalizes to new scenes in 10-15 minutes of fine-tuning achieving significantly sharper, more detailed results than scene specific models. [Video]
BARF : Bundle-Adjusting Neural Radiance Fields [arxive] - One limitation of NeRF is its requirement of accurate camera poses to learn the scene representations. BARF facilitates for training NeRF from imperfect (or even unknown) camera poses through joint learning neural 3D representations and registering camera frames [Video].
Great to see folks here who are also interested in NeRF!
It has been a pretty active research field recently. One of the impressive use cases is to scale up NeRF models to city street views. (I wrote a blogpost to summarise its paper, in case you are interested to learn more)
instant-ngp is promising, though it’s core part is written in CUDA which is quite unfamiliar to me. (I wonder if it’s feasible to port the part into JAX to make the code more accessible without compromising too much of the speed gain)
Maybe relevant to the discussion here, Self-Calibrating Neural Radiance Fields is one variant of NeRF which jointly learn the 3D scene and camera parameters.
Thanks! I just took pictures with my phone and used the colmap script included in the repo to calculate the camera poses. Calculating the poses is pretty slow with the script which is why I was talking about SLAM in my post. I’ve started to read some of the suggestions in the responses to look into faster SLAM.
FYI
Recently found this project - Using custom data - nerfstudio
This is pretty solid and integrated
Worth taking a look if you are interested in the field!
thanks for sharing… I’m very interested in nerfs (especially single shot or few sample variants)… Also just about anything that infers 3d structures from pixels (occupancy networks etc).
great stuff, so you take a bunch of pics with the phone from different angles and use that script to calculate the poses, when you say very slow, how slow do you mean? what hardware and speed are we talking about here? thank you again for sharing, I will try to experiment with this latest version
Calculating the camera poses takes roughly 10-100x more time than training the Nerf itself when using the provided colmap script. It’s been a while since I did the shelf Nerf but it was between 50-100 images I believe and the colmap script took somewhere between 10 min and an hour, I got bored waiting so I left and came back so don’t know exactly how long it took. Training the Nerf took around 1 min on a 3090.
great stuff, I have been experimenting with instant Nerf and it works really great, and pretty fast with an RTX 3090. Next steps, a few things to get your perspective on:
3d human models from nerf
I am very interested as well in the creation of full human 3d models that are posable from nerf, see this: EVA3D - Project Page
and many other references, anything that you guys have seen that is worth exploring regarding this area feel free to share it here as well
I found this paper, Baking Neural Radiance Fields for Real-Time View Synthesis that post processes a trained nerf into a voxel-based representation that can render interactively (once loaded). Quality is pretty good. I have yet to pull the code and do anything with it…
includes a youtube video giving a high level overview of the paper.
at the bottom of that link there are links to interactive (webgl-based) viewers of the classic nerf examples… (takes a bit to load… but once loaded pretty responsive…
interesting @johnrobinsn , voxel representation, I wonder if that could then be imported into Blender, Houdini, etc because this is one of the issues we have, the marching cubes alg that we use to export Nerfs to Blender of Houdini produces 3d models that are just not good enough, pretty rough
yes @johnrobinsn , they use google imagen I think, there is a pytorch implementation that uses stable diffusion:
however, they indicate:
" This project is a work-in-progress , and contains lots of differences from the paper. Also, many features are still not implemented now. The current generation quality cannot match the results from the original paper, and many prompts still fail badly!"
So this is a great direction, we gotta keep an eye on any combo of Nerfs+Guided Diffusion
Im also very interested in the latest research about using Nerf to create 3d models of human figures that you can then pose and animate, this is already being done, but its recent research and havent found code or systems that we can test yet
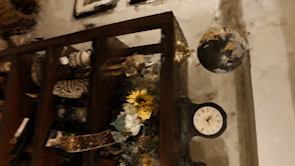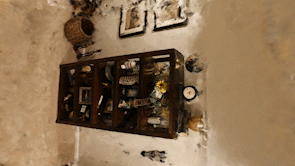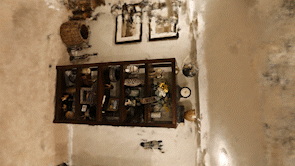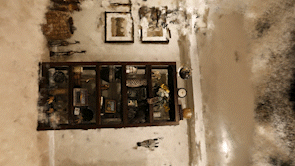

{kind=link}