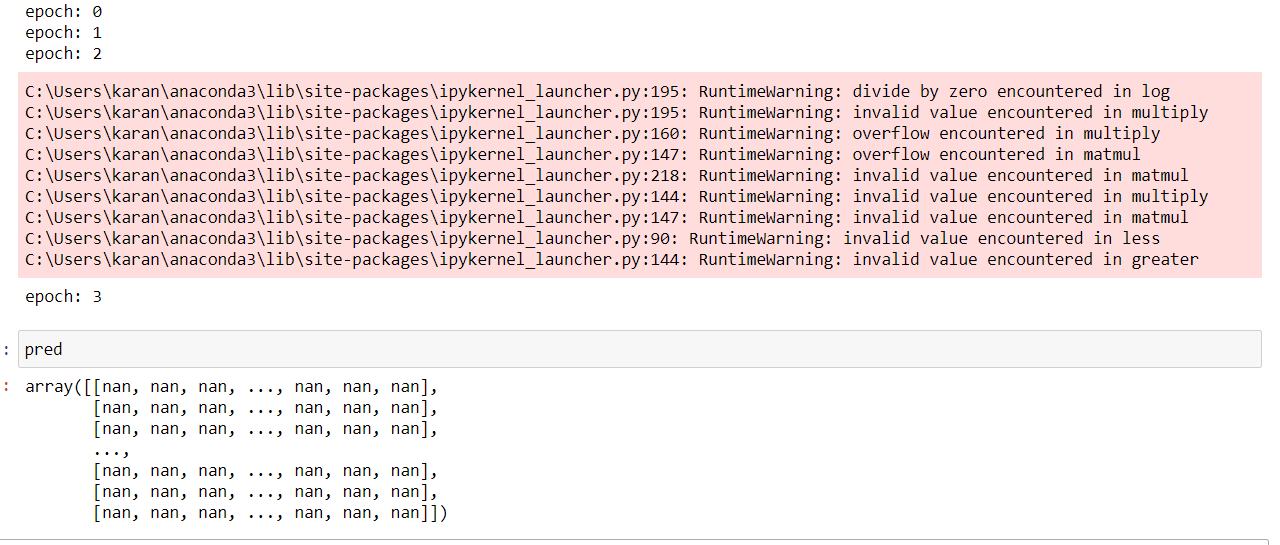
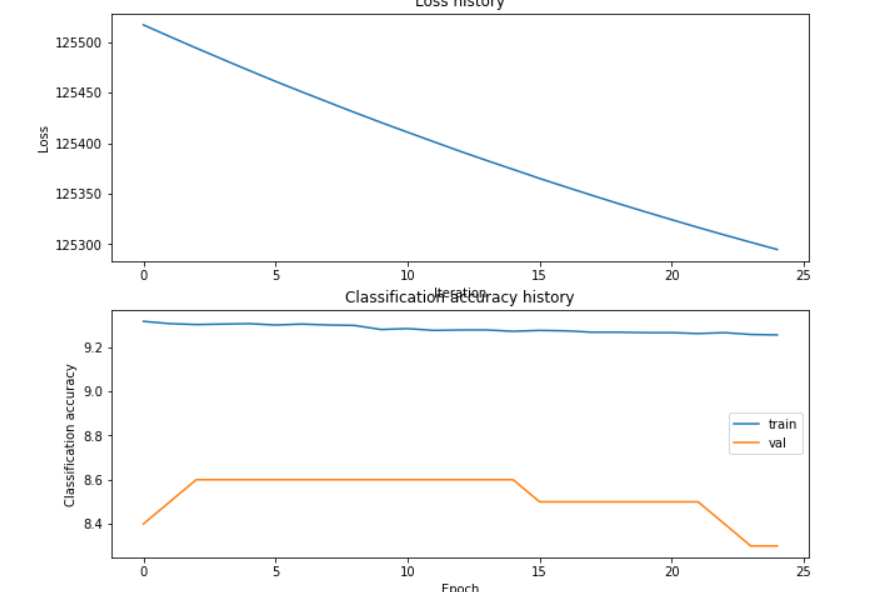
I have created a Neural Network from scratch with loss functions as cross entropy loss. I am getting the nan in the predictions each epoch in each batch after few epochs. I have initialized the weights randomly, does anyone has any idea what could be the issue?
I have verified my implementation of Softmax using the in-build softmax function, but I am still facing the issue.
Most probably, according to me, the issue is caused by the backpropagation of cross-entropy loss with respect to Soft-max, can anyone guide me from where can I find the code for backpropagation of cross-entropy loss.
a naive softmax implementation (exp(x) / exp(x).sum()) is not numerically stable: exp(x) can easily overflow or underflow. Test your implementation with x=[1000.0] to see if that’s the case. To fix the issue, subtract max(x) from x before computation:
import numpy as np
def naive_softmax(x):
s = np.exp(x)
return s / s.sum()
def stable_softmax(x):
return naive_softmax(x - max(x))
>>> x = np.array([1000.0])
>>> naive_softmax(x)
__main__:2: RuntimeWarning: overflow encountered in exp
__main__:3: RuntimeWarning: invalid value encountered in true_divide
array([nan])
>>> naive_softmax(-x)
array([nan])
>>> stable_softmax(x)
array([1.])
>>> stable_softmax(-x)
array([1.])
Additionally, softmax and cross-entropy can be fused into single layer to further improve stability of the computations.
I am building a simple NN, and the first warning which I was getting was related to Softmax, after using the in-build function, the next warning which I am getting is related to the back propagation of cross-entropy loss, with SoftMax.