Hi all, I have been meaning to understand how the gpt-2 model is implemented in PyTorch from scratch.
So far, I understand the paper very well, and the theory behind how the model works - Transformers, Decoder only block with 12 layers etc.
However, I have been looking at the source code of the model in gpt-2 library, and hugging face implementation, and need help with understanding the source code.
I was wondering if somebody else is interested in this, and we could together write an article similar to the annotated transformer to make it easy for everyone else in the future who wishes to understand the source code and implementation of the model.
Was wondering if anybody else is keen? I am happy to provide insights about the model, theory, working etc and understand it well but really need help grasping the source code.
Hey @arora_aman how’s the blog going. I’ve recently started with transformers and I’m really interested in this building it from scratch using the pytorch modules as well. Would love to collaborate if you’re still interested
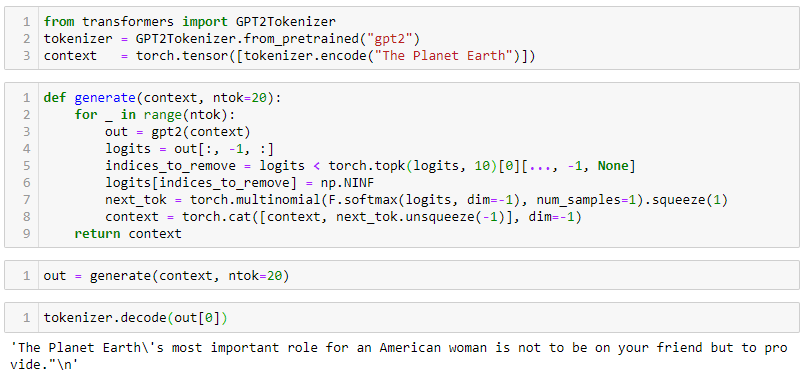
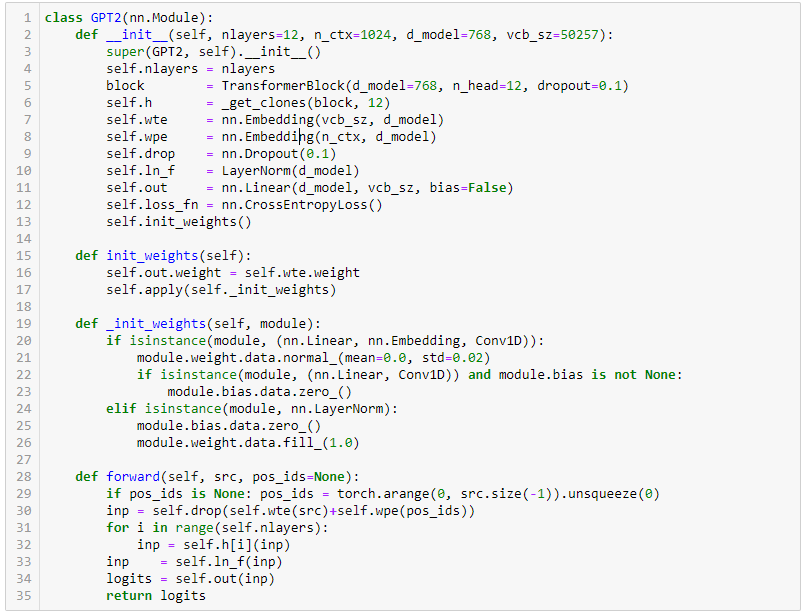
Thanks @averma, I am very close to rewriting the whole GPT-2 in pure pytorch. In fact, I have rewritten the whole model, but I am just in a process of trying to reuse the pretrained weights provided by Hugging Face.
Also, in process of writing a script to train the model. I believe the blog post wouldn’t be complete without a detailed explanation of the model training.
Once these two are complete, I will have to write the blog post which should take another day.
So in total I am hoping to release the blog post by the end of this week which should (all in code+theory) explain:
GPT-2 model architecture
Attention
Multi head attention
Text Dataset Creation
Training
Loss function
My aim is to write a blog post that is complete and is able to provide a complete explanation of everything that goes inside a GPT-2 model.
The training part should also automatically cover finetuning. Because, once we load the pretrained weights, any training on top is essentially fine-tuning the model.
I am very excited and very close to finishing after struggling for more than 4 weeks.