Could someone kindly help me understand what the ‘nb’ parameter is that appears in three of the functions in sdgd.py?
To me it seems it is somehow related to iterations over the batches, but I’m getting lost in the code and can’t quite figure out where it originates from.
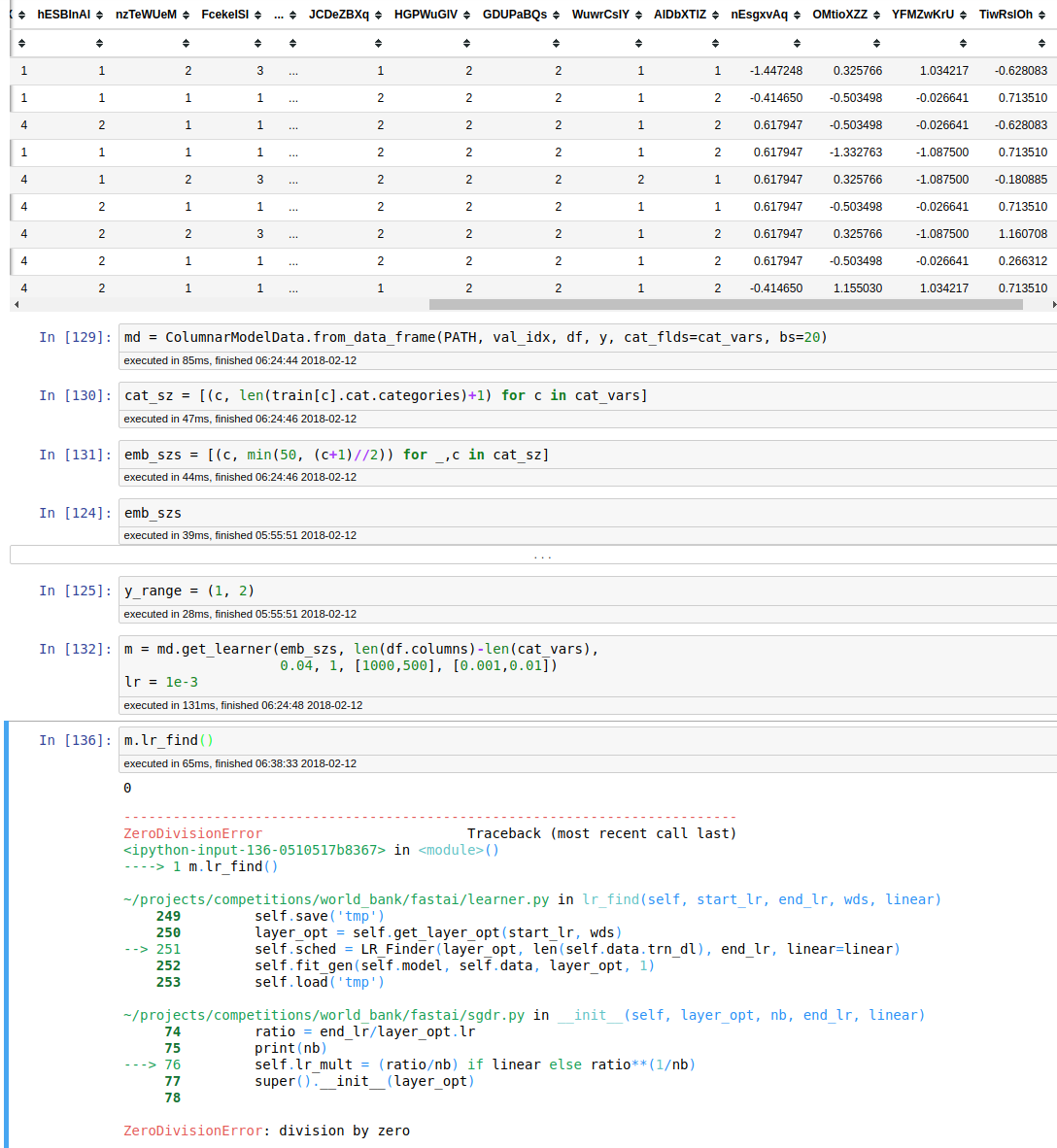
I’m trying to run the Rossmann lesson code on a different dataset with largely categorical variables with entity embeddings and a few continuous variables. There the ‘nb’ gets the value of 0 and causes an error since it’s used in dividing the ratio in LR_Finder.
At first I suspected this might have something to do with the datatype of the dependent variable, but changes in datatype in it made no difference.
nb ends up being set to len(m.data.trn_dl) which is the size of your training set. your training set probably doesn’t have any data.
be careful, this notebook is not meant to be run in order.
look for two cells
df = train[columns]
and
df = test[columns]
you are meant to run only run one (train), run the rest of the cells in the notebook until the variable joined is set with the contents of df. then run it again with df set to the test data, skip the joined = command. and run joined_test which will add the contents of df to joined_test.
That was really helpful. I managed to track down the issue thanks to your advice.
I had fumbled in reproducing the notebook in selecting the indexes for the validation set. This caused all my data to go into the validation set leaving the training set empty.