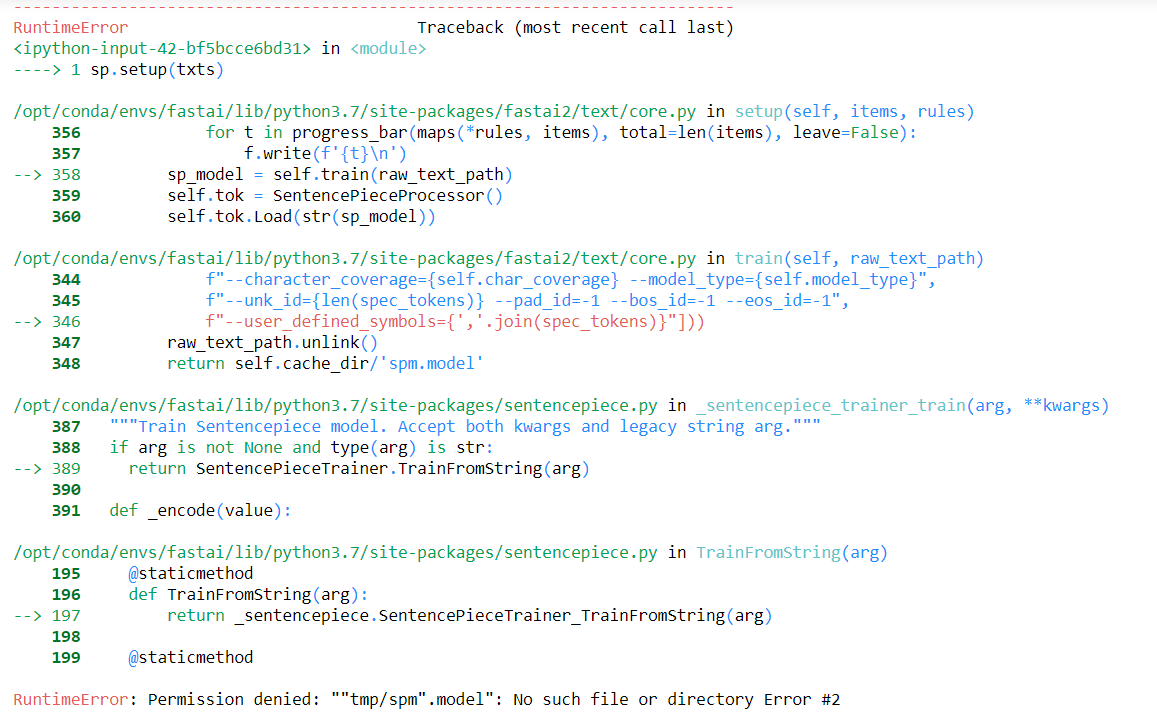
I must explain my jump ahead and I know you are all very busy, and my bug maybe the result of my impatience but I was hoping to use some of this on the covid -19 Kaggle challenge.
This relates to not setting a directory somewhere
I have installed both fastcore and fastai2 with -e ".[dev]" this morning since I found the fault but still persists.
/home/dl/fastai-2020/fastai2/fastai2/text/core.py(354)train()
352 f"–character_coverage={self.char_coverage} --model_type={self.model_type}",
353 f"–unk_id={len(spec_tokens)} --pad_id=-1 --bos_id=-1 --eos_id=-1",
–> 354 f"–user_defined_symbols={’,’.join(spec_tokens)}"]))
355 raw_text_path.unlink()
356 return self.cache_dir/‘spm.model’
ipdb> a
self = <fastai2.text.core.SentencePieceTokenizer object at 0x7f20061ac210>
raw_text_path = Path(‘tmp/texts.out’)
ipdb> ll
344 def train(self, raw_text_path):
345 “Train a sentencepiece tokenizer on texts and save it in path/tmp_dir"
346 from sentencepiece import SentencePieceTrainer
347 vocab_sz = self._get_vocab_sz(raw_text_path) if self.vocab_sz is None else self.vocab_sz
348 spec_tokens = [’\u2581’+s for s in self.special_toks]
349 q = '”’
350 SentencePieceTrainer.Train(" “.join([
351 f”–input={q}{raw_text_path}{q} --vocab_size={vocab_sz} --model_prefix={q}{self.cache_dir/‘spm’}{q}",
352 f"–character_coverage={self.char_coverage} --model_type={self.model_type}",
353 f"–unk_id={len(spec_tokens)} --pad_id=-1 --bos_id=-1 --eos_id=-1",
–> 354 f"–user_defined_symbols={’,’.join(spec_tokens)}"]))
355 raw_text_path.unlink()
356 return self.cache_dir/‘spm.model’
357
ipdb> c
OSError Traceback (most recent call last)
in
1 get_ipython().run_line_magic(‘debug’, ‘’)
----> 2 subword(1000)
in subword(sz)
1 def subword(sz):
2 sp = SubwordTokenizer(vocab_sz=sz)
----> 3 sp.setup(txts)
4 return ’ '.join(first(sp([txt]))[:40])
~/fastai-2020/fastai2/fastai2/text/core.py in setup(self, items, rules)
364 for t in progress_bar(maps(*rules, items), total=len(items), leave=False):
365 f.write(f’{t}\n’)
–> 366 sp_model = self.train(raw_text_path)
367 self.tok = SentencePieceProcessor()
368 self.tok.Load(str(sp_model))
~/fastai-2020/fastai2/fastai2/text/core.py in train(self, raw_text_path)
352 f"–character_coverage={self.char_coverage} --model_type={self.model_type}",
353 f"–unk_id={len(spec_tokens)} --pad_id=-1 --bos_id=-1 --eos_id=-1",
–> 354 f"–user_defined_symbols={’,’.join(spec_tokens)}"]))
355 raw_text_path.unlink()
356 return self.cache_dir/‘spm.model’
OSError: Not found: ““tmp/texts.out””: No such file or directory Error #2
And occurs after or during this call.
sentencepiece_trainer.cc(116) LOG(INFO) Running command: --input=“tmp/texts.out” --vocab_size=1000 --model_prefix=“tmp/spm” --character_coverage=0.99999 --model_type=unigram --unk_id=9 --pad_id=-1 --bos_id=-1 --eos_id=-1 --user_defined_symbols=▁xxunk,▁xxpad,▁xxbos,▁xxeos,▁xxfld,▁xxrep,▁xxwrep,▁xxup,▁xxmaj
sentencepiece_trainer.cc(49) LOG(INFO) Starts training with :
TrainerSpec {
input: “tmp/texts.out”
input_format:
model_prefix: “tmp/spm”
model_type: UNIGRAM
vocab_size: 1000
self_test_sample_size: 0
character_coverage: 0.99999
input_sentence_size: 0
shuffle_input_sentence: 1
seed_sentencepiece_size: 1000000
shrinking_factor: 0.75
max_sentence_length: 4192
num_threads: 16
num_sub_iterations: 2
max_sentencepiece_length: 16
split_by_unicode_script: 1
split_by_number: 1
split_by_whitespace: 1
treat_whitespace_as_suffix: 0
user_defined_symbols: ▁xxunk
user_defined_symbols: ▁xxpad
user_defined_symbols: ▁xxbos
user_defined_symbols: ▁xxeos
user_defined_symbols: ▁xxfld
user_defined_symbols: ▁xxrep
user_defined_symbols: ▁xxwrep
user_defined_symbols: ▁xxup
user_defined_symbols: ▁xxmaj
hard_vocab_limit: 1
use_all_vocab: 0
unk_id: 9
bos_id: -1
eos_id: -1
pad_id: -1
unk_piece:
bos_piece:
eos_piece:
pad_piece:
unk_surface: ⁇
}
NormalizerSpec {
name: nmt_nfkc
add_dummy_prefix: 1
remove_extra_whitespaces: 1
escape_whitespaces: 1
normalization_rule_tsv:
}trainer_interface.cc(267) LOG(INFO) Loading corpus: “tmp/texts.out”
thanks