YJP posted a fix to this issue yesterday. go to your fast.ai folder and do “git pull” from the terminal
You may run into a merge conflict with some notebook files that have also been updated. This will cancel out the pull.
If this happens you may want to commit your changes locally and then merge. If you are not that familiar with GIT the most pain free way of keeping up with code changes is to make a duplicate of any notebooks you are working on so that you dont have to deal with merge issues.
First of all, I am truly sorry about the error as this stems from the pull request I previously made.
To fix this, since Jeremy updated fastai library so you will have to update it again.
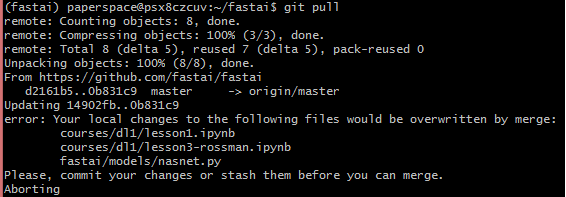
To update it, as davecazz suggested, under ~/fastai directory, you can do the following command:
git pull
If you have any conflict message as follow:
then you can commit it locally by following the instruction below and do “git pull” again:
This is based on the seedling data. unfreezing the layers leads to a substantial loss of accuracy and I saw the post earlier where not unfreezing may be beneficial on data that is similar to imagenet. However for the seedling challenge are there any thoughts why the numbers are skewed the other way?
Hi, I don’t have that problem with nasnet on seedlings. It runs fine. Perhaps some other hyper parameter is causing it, though the ones I used were very similar to those on other architectures. I notice you and I have the same leaderboard score- I wasn’t able to get nasnet to improve my score.
Nice one on the leader board not bad for our first Kaggle competitions but my score there is using resnet and Im trying to improve it by using nasnet. I have continued the training with nasnet without unfreezing to see how far it will go without over fitting.
Is your score with nasnet?
No, it was a touch lower and much longer to learn. And when ensembled with nasnet it didn’t improve. Some black grass and silky-bent images seem to be too similar for them to be distinguished except by chance on any one model build. Time to move on, for this deep learner.
RuntimeError: Error(s) in loading state_dict for NASNetAMobile:
size mismatch for last_linear.weight: copying a param with shape torch.Size([1000, 1056]) from checkpoint, the shape in current model is torch.Size([3, 1056]).
size mismatch for last_linear.bias: copying a param with shape torch.Size([1000]) from checkpoint, the shape in current model is torch.Size([3]).
 not bad for our first Kaggle competitions but my score there is using resnet and Im trying to improve it by using nasnet. I have continued the training with nasnet without unfreezing to see how far it will go without over fitting.
not bad for our first Kaggle competitions but my score there is using resnet and Im trying to improve it by using nasnet. I have continued the training with nasnet without unfreezing to see how far it will go without over fitting.