Hello @farlion,
I will try to reproduce your notebook later and we will see how it goes. Thank you for the information.
Cheers,
YJ
Hello @farlion,
I will try to reproduce your notebook later and we will see how it goes. Thank you for the information.
Cheers,
YJ
Hey @farlion
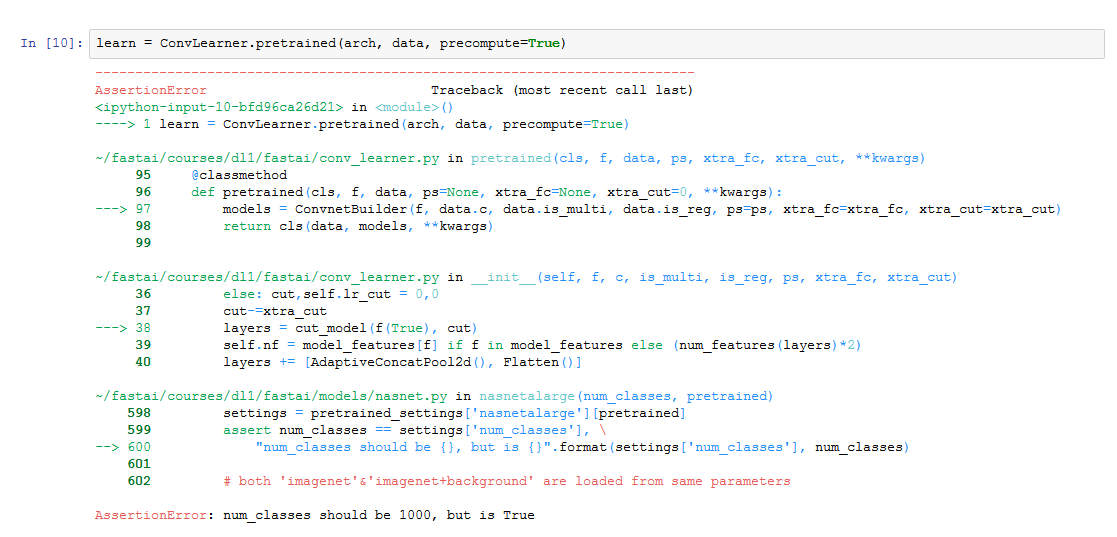
I was able to get the same error as you using your code. Not sure if this is what you want but this code worked.
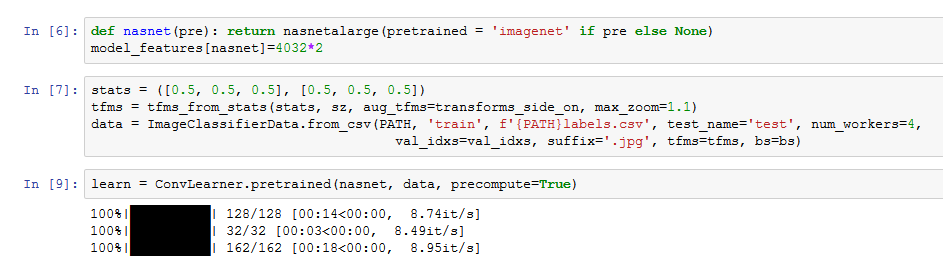
def nasnet(pre): return nasnetalarge(pretrained = 'imagenet' if pre else None)
model_features[nasnet]=4032*2arch = nasnetalarge
batch_size = 64
img_size = 80
stats = ([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
transforms = tfms_from_stats(stats, img_size, aug_tfms=transforms_side_on, max_zoom=1.1)
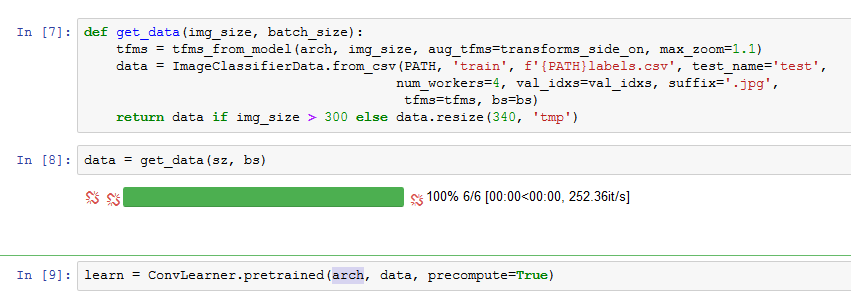
data = ImageClassifierData.from_csv(PATH, 'train', f'{PATH}labels.csv', test_name='test', val_idxs=validation_set_idxs, tfms=transforms, bs=batch_size)def get_data(img_size, batch_size):
transforms = tfms_from_stats(stats, img_size, aug_tfms=transforms_side_on, max_zoom=1.1)
data = ImageClassifierData.from_csv(PATH, 'train', f'{PATH}labels.csv', test_name='test',
num_workers=4, val_idxs=validation_set_idxs,
tfms=transforms, bs=batch_size)
return data if img_size > 300 else data.resize(340, 'tmp')
data = get_data(img_size, batch_size)learn = ConvLearner.pretrained(nasnet, data)I was able to reproduce the error you are getting below:
The difference between your version and nasnet notebook by Jeremy (i.e. nasnet.ipynb) is mainly as follow:
Your version
nasnet.ipynb
It seems that
It may be good to have a look at nasnet.ipynb and replicate the steps taken there to see whether things are working. Good luck!
@YJP @amritv Thank you so much for the detailed steps, I wasn’t even aware there is a nasnet.ipynb notebook! Will take a look and adapt accordingly.
Thanks for your help, you two are rockstars!
Best,
Florian
Update: Aaaaaaaaand it’s traaaaaining! (:
@farlion it’s a good feeling when it trains ain’t it. Lol
@amritv, @farlion
Have you tried nasnet on the Dog Breed data? Has it worked OK for you?
I am getting an overfitting issue quite quickly with dropout 0.5 (or underfitting with more dropout rates but not improving its log loss) and it simply cannot get to a log loss figure anywhere near 0.20 that we can get from other models. Any advice would be truly appreciated. Thank you.
@YJP absolute same here!
My validation loss with nasnet seems to flatten out around a very high 0.75.
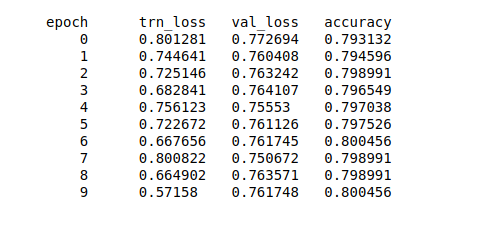
I’ve tried data augmentation, higher dropout, unfreezing, lower learning rates, cycle_mult, larger and smaller images…nothing quite seems to help.
I have not tried it on the dog breed data but did on the plant seedling data. I too was getting overfitting fairly quickly with lower accuracy compared to other models.
Thank you both for the information. Will try further and let you know if there is any improvement.
Hi all, wonderful resources here, thanks! Just 2 weeks into DL, and python, and 3.5 lessons into fastai. It’s been a fun learning experience.
For NASNet and Dog Breed the significant change I made was changing dropout from 1/2 to 2/3, I think that made the difference, managing < 0.152 loss on kaggle and 0.959 accuracy without even unfreezing layers. 0.142 when ensembled. Happy to stop there. Now onto Plant Seedlings.
That’s awesome, can you give me a guide on how long it took to train? That was another issue for me, the training was sloooooow!
Hallo,
Thank you for your helpful post. I tried with the dropout rate you suggested.
I realised the main difference between my notebook and Jeremy’s nasnet.ipynb was an allocation of a validation set. It looks like nasnet.ipynb did not allocate any validation set and the default is
val_idxs=None
So I tried nasnet on dog breed images with no validation set (I think the default is one when there is no specific val_idxs) and the accuracy went up to 95.6% with a training log loss around 0.16.
Hello,
You are correct and apologies for the incorrect comment about the default in dataset.py. Thank you for looking into this.
Looking at ‘from_csv’ below from dataset.py, it does pull through 20% if it has not been specified. So the default will be 20% of the images, not 1 image.
def from_csv(cls, path, folder, csv_fname, bs=64, tfms=(None,None),
val_idxs=None, suffix='', test_name=None, continuous=False, skip_header=True, num_workers=8):
""" Read in images and their labels given as a CSV file.
This method should be used when training image labels are given in an CSV file as opposed to
sub-directories with label names.
Arguments:
path: a root path of the data (used for storing trained models, precomputed values, etc)
folder: a name of the folder in which training images are contained.
csv_fname: a name of the CSV file which contains target labels.
bs: batch size
tfms: transformations (for data augmentations). e.g. output of `tfms_from_model`
val_idxs: index of images to be used for validation. e.g. output of `get_cv_idxs`.
If None, default arguments to get_cv_idxs are used.
suffix: suffix to add to image names in CSV file (sometimes CSV only contains the file name without file
extension e.g. '.jpg' - in which case, you can set suffix as '.jpg')
test_name: a name of the folder which contains test images.
continuous: TODO
skip_header: skip the first row of the CSV file.
num_workers: number of workers
Returns:
ImageClassifierData
"""
fnames,y,classes = csv_source(folder, csv_fname, skip_header, suffix, continuous=continuous)
**val_idxs = get_cv_idxs(len(fnames)) if val_idxs is None else val_idxs**
((val_fnames,trn_fnames),(val_y,trn_y)) = split_by_idx(val_idxs, np.array(fnames), y)
test_fnames = read_dir(path, test_name) if test_name else None
if continuous:
f = FilesIndexArrayRegressionDataset
else:
f = FilesIndexArrayDataset if len(trn_y.shape)==1 else FilesNhotArrayDataset
datasets = cls.get_ds(f, (trn_fnames,trn_y), (val_fnames,val_y), tfms,
path=path, test=test_fnames)
return cls(path, datasets, bs, num_workers, classes=classes)
In my case, I found a log loss figure improved in Kaggle when I trained on a whole data set -1 (val_idxs = [0]).
About unfreezing for the Dog Breed classification data, apparently it is best to use the pre-trained model for this particular case:
Thanks for the PR to nasnet.py! I’ve merged that now. If there are any improvements suggested to the notebook, I’ll happily take PRs there too 
Hi all,
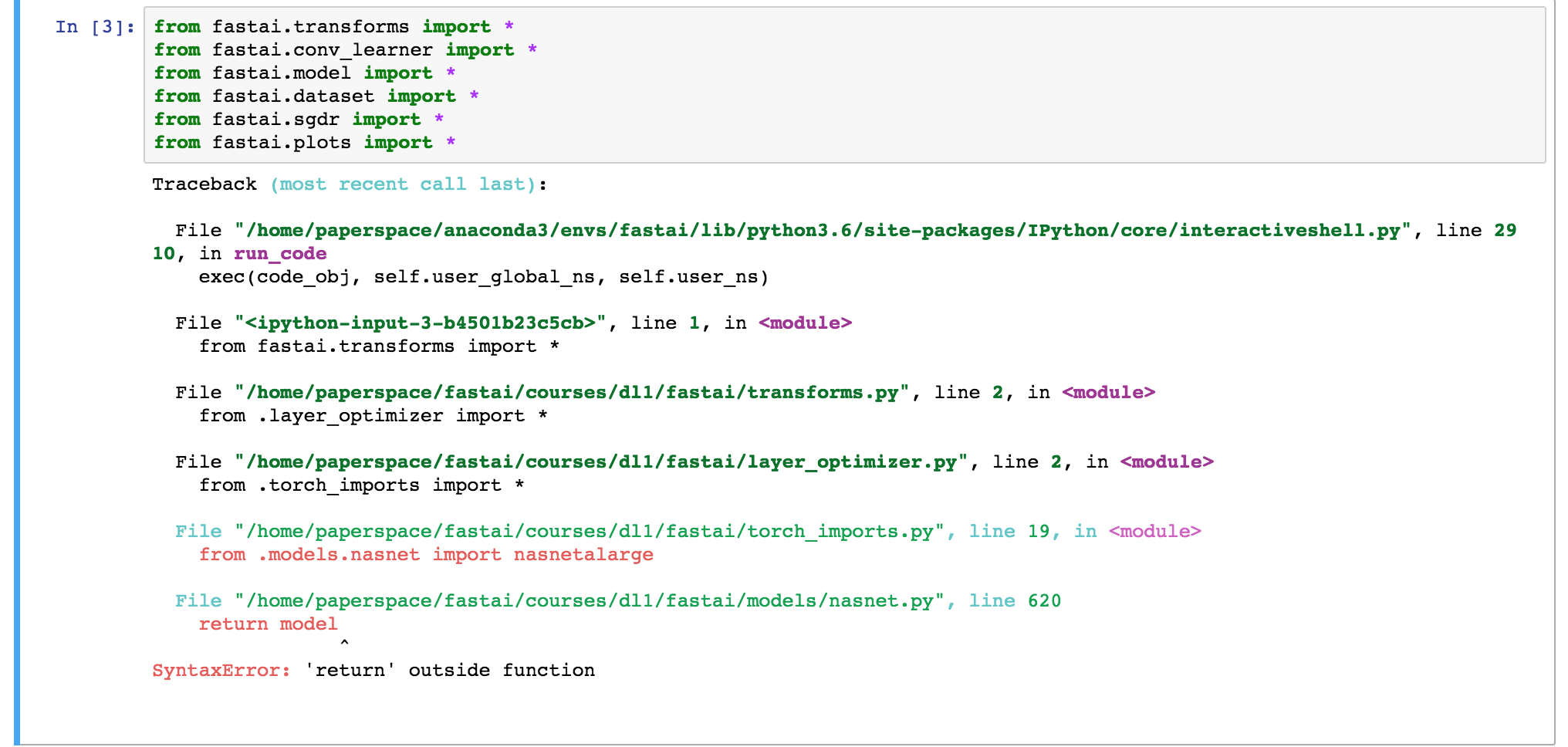
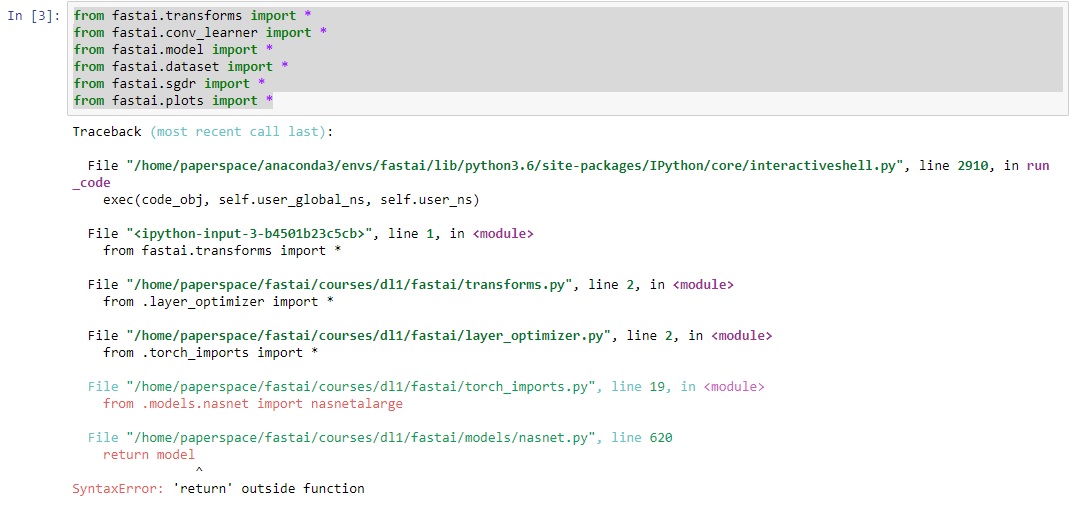
I just spun up my instance on Paperspace for lesson 1 and I’m getting an import error when running the imports in lesson1.ipynb. The error message gives a “Syntax error: “Return” outside of function” and it traces it back to line 620 in nasnet.py. My guess is that it was broken by the recent merge but I’m not sure. I’m attaching the error below.
Hi Jeremy, ‘return model’ was outside of def nasnetalarge. Sorry but could you please change this. Thank you in advance.
Hi all, I just started coding up lesson 1 on AWS and when I was importing the fastai libraries, it gave the same error ‘return outside function’.
Please let me know if you figure out a way to fix this.
Yes. That is the same error I get. Thanks for following up @teidenzero
@sumo I wish I could help but I’m getting the same error together with @lukeharries. I haven’t found trace of the issue anywhere else and it looks like it’s a consequence of some recent change so hopefully it will be addressed soon