I’m building a food classifier model based on Food 101 dataset using ‘resnet26d’ architecture and running on Colab GPU.
foods = DataBlock(
blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
get_y=labeller,
item_tfms=Resize(256, method='squish'),
batch_tfms = aug_transforms(size=128, min_scale=0.75))
dls = foods.dataloaders(food101)
learn = vision_learner(dls, 'resnet26d', metrics=error_rate).to_fp16()
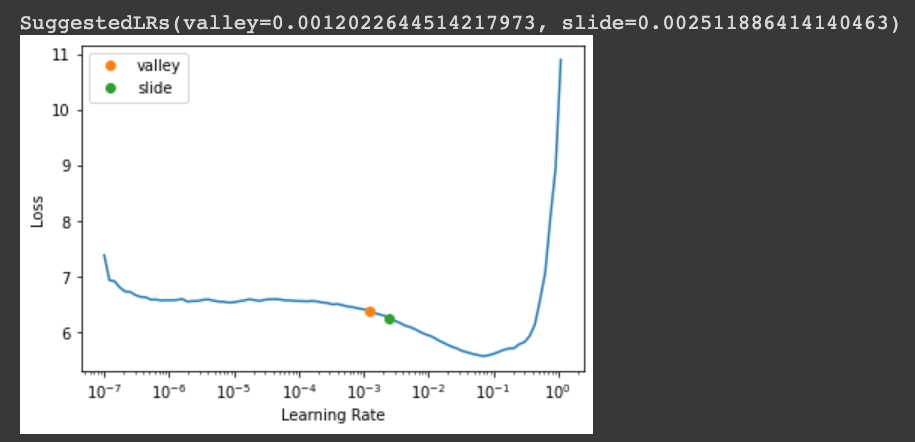
The learning rate recommended by lr_find:
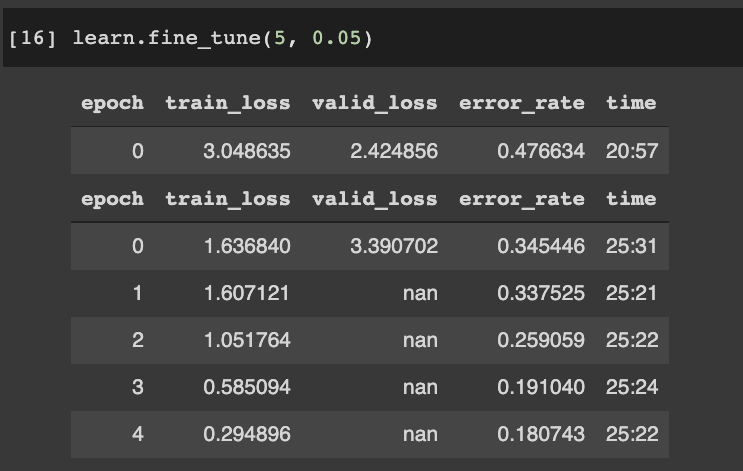
I tried fine-tuning the model with LR of 0.05 and noticed that valid_loss was NaN after 1 epoch.
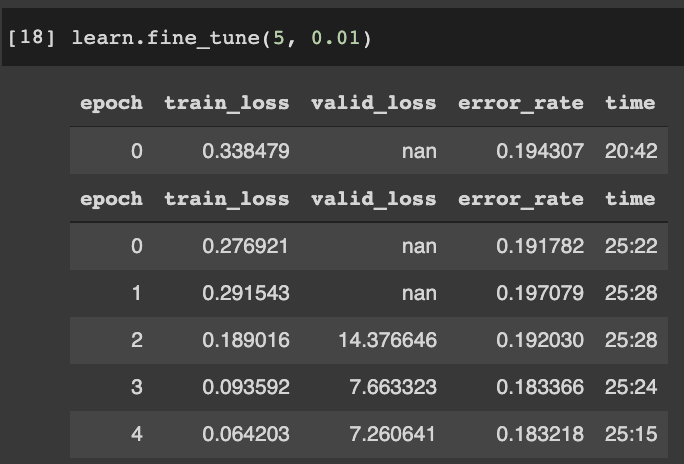
I then tried reducing LR to 0.01, valid_loss was NaN for a few epochs, then appear again in the last few epochs:
My questions are:
- Is this NaN valid_loss a problem? Since error_rate and training_loss is still improving after each epoch?
- Why is valid_loss NaN? Is this because of too low or too high LR?
- Some other threads related to NaN valid loss on the forum mentions out of CUDA memory on the GPU? How do I check if that issue applies here / in my model?
Looking for some pointers and appreciate any thoughts /advice!