
An antique 18th century painting of a gorilla eating a plate of chips.
You can also read this post at my blog.
I recently began fastai Course Part 2: a course where one dives into the deeper workings of deep learning by fully implementing stable diffusion.
In the first lesson, we play around with diffusers using the Hugging Face Diffusers library. Below are things I have noticed; my musings.
Steps
Diffusion is simply a process whereby noise is progressively removed from a noisy image. A single step can be thought of a single portion of noise being removed.

A depiction of a ring comprised of interwined serpents, topped with a single jewel of emerald.
Below is the evolution of the image above in 48 steps. Each new image has less and less noise (what the diffuser thinks is noise).

The compressed GIF has its own artefacts…

It still managed to generate a pretty good image despite the misspelling of “intertwined”!
When It Doesn’t Work Well
I’ve found that a diffuser doesn’t work well when one prompts it for things, which I assume, it hasn’t “seen” or hasn’t been trained on before. It sounds obvious, but it’s really interesting when you see the result of it.

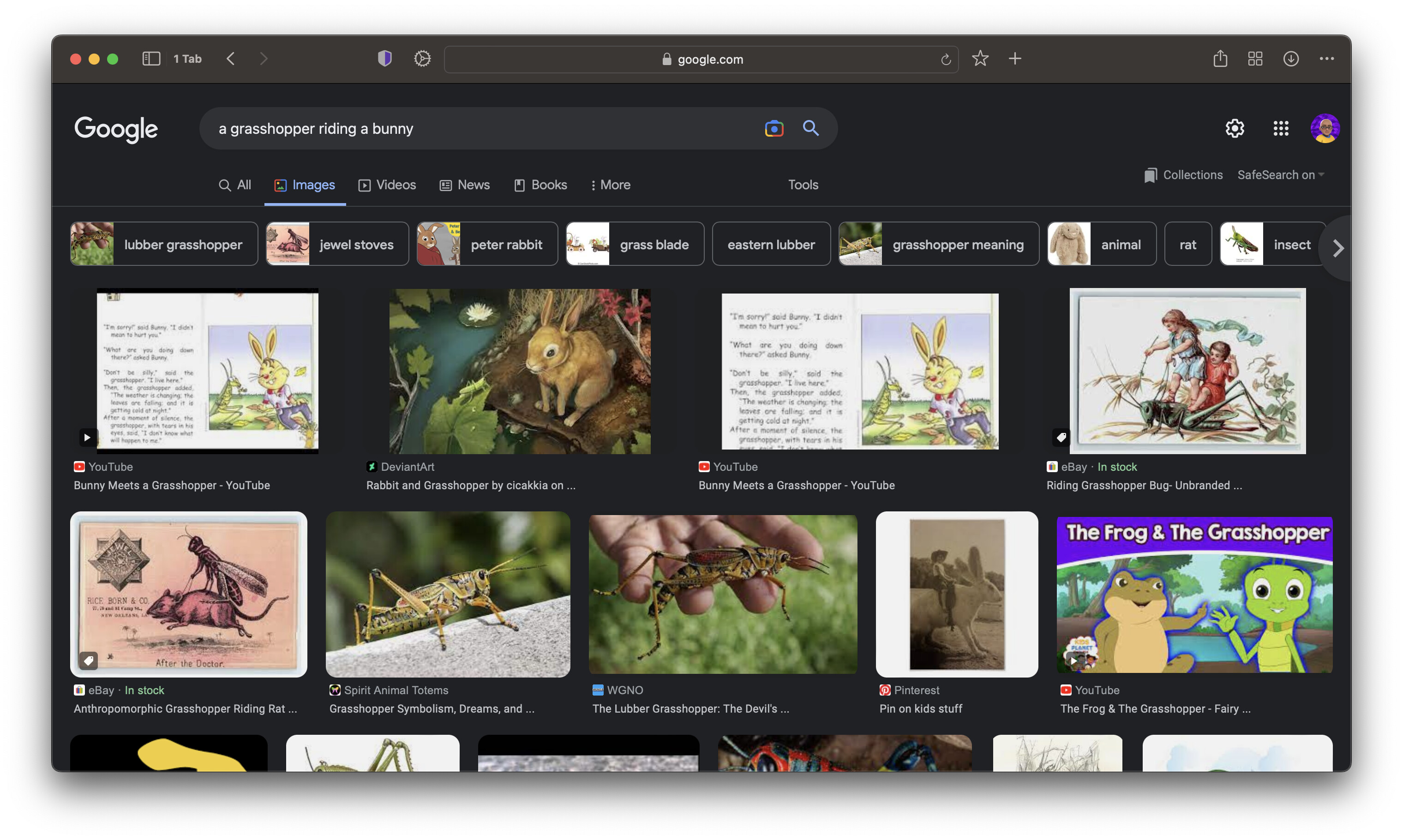
A grasshopper riding a bunny.

A grasshopper riding a bunny.
A quick Google search also doesn’t return any images matching the prompt in the top results.
CFG (Classifier Free Guidance)
Or simply known as guidance, CFG is a value which tells the diffuser how much it should stick to the prompt.
A lower guidance leads to more varied and random images that are loosely related to the prompt. A higher guidance produces more relevant images.
I’ve found that too high of a guidenace leads to images having too much contrast.

An antique 18th century painting of a gorilla eating a plate of chips.
The image above shows rows with increasing levels of guidance (1, 2.5, 5, 7.5, 10, 25, 50). 7.5 is the sweetspot.
Negative Prompts
The best way to think about negative prompts is that a negative prompt guides a diffuser away from generating a certain entity.
Take the image below as an example.

An antique 18th century painting of a gorilla eating a plate of chips.
I generated the image again using the exact same seed and prompt, but also used the following negative prompt, “yellow circle”.

Prompt: An antique 18th century painting of a gorilla eating a plate of chips. | Negative Prompt: yellow circle
Image to Image
Instead of starting from noise, one can make a diffuser begin from an existing image. The diffuser follows the image as guide and doesn’t match it 1 to 1.
I quickly mocked up the following image.

I input it to a diffuser with a prompt, and it output the following.

A bench under a tree in a park
I then further generated another image from this one.

A low poly 3D render of a bench under a tree in a park
Further Adapting a Diffuser
There are two ways one can further customize a diffuser to produce desired images: textual inversion and dreambooth.
Textual Inversion
A diffuser contains a text encoder. This encoder is responsible for parsing the prompt and giving it a mathematical representation.
A text encoder can only parse according to its vocabulary. If it encounters words not in its vocabulary, the diffuser will be unable to produce an image relevant to the prompt.
In a nutshell, textual inversion adds new words to the vocabulary of the text encoder so it can parse prompts with those new words.
I managed to generate the image below by adding the word “Mr Doodle” to the vocabulary of the diffuser’s text encoder.

An antique 18th century painting of a gorilla eating a plate of chips in the style of Mr Doodle
Dreambooth
Dreambooth is more akin to traditional fine-tuning methods. A diffuser is further trained on images one supplies to it.
So End my Musings
If you have any comments, questions, suggestions, feedback, criticisms, or corrections, please do let me know!