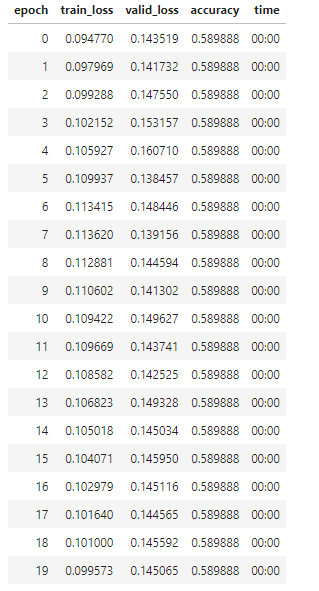
Hi everyone, in the beginning of my journey of learning deep learning, I decided to tackle the Titanic project on Kaggle, as it seemed doable. I don’t know what exactly is going on, but after creating the learn object the accuracy of the model neither increases nor decrease, no matter how many times I run it.
I thought it might be due to the fact that there isn’t a lot of data and the pattern would be learned the first run. But the accuracy changes whenever I create a new dls object.
I don’t know if I’m missing something obvious here.
Here are the important parts of the code:
train_df = train_df[[‘Survived’, ‘Pclass’, ‘Sex’, ‘Age’, ‘SibSp’, ‘Parch’, ‘Fare’, ‘Embarked’]]
cat_names = [‘Pclass’, ‘Sex’, ‘Parch’, ‘Embarked’]
cont_names = [‘Age’, ‘SibSp’, ‘Fare’]
procs = [Categorify, FillMissing, Normalize]
splits = RandomSplitter(valid_pct=0.2)(range_of(train_df))
dls = TabularDataLoaders.from_df(train_df, procs=procs,
cat_names = cat_names,
cont_names = cont_names,
y_names=‘Survived’,
splitter = splits,
bs=64
)
dls.show_batch()
learn = tabular_learner(dls, metrics=accuracy)
learn.fit_one_cycle(3)