I tried training a model to identify mushroom species but the error rate stayed stagnant throughout my epochs! Maybe this is a very hard problem for which only a bigger model would work? This sounds wrong to me so please help explain
If your model’s error rate remains stagnant throughout training, it might not necessarily mean that a bigger model is the solution. Here are some key factors to consider:
- Data Quality and Quantity: Ensure your dataset is large and diverse enough, and accurately labeled. For mushroom species, variations can be subtle, so high-quality, varied data is crucial.
- Model Architecture: While a bigger model might capture more complexity, it’s also important to choose the right architecture for your task. Sometimes a simpler, well-tuned model performs better than a larger, more complex one.
- Feature Engineering: In tasks like species identification, the right features are vital. Check if you can extract more meaningful features from your data.
- Overfitting and Underfitting: If your model is too complex (overfitting) or too simple (underfitting) for your data, it won’t perform well. Validate your model’s complexity against your data.
Remember, machine learning problems are often not just about model size but about finding the right combination of data, model architecture, preprocessing, and tuning.
2 Likes
Thank you for the advises! Makes somewhat sense.
Suffering the same problem trying to solve the other problem - to identify interior design styles using images. Question about point 3 - “Feature Engineering” - sorry if this were a dumb question - could you please more specific about that?
- Do you mean a feature extraction as a pre-step and run the model against the extracted feature image, or a simple data argumentation could do?
- Or is it rather try all possible solution and see which fits? If this is the case, what could be all tactical approaches here?
Many thanks in advance!
2 Likes
My tactical approach is this:
Experimenting with different learning rates, batch sizes, number of layers, or other hyperparameters can significantly impact model performance.
Adjusting the learning rate during training (e.g., reducing it when the error rate plateaus) can help overcome learning stalls.
If the model is overfitting, applying regularization techniques (like L1 or L2 regularization) can help.
Systematically diagnose where the current approach might be falling short and address that specific issue. It’s also a good practice to establish a strong baseline model and iteratively make changes, tracking which modifications lead to tangible improvements.
2 Likes
Great response, could you expand on 3 a little? How would one go about extracting more meaningful features from the data?
I think this is easiest to understand in the context of tabular data and a tabular model. Let’s say you want to predict sales for a movie theater and you have a table with just 2 columns of past sales data, the date and the sales in dollars. Intuitively one feature that would probably help the model with this prediction is whether a particular date is a weekend or not. Trying to get the model to figure out if a particular date was a weekend or not is a fairly challenging exercise, particularly because the days of the week corresponding to a particular date shift from year to year. So instead of trying to get the model to figure out this complex set of logic you could add a 3rd column to your table with the day of the week - Monday through Sunday, which would enable the model to use that additional data in its prediction without having to try and learn how to tell what day of the week a particular date was.
To learn more check out the tabular learning sections of the course/book: https://youtu.be/hBBOjCiFcuo?si=VSvZiHMqlAmzt5Iy&t=3877
1 Like
I did some feature extraction of my mushroom images like this:
features=[‘gills’, ‘stalk’, ‘young’, ‘dried’]
if not path.exists():
path.mkdir()
for o in mushroom_types:
dest = (path/o)
dest.mkdir(exist_ok=True)
for f in features:
results = search_images_bing_many(key, f’{o} {f} mushroom’,150)
download_images(dest, urls=results)
All the above actually made my error rate worse. Maybe coz comparing mushroom based on gills rather than the whole photo is much harder. I suspect feature engineering only applies to tabular data not images.
Something else that helped me a ton was adding weights to the loss function like this. Made my whole error go down a LOT. So it’s weird the algorithm couldn’t figure it out on it’s own O.O
learn.loss_func.func = nn.CrossEntropyLoss(weight=tensor([2.5.,1.]))
I don’t think you’re on the right track for what feature extraction or feature engineering is. It would probably be helpful to share your code either on the forum or share a the notebook on Colab/Kaggle/Github or something like that.
** How would you do feature extraction with images then? Below is my code **
!pip install -Uqq fastai
from fastai.vision.all import *
from fastai.text.all import *
from fastai.collab import *
from fastai.tabular.all import *
from fastai.imports import *
import fastbook
fastbook.setup_book()
from fastdownload import download_url
from fastbook import *
from fastai.vision.widgets import *
import os
!pip install azure-cognitiveservices-search-imagesearch
key = os.environ.get('AZURE_SEARCH_KEY', 'xxx')
!rm -rf /kaggle/working/*
from itertools import chain
from azure.cognitiveservices.search.imagesearch import ImageSearchClient as api
from msrest.authentication import CognitiveServicesCredentials as auth
def search_images_bing_many(key, term, total_count=150, min_sz=224):
"""Search for images using the Bing API
:param key: Your Bing API key
:type key: str
:param term: The search term to search for
:type term: str
:param total_count: The total number of images you want to return (default is 150)
:type total_count: int
:param min_sz: the minimum height and width of the images to search for (default is 128)
:type min_sz: int
:returns: An L-collection of ImageObject
:rtype: L
"""
headers = {"Ocp-Apim-Subscription-Key":key}
search_url = "https://api.bing.microsoft.com/v7.0/images/search"
max_count = 150
imgs = []
for offset in range(0, total_count, max_count):
if ((total_count - offset) > max_count):
count = max_count
else:
count = total_count - offset
params = {'q':term, 'count':count, 'min_height':min_sz, 'min_width':min_sz, 'offset': offset}
response = requests.get(search_url, headers=headers, params=params)
search_results = response.json()
imgs.append(L(search_results['value']))
return L(chain(*imgs)).attrgot('contentUrl').unique()
mushroom_types = 'bolete photo','photo wild -bolete'
path = Path('mushrooms')
if not path.exists():
path.mkdir()
for o in mushroom_types:
dest = (path/o)
dest.mkdir(exist_ok=True)
results = search_images_bing_many(key, f’{o} mushroom’,200)
download_images(dest, urls=results)
fns = get_image_files(Path(path))
fns
fns2 = get_image_files(Path(path/o))
len(fns2)
failed = verify_images(fns)
failed
failed.map(Path.unlink);
mushrooms = DataBlock(
blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(valid_pct=0.2, seed=42),
get_y=parent_label,
item_tfms=Resize(256),
# batch size and image size, start small then get bigger
batch_tfms=aug_transforms())
dls = mushrooms.dataloaders(path, bs=128)
learn = vision_learner(dls, resnet18, metrics=error_rate)
lrs = learn.lr_find()
dls.train.show_batch(max_n=8, nrows=2)
for image in os.listdir(path/o):
ext = os.path.splitext(image)[1]
if ext in ['.png', '.gif']:
new_filename = os.path.splitext(image)[0]+'.png'
img = Image.open(path/o/image)
img.convert('RGBA')
img.save(new_filename)
print('saving: ' + new_filename)
learn.loss_func.func = nn.CrossEntropyLoss(weight=tensor(2.2,1))
def get_dls(bs, size):
dblock = DataBlock(blocks = (ImageBlock, CategoryBlock),
get_items = get_image_files,
get_y = parent_label,
splitter = RandomSplitter(valid_pct=0.2, seed=42),
item_tfms = Resize(size),
batch_tfms=aug_transforms()
)
return dblock.dataloaders(path, bs = bs)
learn.dls=get_dls(64,128)
learn.fine_tune(10, lrs.valley, wd=1e-6)When you paste code into the forums it’s very helpful to surround it with backticks which will format it as code. When inserting a large code block using triple backticks allows it to cover multiple lines. It’s very difficult to try and read the code as you’ve shared it because most of the indentation is lost.
Here is an example:
Ex:
``` <-- starting code fence
code goes here
``` <-- ending code fence
Have you reviewed all of your images? Do the labels make sense with respect to the images? Are there mis-labeled images or images that don’t belong? It is pretty common for images you get from the web to contain things that you might not want or expect, for example maybe it retrieved a photo of a can of wild mushroom soup instead of photos of actual mushrooms. I suggest reviewing this lecture about data cleaning.

When you look at the images can you tell the difference? If not how do you know that what the search engine returned was correct.
Thanks for the response @matdmiller. Yes my images generally make sense (a few were mislabeled, but I always run the image classification cleaner to fix that). I also can tell the difference between mushroom species myself. The only thing that made this work so far (get my error to decrease between epochs and go down a lot, was to add the weight tensor like this.
weight the losses
learn.loss_func.func = nn.CrossEntropyLoss(weight=tensor(2.,1.))
no weights (error rate is stagnant and increases quickly):
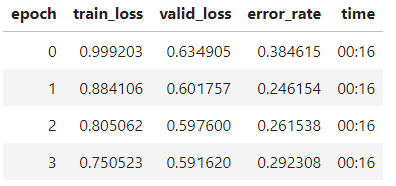
with weighting the loss function in the above manor (error rate decreases rapidly through epochs):
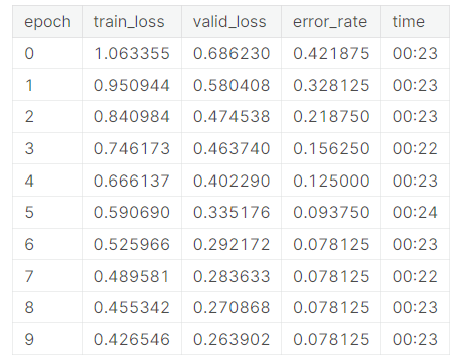
I don’t know why this works, but before I weighted the loss function it was an extremely biased model always favoring predicting one class in almost all situations.
1 Like
Are the number of images of each type roughly balanced or do you have a lot more of 1 type than the other? Typically weighting is used when you have a lot more of 1 type of an image than another. Another possibility is that even if the number of images are roughly equal maybe one of your classes has a lot of duplicate (or nearly duplicate) images. Looking more into your data is probably a good place to start.
Also you may want to try out different hyperparameters and models.
Some ideas:
What learning rates are you actually using? It’s possible that LR finder is suggesting a LR that is too small. It is possible this is the reason for your learning rate not going down, you may be getting stuck in a local minima. From memory 2e-3 heuristially is a good place to start (you can also use the fast.ai defaults as a starting point. This model trains fast so it doesn’t hurt to experiment with different LR’s.
You might want to try a smaller batch size like 32. 128 is bit on the larger side of things.
You would probably benefit from a larger or more modern and capable model. ResNet 18 is an old and very small model. I generally don’t use anything smaller than ResNet34.
Jeremy created this great notebook comparing different image models which would be a good place to start trying out other options:
Your error rate is not increasing and both your training and validation loss are still decreasing so it’s likely you are under training the model - i.e. train for longer or with a higher learning rate.
2 Likes