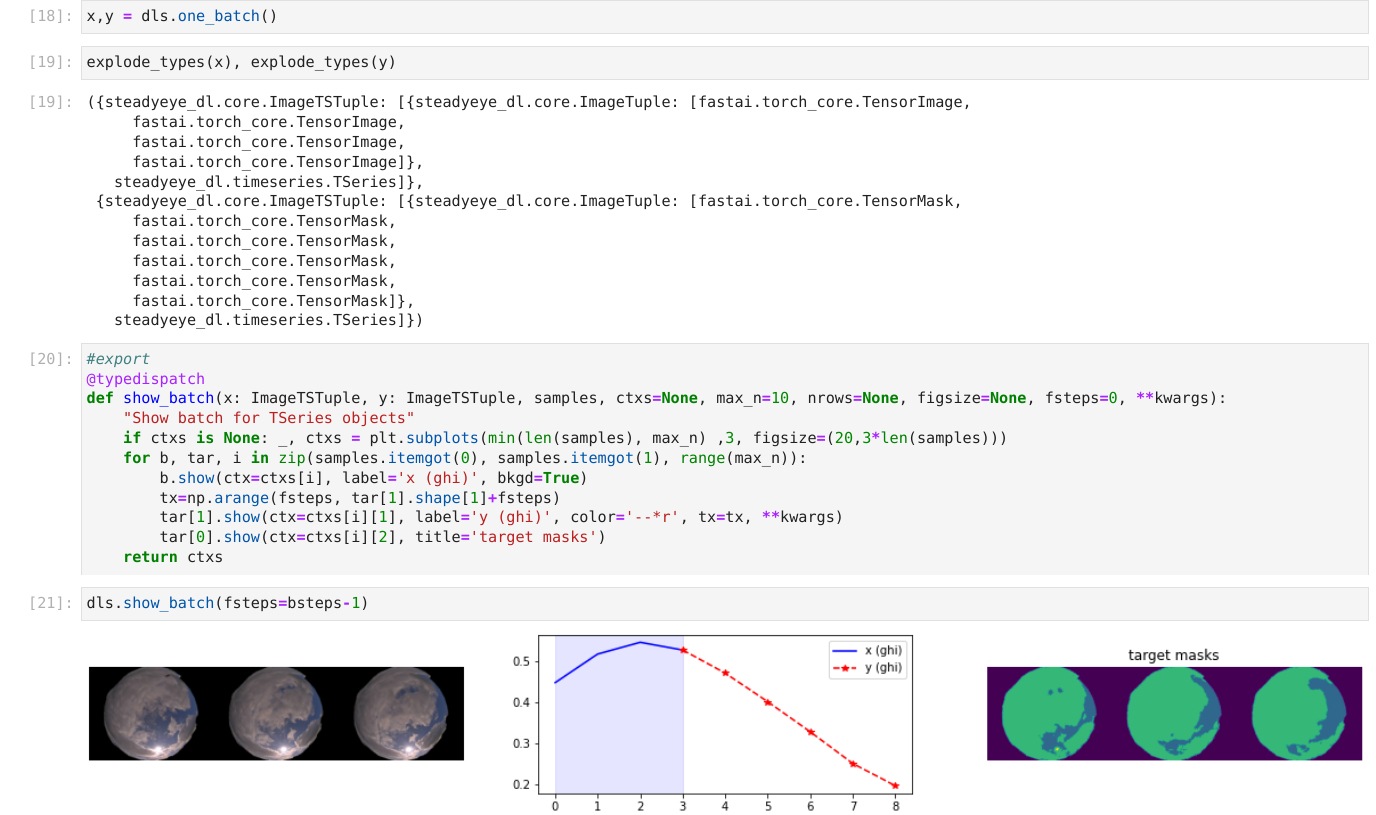
I am currently building a model that takes 2 inputs and produces 2 outputs.
My model takes as input a tuple of tuples:
input: ((img1, img2, img3), (val1, val2, val3))
output: ((img4, img5, img6), (val4, val5, val6)
Just for context, the model is a encoder-decoder of type Informer with encoder vision transformer (TimesFormer) and decoder a regular transformer.
I have been playing the last year with these types of model with fastai v2 without issues, but now that I have targets that are multimodal, I am writing very complicated tricks to make the learner work. I am probably missing something.
My model is trained with 2 losses, CE for the images and MSE for the values. So I initially tried just building a custom loss, but this does not work.
I ended up making a ugly callback:
class DualLoss(Callback):
def __init__(self, other_loss=CEntropyLossFlat()):
store_attr()
def before_batch(self):
self.yb_images, self.learn.yb = self.yb[0][0], (self.yb[0][1], )
def after_pred(self):
self.pred_images, self.learn.pred = self.pred
def after_loss(self):
self.learn.loss += self.other_loss(self.pred_images, self.yb_images)
as you can see, I hack the learner storing the predicted images away, to add the later to the loss of the learner (the MSE over the values).